
In this blog, we’ll look at group replication and how it deals with flow control (FC) and replication lag.
In the last few months, we had two main actors in the MySQL ecosystem: ProxySQL and Group-Replication (with the evolution to InnoDB Cluster).
While I have extensively covered the first, my last serious work on Group Replication dates back to some lab version years past.
Given that Oracle decided to declare it GA, and Percona’s decision to provide some level of Group Replication support, I decided it was time for me to take a look at it again.
We’ve seen a lot of coverage already too many Group Replication topics. There are articles about Group Replication and performance, Group Replication and basic functionalities (or lack of it like automatic node provisioning), Group Replication and ProxySQL, and so on.
But one question kept coming up over and over in my mind. If Group Replication and InnoDB Cluster have to work as an alternative to other (virtually) synchronous replication mechanisms, what changes do our customers need to consider if they want to move from one to the other?
Solutions using Galera (like Percona XtraDB Cluster) must take into account a central concept: clusters are data-centric. What matters is the data and the data state. Both must be the same on each node at any given time (commit/apply). To guarantee this, Percona XtraDB Cluster (and other solutions) use a set of data validation and Flow Control processes that work to the ensure a consistent cluster data set on each node.
The upshot of this principle is that an application can query ANY node in a Percona XtraDB Cluster and get the same data, or write to ANY node and know that the data is visible everywhere in the cluster at (virtually) the same time.
Last but not least, inconsistent nodes should be excluded and either rebuild or fixed before rejoining the cluster.
If you think about it, this is very useful. Guaranteeing consistency across nodes allows you to transparently split write/read operations, failover from one node to another with very few issues, and more.
When I conceived of this blog on Group Replication (or InnoDB Cluster), I put myself in the customer shoes. I asked myself: “Aside from all the other things we know (see above), what is the real impact of moving from Percona XtraDB Cluster to Group Replication/InnoDB Cluster for my application? Since Group Replication still (basically) uses replication with binlogs and relaylog, is there also a Flow Control mechanism?” An alarm bell started to ring in my mind.
My answer is: “Let’s do a proof of concept (PoC), and see what is really going on.”
I setup a simple set of servers using Group Replication with a very basic application performing writes on a single writer node, and (eventually) reads on the other nodes.
You can find the schema definition here. Mainly I used the four tables from my windmills test suite — nothing special or specifically designed for Group Replication. I’ve used this test a lot for Percona XtraDB Cluster in the past, so was a perfect fit.
The application will do very simple work, and I wanted to test four main cases:
As you can see, a pretty simple set of operations. Then I decided to test it using the following four conditions on the servers:
Again nothing weird or strange from my point of view. I used four nodes:
Finally, I had to be sure I measured the lag in a way that allowed me to reference it consistently on all nodes.
I think we can safely say that the incoming GTID (last_ Received_transaction_set from replication_connection_status) is definitely the last change applied to the master that the slave node knows about. More recent changes could have occurred, but network delay can prevent them from being “received.” The other point of reference is GTID_EXECUTED, which refers to the latest GTID processed on the node itself.
The closest query that can track the distance will be:
|
1 |
select @last_exec:=SUBSTRING_INDEX(SUBSTRING_INDEX(SUBSTRING_INDEX( @@global.GTID_EXECUTED,':',-2),':',1),'-',-1) last_executed;select @last_rec:=SUBSTRING_INDEX(SUBSTRING_INDEX(SUBSTRING_INDEX( Received_transaction_set,':',-2),':',1),'-',-1) last_received FROM performance_schema.replication_connection_status WHERE Channel_name = 'group_replication_applier'; select (@last_rec - @last_exec) as real_lag |
Or in the case of a single worker:
|
1 |
select @last_exec:=SUBSTRING_INDEX(SUBSTRING_INDEX( @@global.GTID_EXECUTED,':',-1),'-',-1) last_executed;select @last_rec:=SUBSTRING_INDEX(SUBSTRING_INDEX(Received_transaction_set,':',-1),'-',-1) last_received FROM performance_schema.replication_connection_status WHERE Channel_name = 'group_replication_applier'; select (@last_rec - @last_exec) as real_lag; |
The result will be something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
+---------------+ | last_executed | +---------------+ | 23607 | +---------------+ +---------------+ | last_received | +---------------+ | 23607 | +---------------+ +----------+ | real_lag | +----------+ | 0 | +----------+ |
The whole set of tests can be found here, with all the commands you need to run the application (you can find it here) and replicate the tests. I will focus on the results (otherwise this blog post would be far too long), but I invite you to see the details.
Using the raw data from the tests (Excel spreadsheet available here), I was interested in identifying if and how the Writer is affected by the use of Group Replication and flow control.
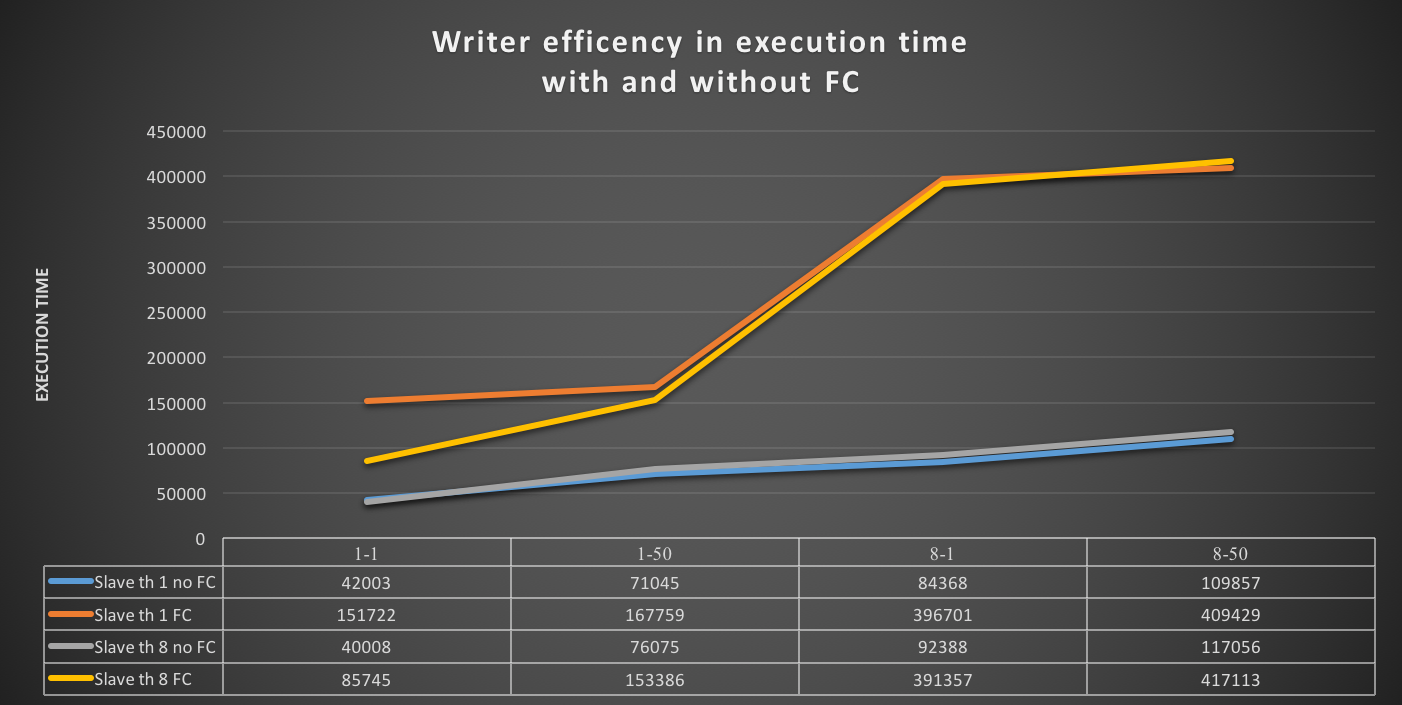
Reviewing the graph, we can see that the Writer has a linear increase in the execution time (when using default flow control) that matches the increase in the load. Nothing there is concerning, and all-in-all we see what is expected if the load is light. The volume of rows at the end justifies the execution time.
It’s a different scenario if we use flow control. The execution time increases significantly in both cases (single worker/multiple workers). In the worst case (eight threads, 50 inserts batch) it becomes four times higher than the same load without flow control.
What happens to the inserted rows? In the application, I traced the rows inserted/sec. It is easy to see what is going on there:
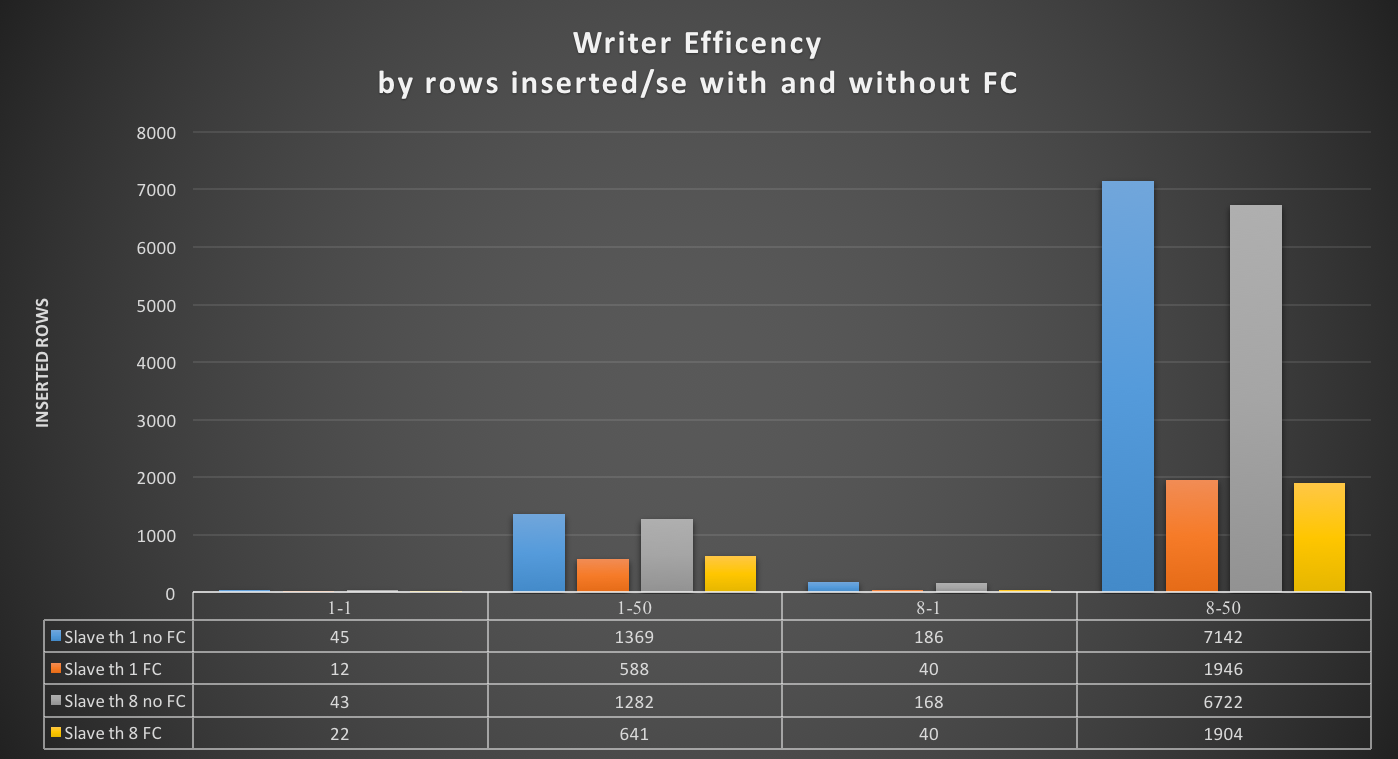
We can see that the Writer with flow control activated inserts less than a third of the rows it processes without flow control.
We can definitely say that flow control has a significant impact on the Writer performance. To clarify, let’s look at this graph:
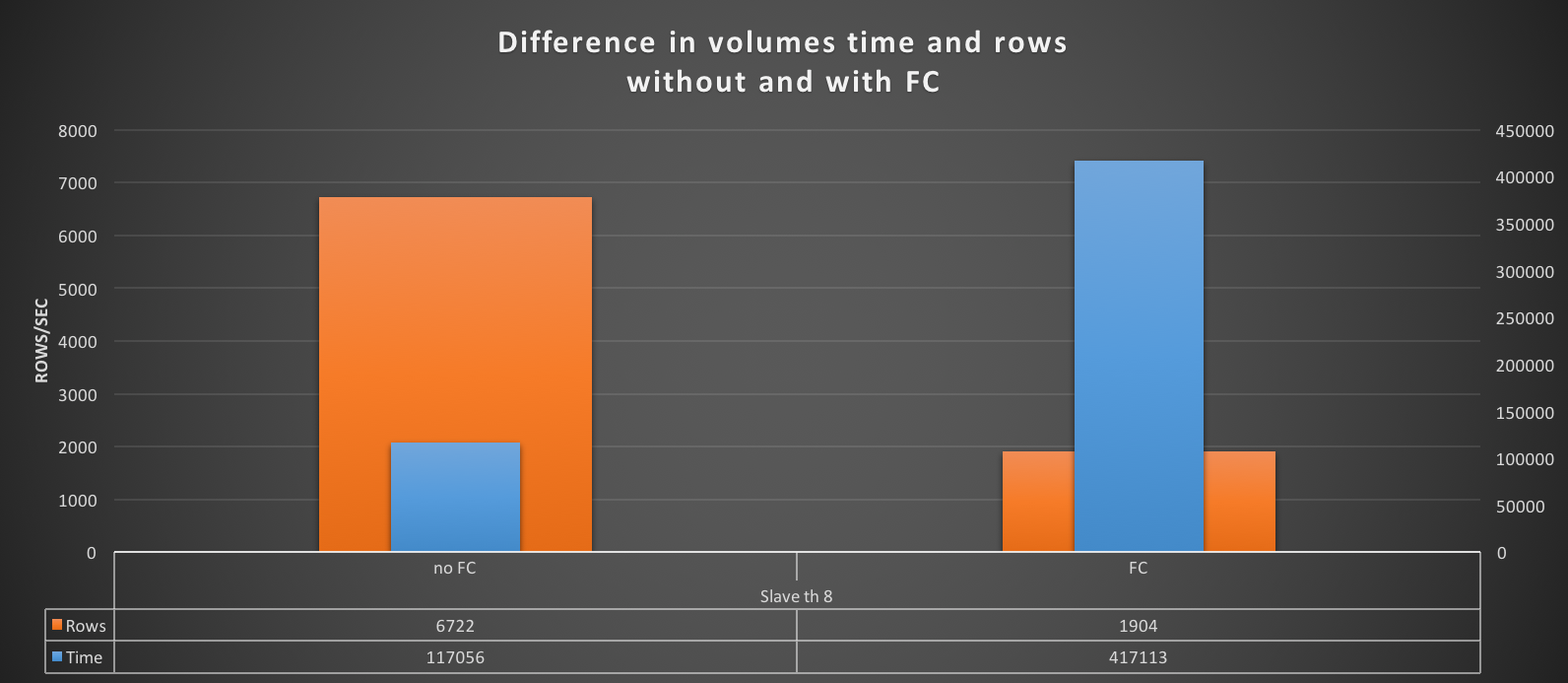
Without flow control, the Writer processes a high volume of rows in a limited amount of time (results from the test of eight workers, eight threads, 50 insert batch). With flow control, the situation changes drastically. The Writer takes a long time processing a significantly smaller number of rows/sec. In short, performance drops significantly.
But hey, I’m OK with that if it means having a consistent data-set cross all nodes. In the end, Percona XtraDB Cluster and similar solutions pay a significant performance price match the data-centric principle.
Let’s see what happen on the other nodes.
Well, this scenario is not so good:
When NOT using flow control, the nodes lag behind the writer significantly. Remember that by default flow control in Group Replication is set to 25000 entries (I mean 25K of entries!!!).
What happens is that as soon as I put some salt (see load) on the Writer, the slave nodes start to lag. When using the default single worker, that will have a significant impact. While using multiple workers, we see that the lag happens mainly on the node(s) with minimal (10ms) network latency. The sad thing is that is not really going down with respect to the single thread worker, indicating that the simple minimal latency of 10ms is enough to affect replication.
Time to activate the flow control and have no lag:
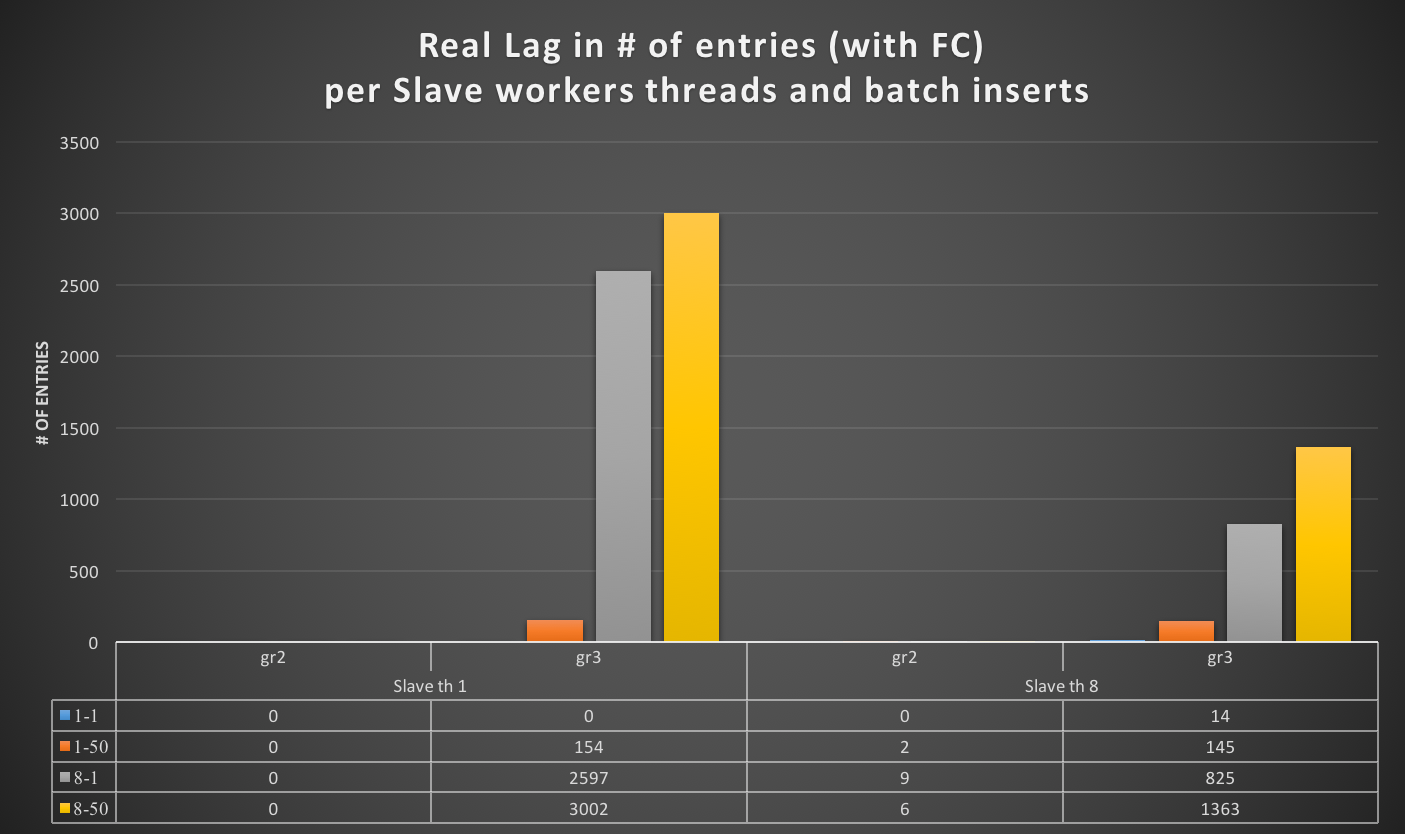
Unfortunately, this is not the case. As we can see, the lag of single worker remains high for Gr2 (154 entries). While using multiple workers, the Gr3/4 nodes can perform much better, with significantly less lag (but still high at ~1k entries).
It is important to remember that at this time the Writer is processing one-third or less of the rows it is normally able to. It is also important to note that I set 25 to the entry limit in flow control, and the Gr3 (and Gr4) nodes are still lagging more than 1K entries behind.
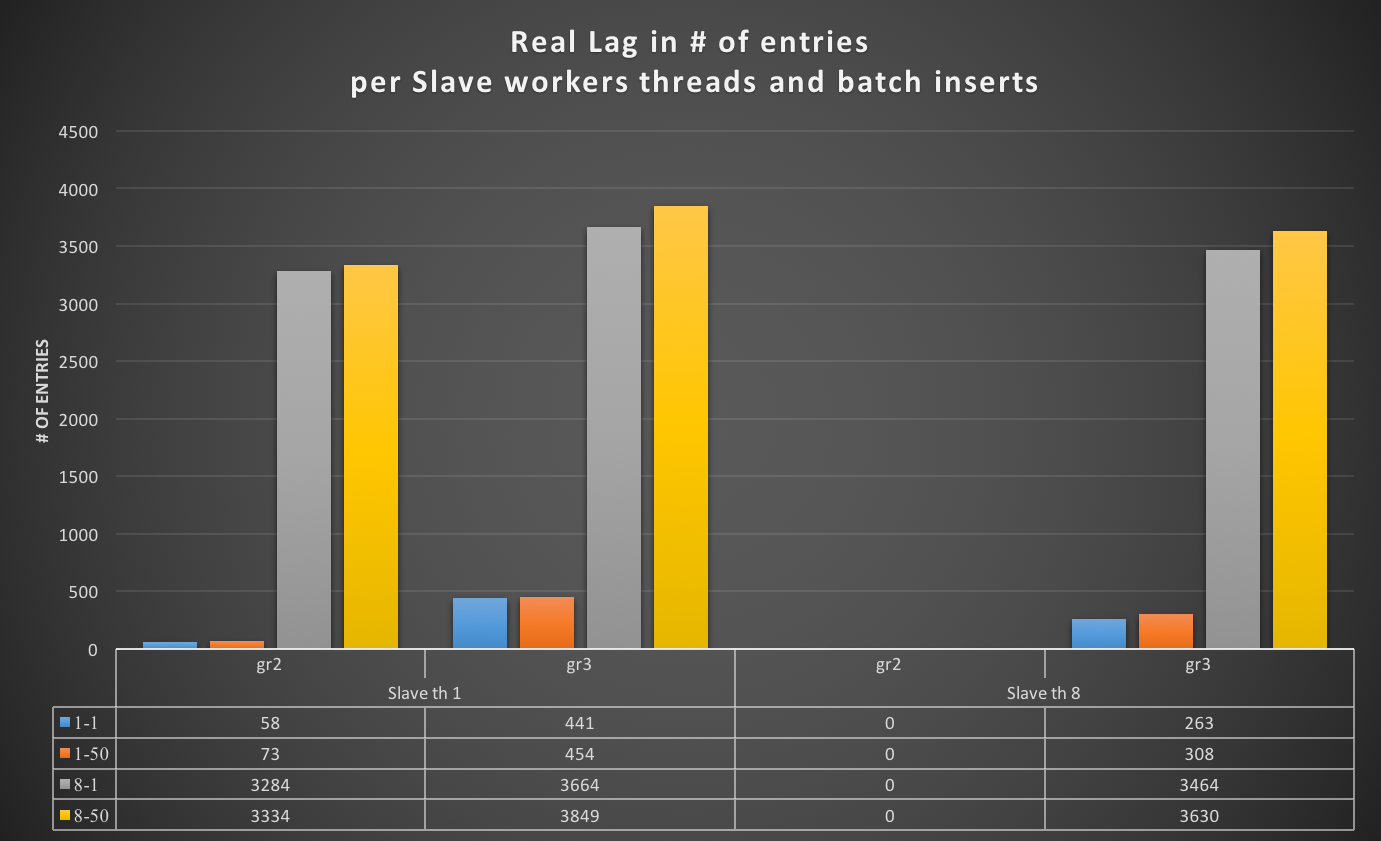
To clarify, let check the two graphs below:
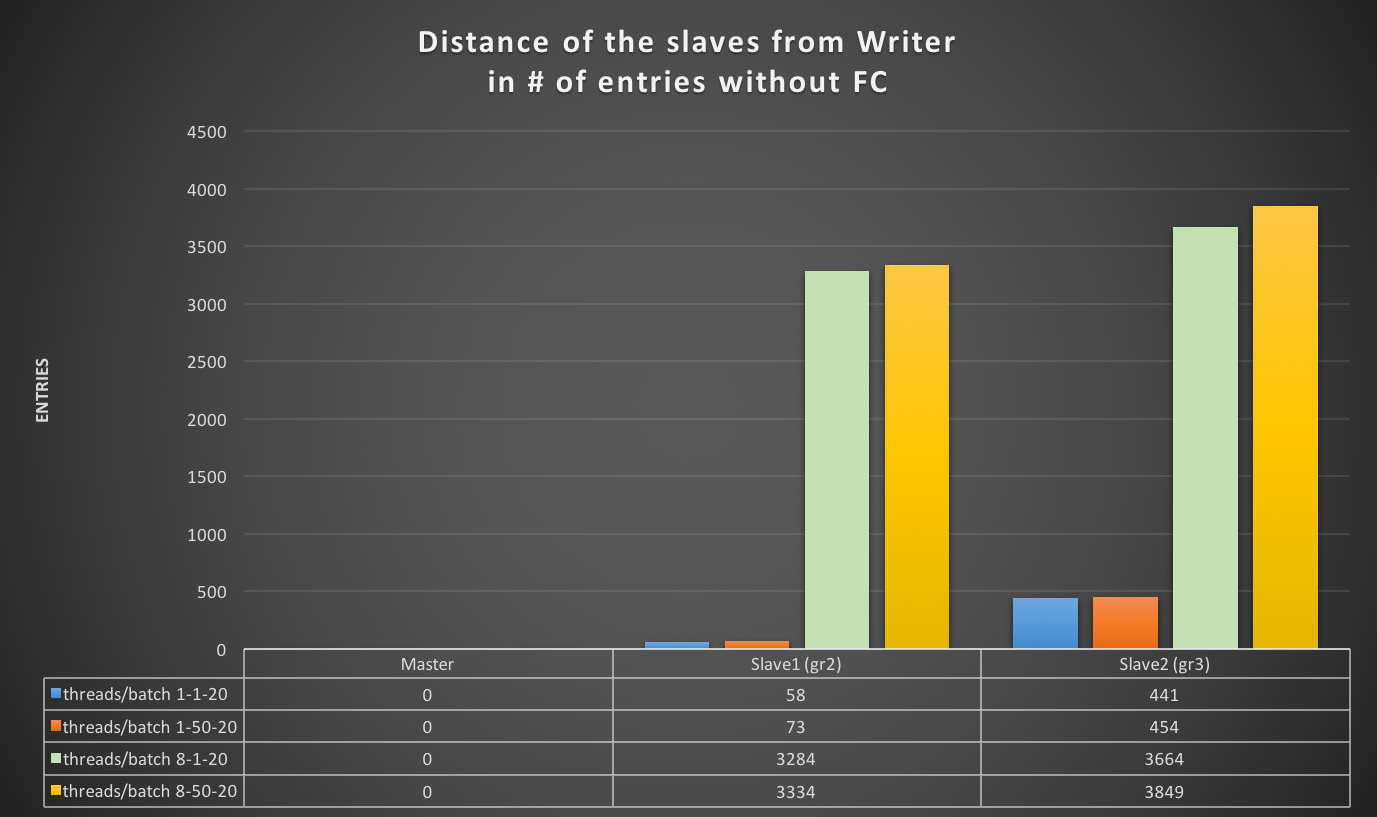
Using the Writer (Master) as a baseline in entry #N, without flow control, the nodes (slaves) using Group Replication start to significantly lag behind the writer (even with a light load).
The distance in this PoC ranged from very minimal (with 58 entries), up to much higher loads (3849 entries):
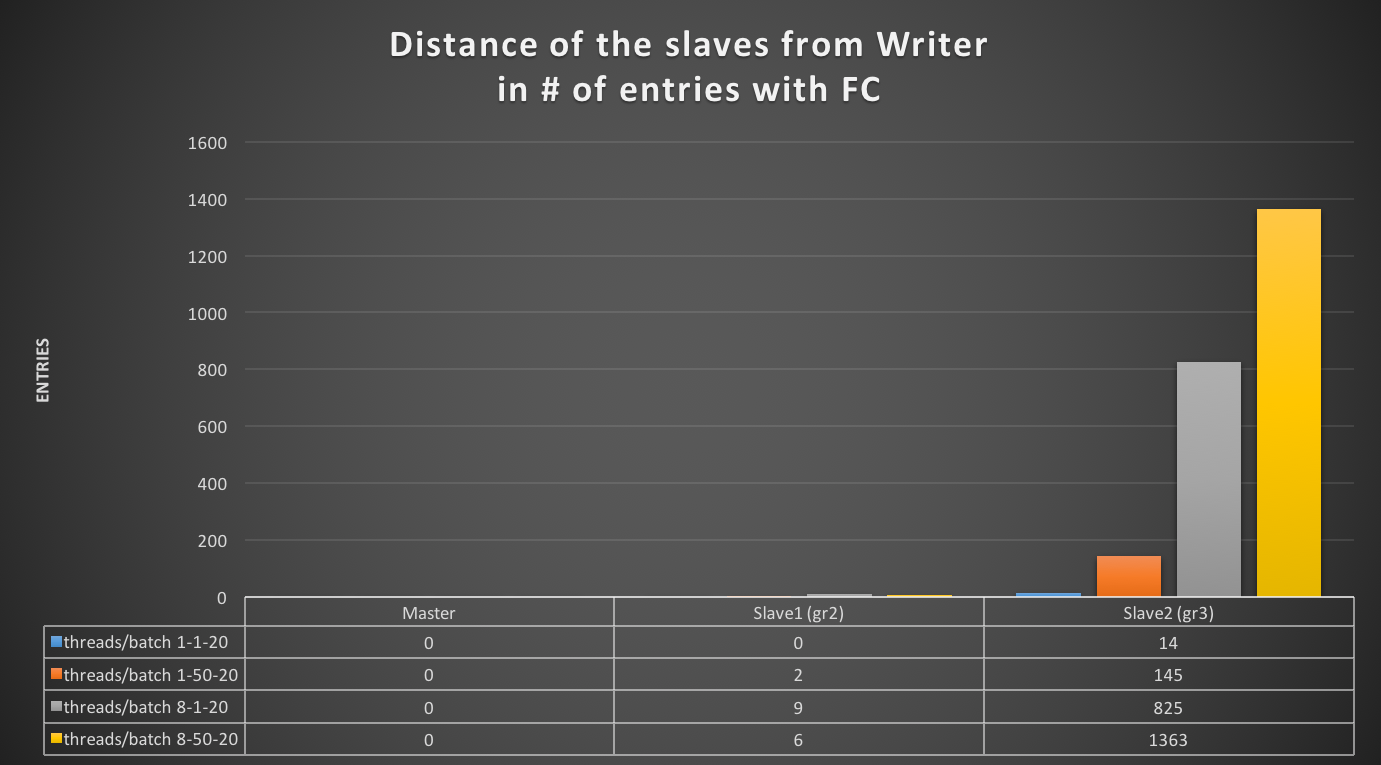
Using flow control, the Writer (Master) diverges less, as expected. If it has a significant drop in performance (one-third or less), the nodes still lag. The worst-case is up to 1363 entries.
I need to underline here that we have no further way (that I am aware of, anyway) to tune the lag and prevent it from happening.
This means an application cannot transparently split writes/reads and expect consistency. The gap is too high.
I used Percona Monitoring and Management (PMM) to keep an eye on the nodes while doing the tests. One of the graphs really showed me that Group Replication still has some “limits” as the replication mechanism for a cluster:
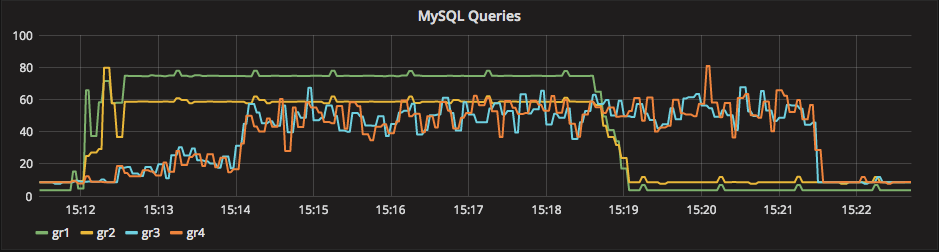
This graph shows the MySQL queries executed on all the four nodes, in the testing using 8-50 threads-batch and flow control.
As you can see, the Gr1 (Writer) is the first one to take off, followed by Gr2. Nodes Gr3 and Gr4 require a bit more, given the binlog transmission (and 10ms delay). Once the data is there, they match (inconsistently) the Gr2 node. This is an effect of flow control asking the Master to slow down. But as previously seen, the nodes will never match the Writer. When the load test is over, the nodes continue to process the queue for additional ~130 seconds. Considering that the whole load takes 420 seconds on the Writer, this means that one-third of the total time on the Writer is spent syncing the slave AFTERWARDS.
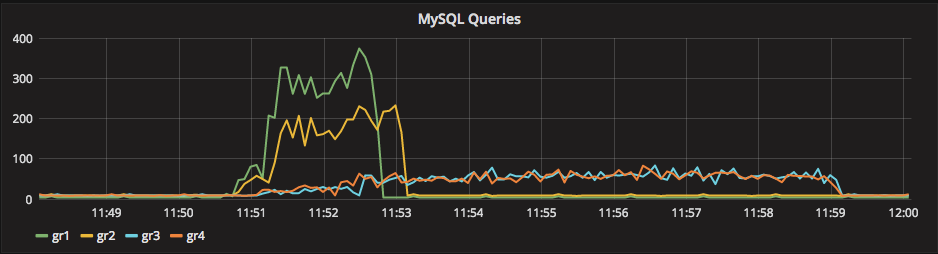
The above graph shows the same test without flow control. It is interesting to see how the Writer moved above 300 queries/sec, while G2 stayed around 200 and Gr3/4 far below. The Writer was able to process the whole load in ~120 seconds instead 420, while Gr3/4 continue to process the load for an additional ~360 seconds.
This means that without flow control set, the nodes lag around 360 seconds behind the Master. With flow control set to 25, they lag 130 seconds.
This is a significant gap.
Going back to the reason why I was started this PoC, it looks like my application(s) are not a good fit for Group Replication given that I have set Percona XtraDB Cluster to scale out the reads and efficiently move my writer to another when I need to.
Group Replication is still based on asynchronous replication (as my colleague Kenny said). It makes sense in many other cases, but it doesn’t compare to solutions based on virtually synchronous replication. It still requires a lot of refinement.
On the other hand, for applications that can afford to have a significant gap between writers and readers it is probably fine. But … doesn’t standard replication already cover that?
Reviewing the Oracle documentations (https://dev.mysql.com/doc/refman/5.7/en/group-replication-background.html), I can see why Group Replication as part of the InnoDB cluster could help improve high availability when compared to standard replication.
But I also think it is important to understand that Group Replication (and derived solutions like InnoDB cluster) are not comparable or a replacement for data-centric solutions as Percona XtraDB Cluster. At least up to now.
Good MySQL to everyone.
Resources
RELATED POSTS





Hi,
This was a very good explanation with detailed pictorial representation.
I wanted to test the same in our environment with different memory and hardware on mysql commercial.
I have tried to create this scenario using sysbench but i am unable to test this scenario.
For this testing windmills test suite is used.
Do we have any blog or location where we can find details about this windmills test deployment and running.
if so, let us know so that it will be helpful to test this in our environment.
Thanks
Vinay Gurram
If Group Replication is based on Paxos algorithm, per documentation, then some nodes can fall behind and that’s the positive attribute of it, i.e. the system won’t degrade to the slowest node. As long as the consensus-number of nodes is in sync, HA promise is preserved.
Regardless, I’m also seeing performance of GR sub-par to WSREP like Galera so I’m a bit disappointed. I tested using Community MySQL 5.7.25 vs MariaDB 10.3 (for me GR is about 2.5x slower in exactly the same setup).