
In this blog post, I’ll look at some helpful tips on troubleshooting Percona Monitoring and Management metrics.
With any luck, Percona Monitoring and Management (PMM) works for you out of the box. Sometimes, however, things go awry and you see empty or broken graphs instead of dashboards full of insights.
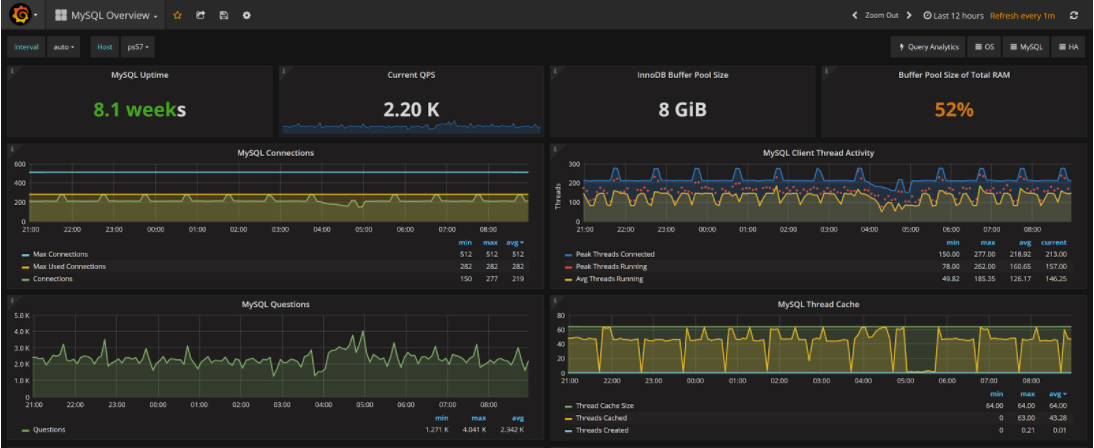
Before we go through troubleshooting steps, let’s talk about how data makes it to the Grafana dashboards in the first place. The PMM Architecture documentation page helps explain it:
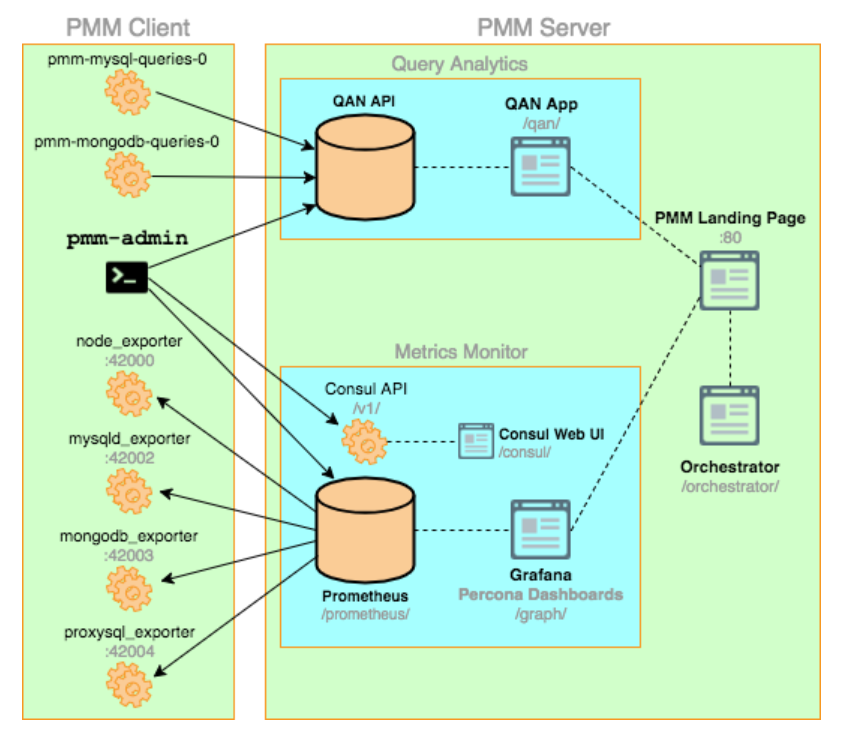
If we focus just on the “Metrics” path, we see the following requirements:
Now that we understand the basic requirements let’s look at troubleshooting the tool.
PMM Client
First, you need to check if the services are actually configured properly and running:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@rocky:/mnt/data# pmm-admin list pmm-admin 1.5.2 PMM Server | 10.11.13.140 Client Name | rocky Client Address | 10.11.13.141 Service Manager | linux-systemd -------------- ------ ----------- -------- ------------------------------------------- ------------------------------------------ SERVICE TYPE NAME LOCAL PORT RUNNING DATA SOURCE OPTIONS -------------- ------ ----------- -------- ------------------------------------------- ------------------------------------------ mysql:queries rocky - YES root:***@unix(/var/run/mysqld/mysqld.sock) query_source=slowlog, query_examples=true linux:metrics rocky 42000 YES - mysql:metrics rocky 42002 YES root:***@unix(/var/run/mysqld/mysqld.sock) |
Second, you can also instruct the PMM client to perform basic network checks. These can spot connectivity problems, time drift and other issues:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
root@rocky:/mnt/data# pmm-admin check-network PMM Network Status Server Address | 10.11.13.140 Client Address | 10.11.13.141 * System Time NTP Server (0.pool.ntp.org) | 2018-01-06 09:10:33 -0500 EST PMM Server | 2018-01-06 14:10:33 +0000 GMT PMM Client | 2018-01-06 09:10:33 -0500 EST PMM Server Time Drift | OK PMM Client Time Drift | OK PMM Client to PMM Server Time Drift | OK * Connection: Client --> Server -------------------- ------- SERVER SERVICE STATUS -------------------- ------- Consul API OK Prometheus API OK Query Analytics API OK Connection duration | 355.085µs Request duration | 938.121µs Full round trip | 1.293206ms * Connection: Client <-- Server -------------- ------ ------------------- ------- ---------- --------- SERVICE TYPE NAME REMOTE ENDPOINT STATUS HTTPS/TLS PASSWORD -------------- ------ ------------------- ------- ---------- --------- linux:metrics rocky 10.11.13.141:42000 OK YES - mysql:metrics rocky 10.11.13.141:42002 OK YES - |
If everything is working, next we can check if exporters are providing the expected data directly.
Checking Prometheus Exporters
Looking at the output from pmm-admin check-network, we can see the “REMOTE ENDPOINT”. This shows the exporter address, which you can use to access it directly in your browser:
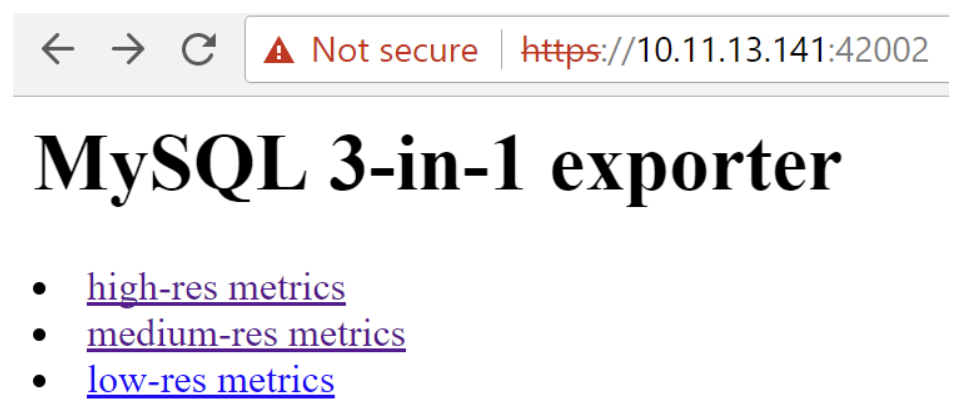
You can see MySQL Exporter has different sets of metrics for high, medium and low resolution, and you can click on them to see the provided metrics:
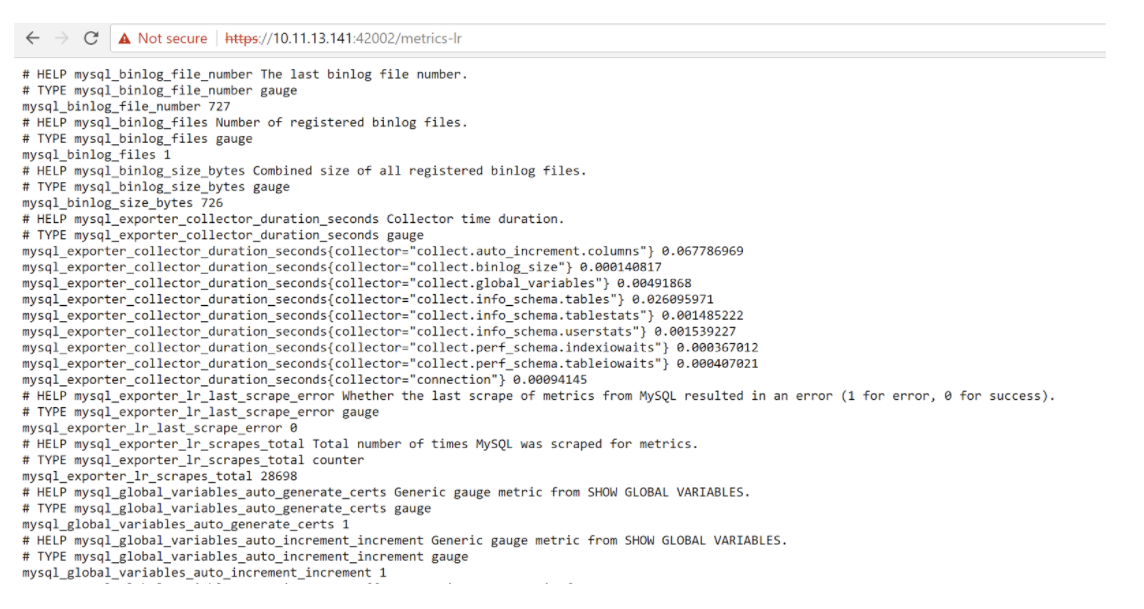
There are few possible problems you may encounter at this stage
mysql_exporter_collector_duration_seconds is a great metric that allows you to see which collectors are enabled for different resolutions, and how much time it takes for a given collector to execute. This way you can find and potentially disable collectors that are too expensive for your environment.
Let’s look at some more advanced ways to troubleshoot exporters.
Looking at ProcessList
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
root@rocky:/mnt/data# ps aux | grep mysqld_exporter root 1697 0.0 0.0 4508 848 ? Ss 2017 0:00 /bin/sh -c /usr/local/percona/pmm-client/mysqld_exporter -collect.auto_increment.columns=true -collect.binlog_size=true -collect.global_status=true -collect.global_variables=true -collect.info_schema.innodb_metrics=true -collect.info_schema.processlist=true -collect.info_schema.query_response_time=true -collect.info_schema.tables=true -collect.info_schema.tablestats=true -collect.info_schema.userstats=true -collect.perf_schema.eventswaits=true -collect.perf_schema.file_events=true -collect.perf_schema.indexiowaits=true -collect.perf_schema.tableiowaits=true -collect.perf_schema.tablelocks=true -collect.slave_status=true -web.listen-address=10.11.13.141:42002 -web.auth-file=/usr/local/percona/pmm-client/pmm.yml -web.ssl-cert-file=/usr/local/percona/pmm-client/server.crt -web.ssl-key-file=/usr/local/percona/pmm-client/server.key >> /var/log/pmm-mysql-metrics-42002.log 2>&1 |
This shows us that the exporter is running, as well as specific command line options that were used to start it (which collectors were enabled, for example).
Checking out Log File
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
root@rocky:/mnt/data# tail /var/log/pmm-mysql-metrics-42002.log time="2018-01-05T18:19:10-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" time="2018-01-05T18:19:11-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" time="2018-01-05T18:19:12-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:492" time="2018-01-05T18:19:12-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" time="2018-01-05T18:19:12-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:616" time="2018-01-05T18:19:13-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" time="2018-01-05T18:19:14-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" time="2018-01-05T18:19:15-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" time="2018-01-05T18:19:16-05:00" level=error msg="Error pinging mysqld: dial unix /var/run/mysqld/mysqld.sock: connect: no such file or directory" source="mysqld_exporter.go:442" 2018/01/06 09:10:33 http: TLS handshake error from 10.11.13.141:56154: tls: first record does not look like a TLS handshake |
If you have problems such as authentication or permission errors, you will see them in the log file. In the example above, we can see the exporter reporting many connection errors (the MySQL Server was down).
Prometheus Server
Next, we can take a look at the Prometheus Server. It is exposed in PMM Server at /prometheus path. We can go to Status->Targets to see which Targets are configured and if they are working: correctly
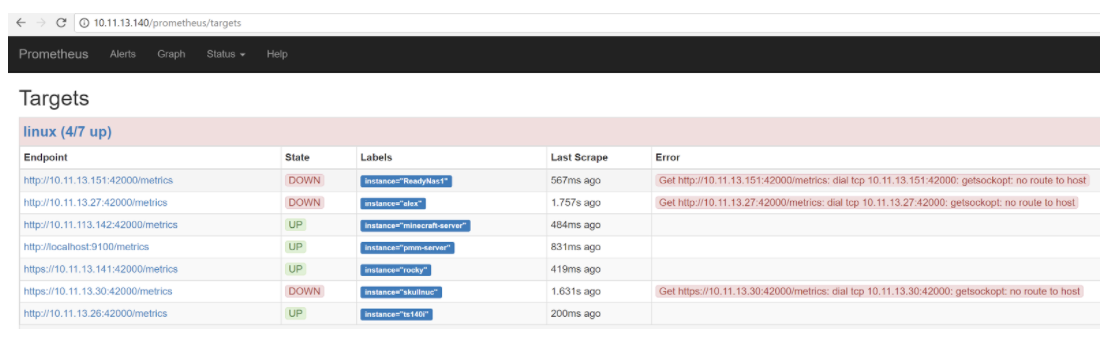
In this example, some hosts are scraped successfully while others are not. As you can see I have some hosts that are down, so scraping fails with “no route to host”. You might also see problems caused by firewall configurations and other reasons.
The next area to check, especially if you have gaps in your graph, is if your Prometheus server has enough resources to ingest all the data reported in your environment. Percona Monitoring and Management ships with the Prometheus dashboard to help to answer this question (see demo).
There is a lot of information in this dashboard, but one of the most important areas you should check is if there is enough CPU available for Prometheus:
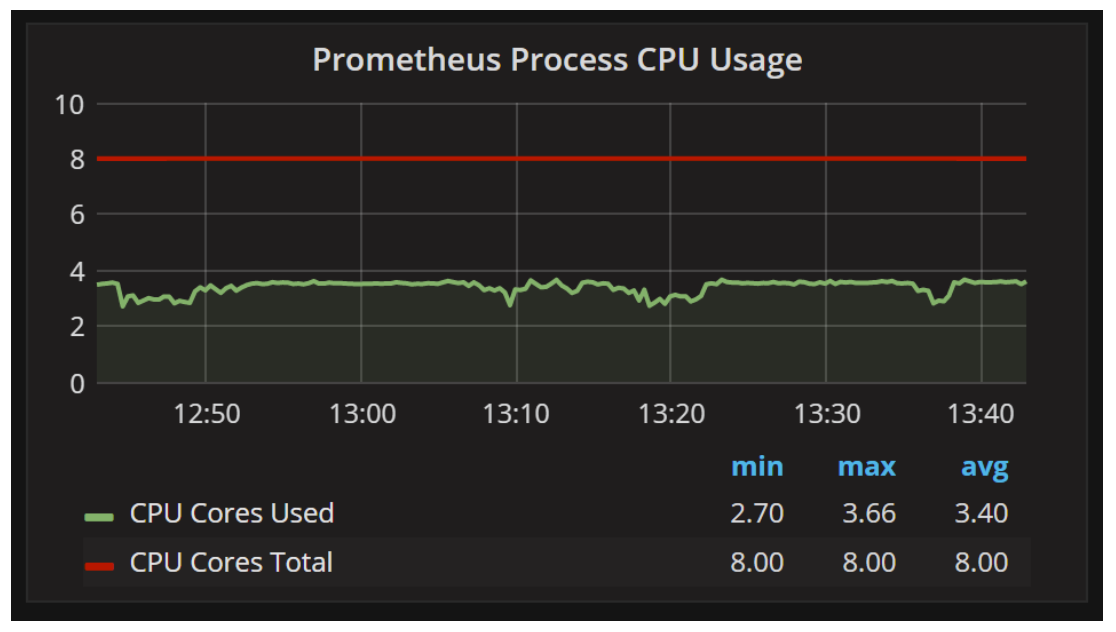
The most typical problem to have with Prometheus is getting into “Rushed Mode” and dropping some of the metrics data:

Not using enough memory to buffer metrics is another issue, which is shown as “Configured Target Storage Heap Size” on the graph:

Values of around 40% of total memory size often make sense. The PMM FAQ details how to tune this setting.
If the amount of memory is already configured correctly, you can explore upgrading to a more powerful instance size or reducing the number of metrics Prometheus ingests. This can be done either by adjusting Metrics Resolution (as explained in FAQ) or disabling some of the collectors (Manual).
You might wonder which collectors generate the most data? This information is available on the same Prometheus Dashboard:
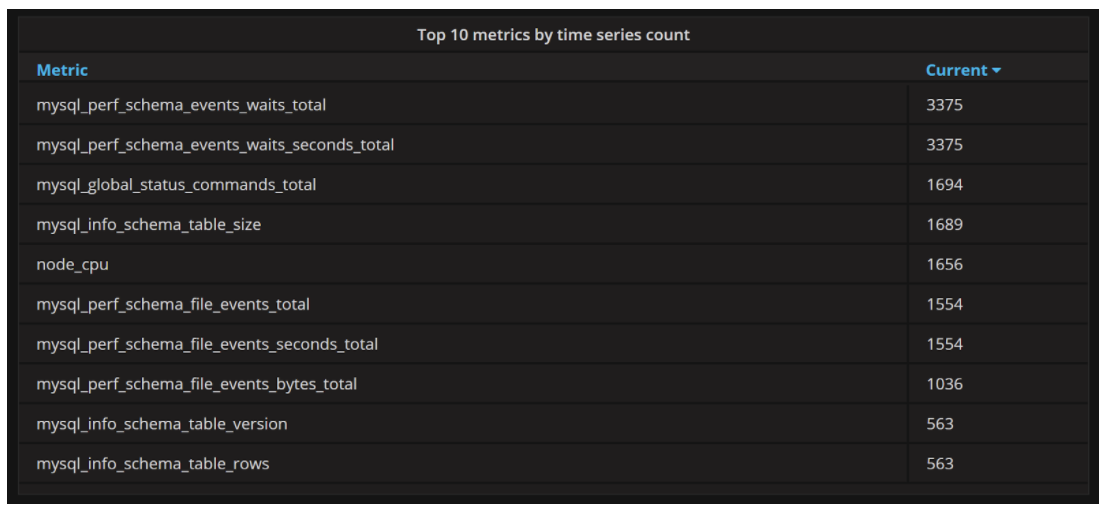
While these aren’t not exact values, they correlate very well with what the load collectors generate. In this case, for example, we can see that the Performance Schema is responsible for a large amount of time series data. As such, disabling its collectors can reduce the Prometheus load substantially.
Hopefully, these troubleshooting steps were helpful to you in diagnosing PMM’s metrics capture. In a later blog post, I will write about how to diagnose problems with Query Analytics (Demo).
You May Also Like
DigitalOcean is a user-friendly and inexpensive option for hosting PMM. You can start with the monitoring of a simple infrastructure before implementing PMM to monitor your production environment. Our blog, Deploying PMM on DigitalOcean, guides you through the set-up process, from preparing a DigitalOcean instance to creating a container for persistent PMM data. Read our blog for more details.
Early database architecture decisions can negatively affect your bottom line if thought isn’t given to your long-term business goals. An enduring infrastructure requires regular reviews and a regiment of proactive activities. Download our white paper to learn more about how solid database planning can future-proof your business.





I have it working, but I’d like to keep the dashboard open 24x-to-infinity, but the login gets timed-out after what seems like a random amount of time. I don’t think pmm is triggering the logout, so I’ve been looking for nginx directive that may be causing the termination.
Am I going in the right direction?
Have you solved this issue?