
In this blog post, we’ll look at how ProxySQL and mirroring go together.
Let me be clear: I love ProxySQL, and I think it is a great component for expanding architecture flexibility and high availability. But not all that shines is gold! In this post, I want to correctly set some expectations, and avoid selling carbon for gold (carbon has it’s own uses, while gold has others).
First of all, we need to cover the basics of how ProxySQL manages traffic dispatch (I don’t want to call it mirroring, and I’ll explain further below).
ProxySQL receives a connection from the application, and through it we can have a simple SELECT or a more complex transaction. ProxySQL gets each query, passes them to the Query Processor, processes them, identifies if a query is mirrored, duplicates the whole MySQL session ProxySQL internal object and associates it to a mirror queue (which refer to a mirror threads pool). If the pool is free (has an available active slot in the concurrent active threads set) then the query is processed right away. If not, it will stay in the queue. If the queue is full, the query is lost.
Whatever is returned from the query goes to /dev/null, and as such no result set is passed back to the client.
The whole process is not free for a server. If you check the CPU utilization, you will see that the “mirroring” in ProxySQL actually doubles the CPU utilization. This means that the traffic on server A is impacted because of resource contention.
Summarizing, ProxySQL will:
This point, coupled with the expectations I mention in the reasoning at the end of this article, it is quite clear to me that at the moment we cannot consider ProxySQL as a valid mechanism to duplicate a consistent load from server A to server B.
Personally, I don’t think that the ProxySQL development team (Rene :D) should waste time on fixing this issue, as there are so many other things to cover and improve on in ProxySQL.
After working extensively with ProxySQL, and doing a deep QA on mirroring, I think that either we keep it as basic blind traffic dispatcher. Otherwise, a full re-conceptualization is required. But once we have clarified that, ProxySQL “traffic dispatch” (still don’t want to call it mirroring) remains a very interesting feature that can have useful applications – especially since it is easy to setup.
The following test results should help set the correct expectations.
The tests were simple: load data in a Percona XtraDB Cluster and use ProxySQL to replicate the load on a MySQL master-slave environment.
Why did I choose to give ProxySQL a higher volume of resources? I knew in advance I could need to play a bit with a couple of settings that required more memory and CPU cycles. I wanted to be sure I didn’t get any problems from ProxySQL in relation to CPU and memory.
The application that I was using to add load is a Java application I develop to perform my tests. The app is at https://github.com/Tusamarco/blogs/blob/master/stresstool_base_app.tar.gz, and the whole set I used to do the tests are here: https://github.com/Tusamarco/blogs/tree/master/proxymirror.
I used four different tables:
|
1 2 3 4 5 6 7 |
+------------------+ | Tables_in_mirror | +------------------+ | mirtabAUTOINC | | mirtabMID | | mirtabMIDPart | | mirtabMIDUUID | |
Ok so let start. Note that the meaningful tests are the ones below. For the whole set, refer to the whole set package. First setup ProxySQL:
First setup ProxySQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
delete from mysql_servers where hostgroup_id in (500,501,700,701); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.5',500,3306,60000,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.5',501,3306,100,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.21',501,3306,20000,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.231',501,3306,20000,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.7',700,3306,1,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.7',701,3306,1,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.25',701,3306,1,400); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.0.43',701,3306,1,400); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; delete from mysql_users where username='load_RW'; insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('load_RW','test',1,500,'test',1); LOAD MYSQL USERS TO RUNTIME;SAVE MYSQL USERS TO DISK; delete from mysql_query_rules where rule_id=202; insert into mysql_query_rules (rule_id,username,destination_hostgroup,mirror_hostgroup,active,retries,apply) values(202,'load_RW',500,700,1,3,1); LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK; |
The first test is mainly a simple functional test during which I insert records using one single thread in Percona XtraDB Cluster and MySQL. No surprise, here I have 3000 loops and at the end of the test I have 3000 records on both platforms.
To have a baseline we can see that the ProxySQL CPU utilization is quite low:
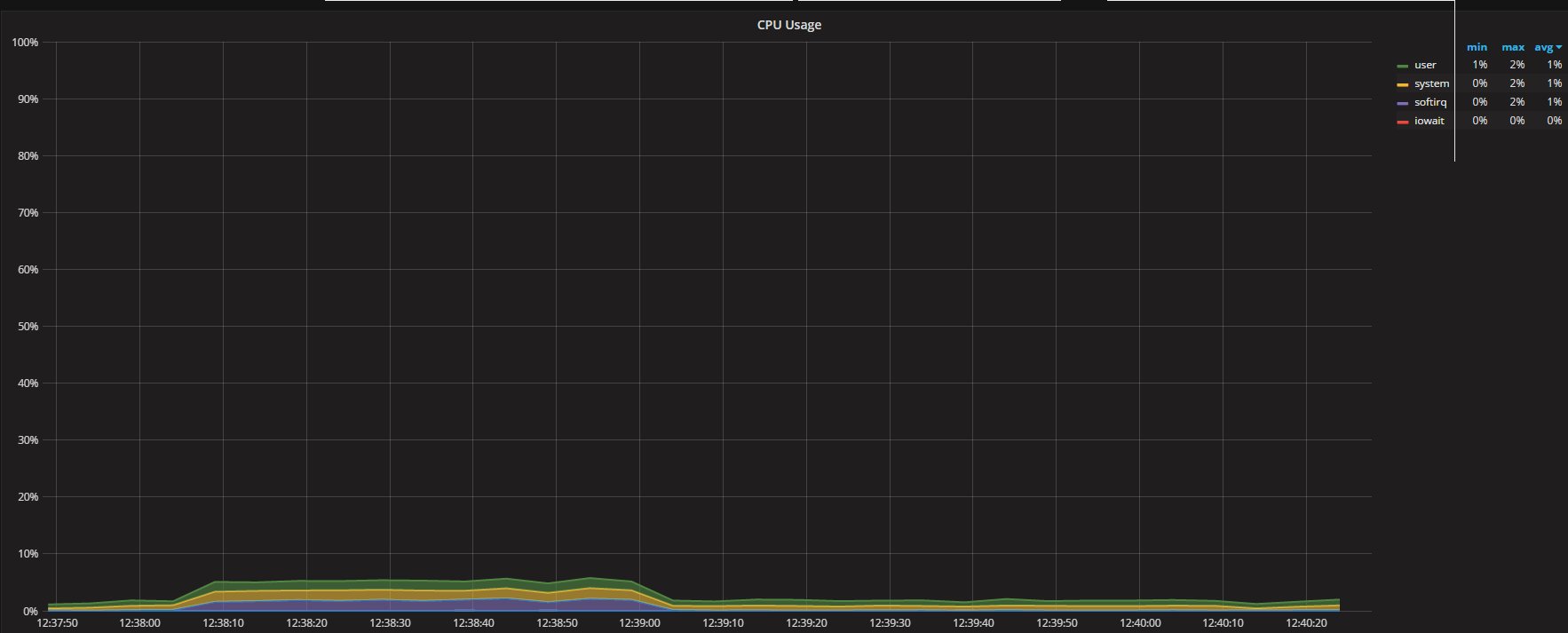
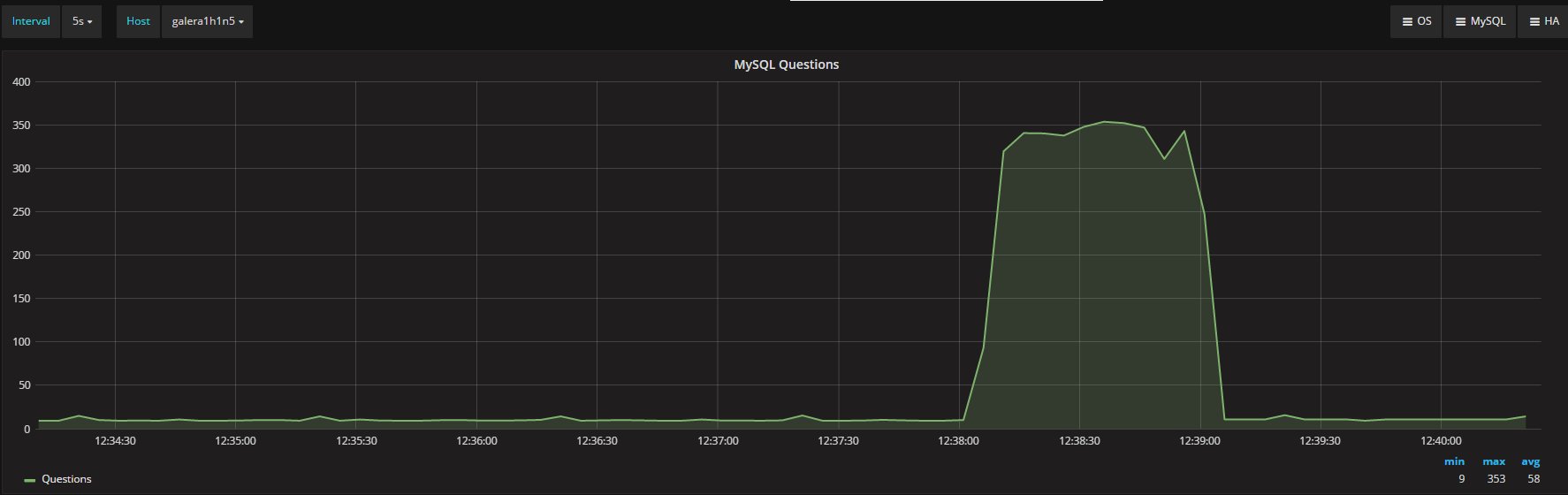
At the same time, the number of “questions” against Percona XtraDB Cluster and MySQL very similar:
Percona XtraDB Cluster
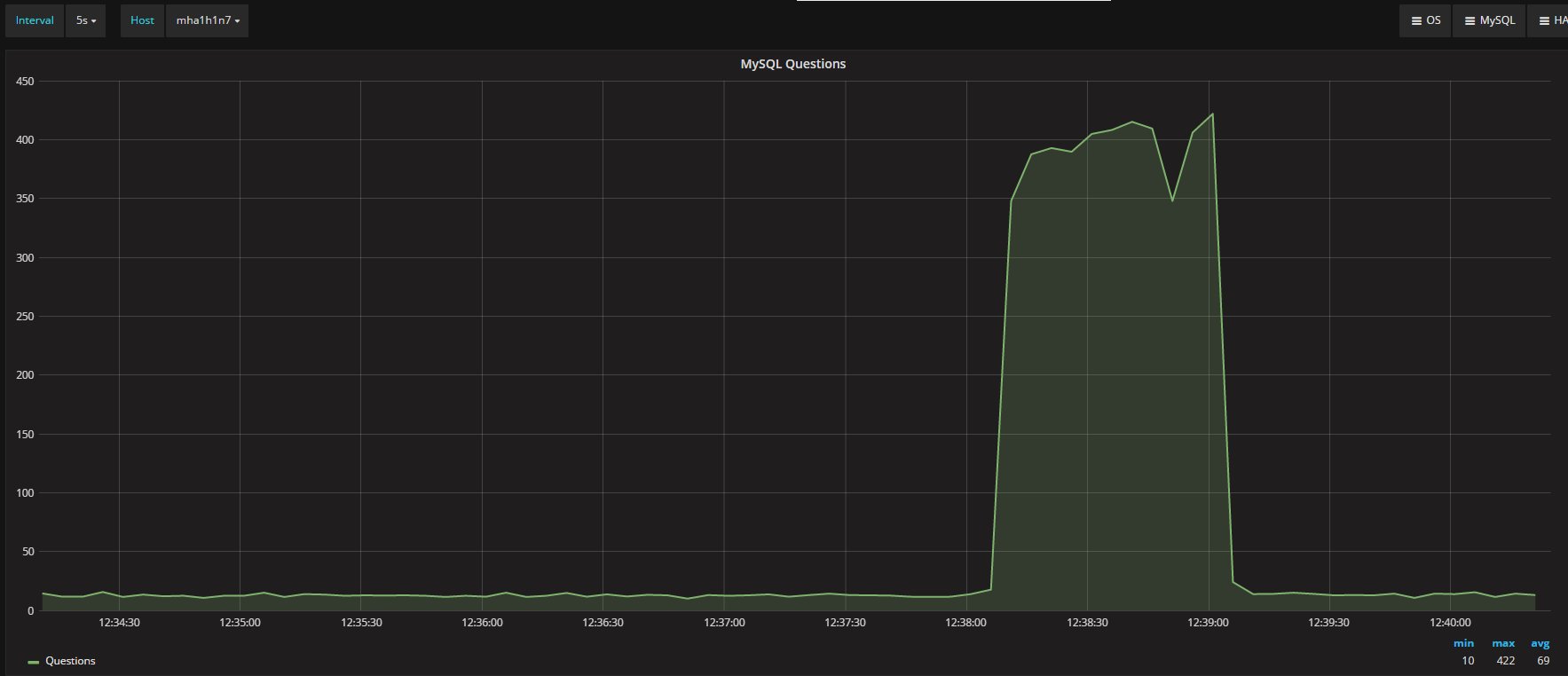
MySQL
The other two metrics we want to keep an eye on are Mirror_concurrency and Mirror_queue_length. These two refer respectively to mysql-mirror_max_concurrency and mysql-mirror_max_queue_length:
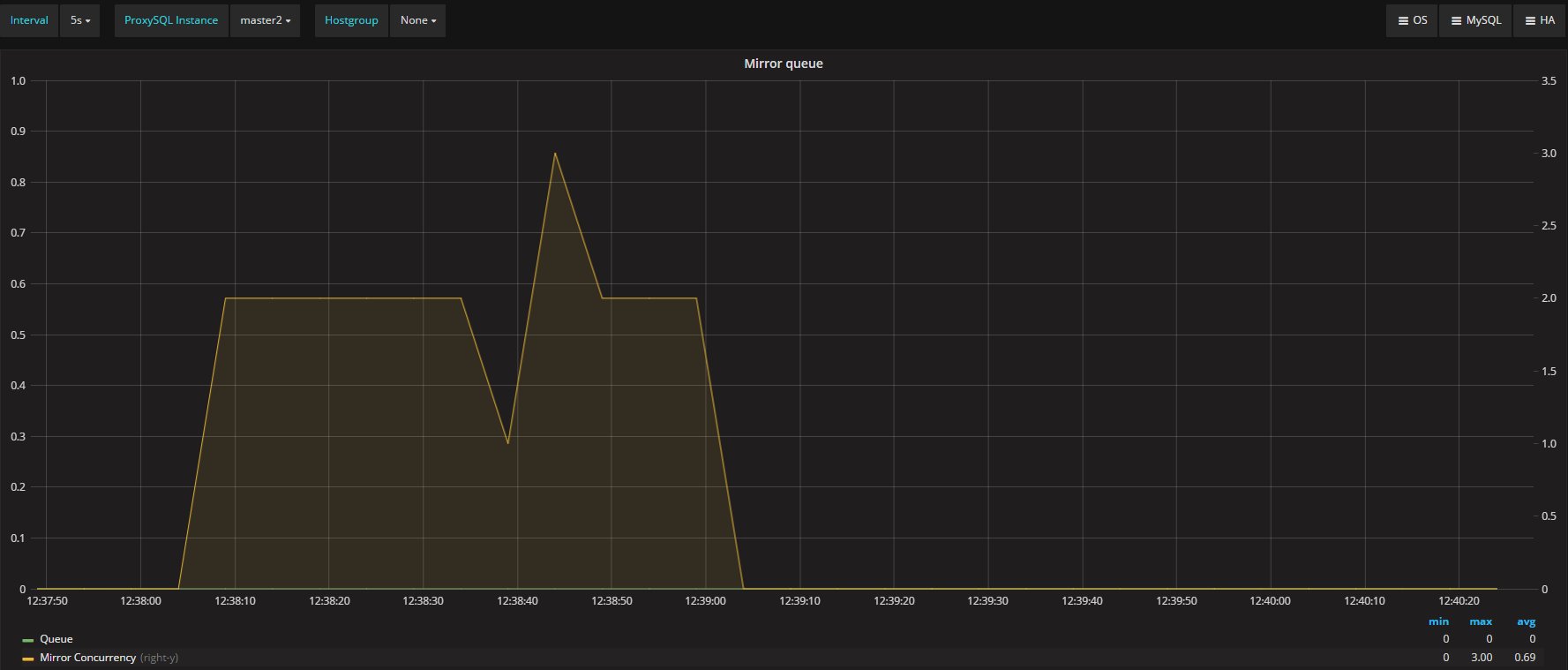
These two new variables and metrics were introduced in ProxySQL 1.4.0, with the intent to control and manage the load ProxySQL generates internally related to the mirroring feature. In this case, you can see we have a max of three concurrent connections and zero queue entries (all good).
Now that we have a baseline, and that we know at functional level “it works,” let see what happens when increasing the load.
The scope of the test was identifying how ProxySQL behaves with a standard configuration and increasing load. It comes up that as soon as ProxySQL has a little bit more load, it starts to lose some queries along the way.
Executing 3000 loops for 40 threads only results in 120,000 rows inserted in all the four tables in Percona XtraDB Cluster. But the table in the secondary (mirrored) platform only has a variable number or inserted rows, between 101,359 and 104,072. This demonstrates consistent loss of data.
After reviewing and comparing the connections running in Percona XtraDB Cluster and the secondary, we can see that (as expected) Percona XtraDB Cluster’s number of connections is scaling and serving the number of incoming requests, while the connections on the secondary are limited by the default value of mysql-mirror_max_concurrency=16.
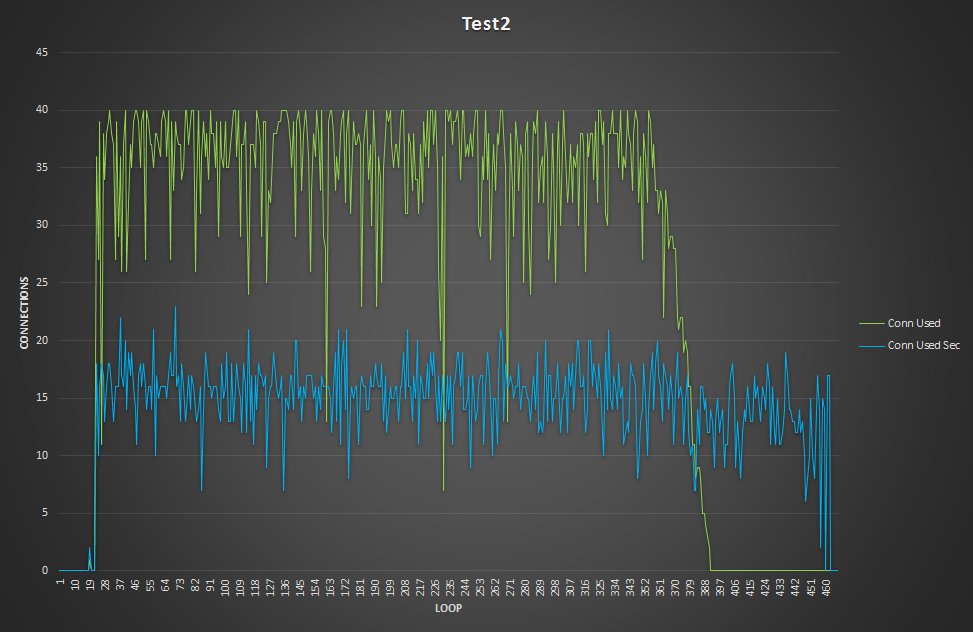
Is also interesting to note that the ProxySQL transaction process queue maintains its connection to the Secondary longer than the connection to Percona XtraDB Cluster.
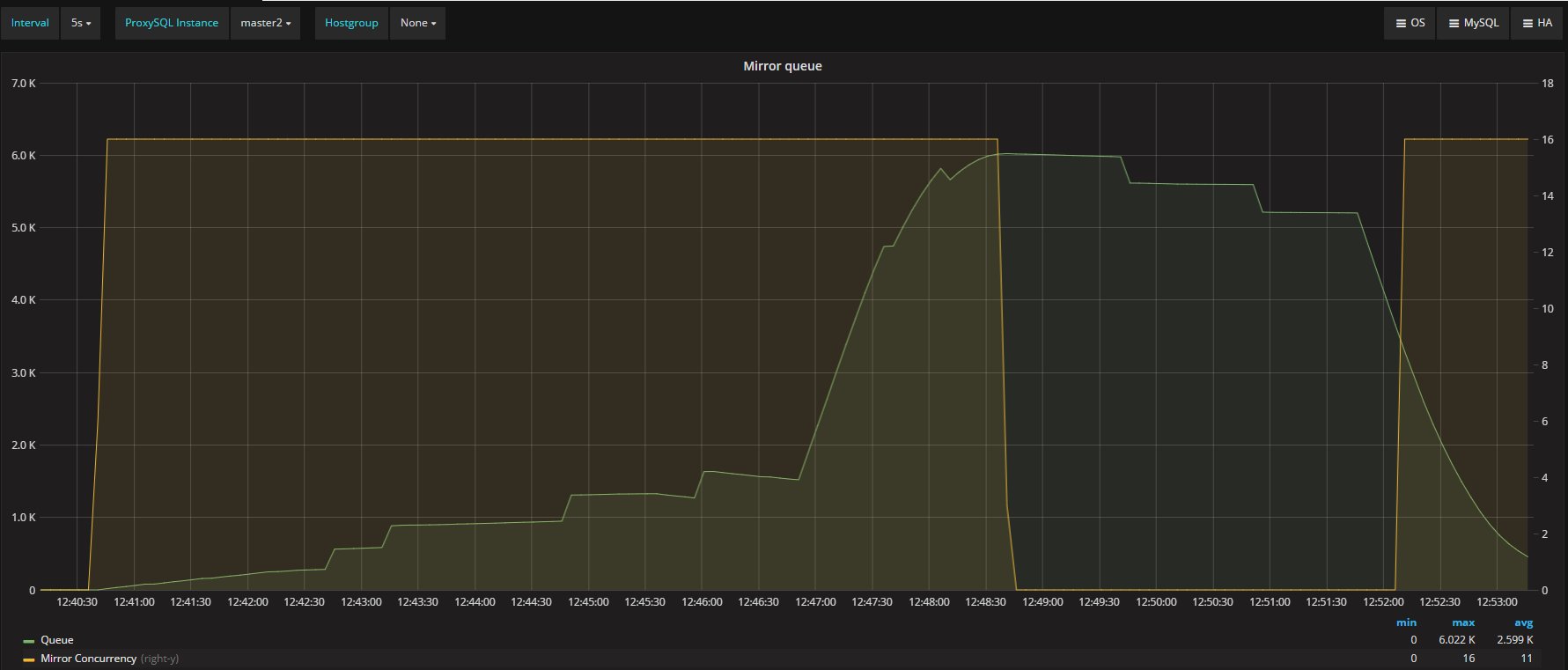
As we can see above, the queue is an evident bell curve that reaches 6K entries (which is quite below the mysql-mirror_max_queue_length limit (32K)). Yet queries were dropped by ProxySQL, which indicates the queue is not really enough to accommodate the pending work.
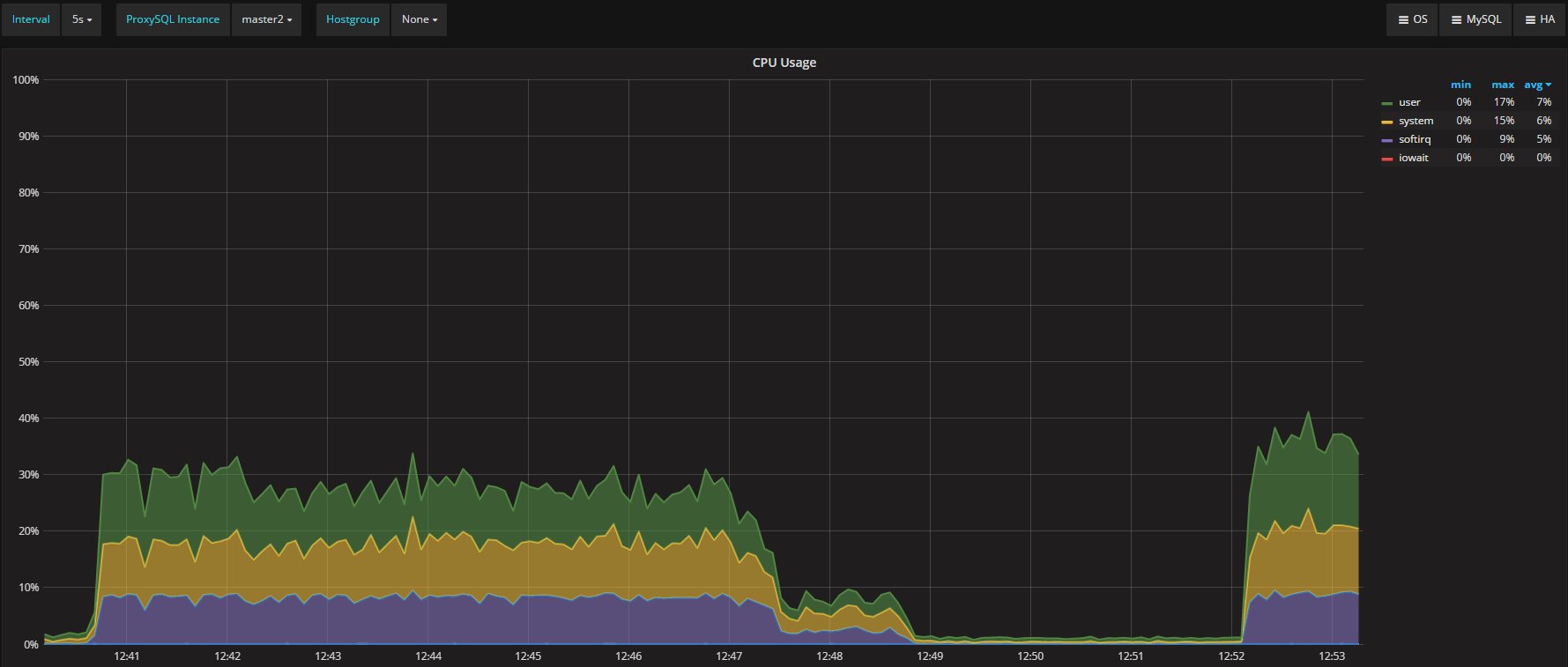
CPU-wise, ProxySQL (as expected) take a few more cycles, but nothing crazy. The overhead for the simple mirroring queue processing can be seen when the main load stops around 12:47.
Another interesting graph to keep an eye on is the one describing the executed commands inside Percona XtraDB Cluster and the secondary:
Percona XtraDB Cluster
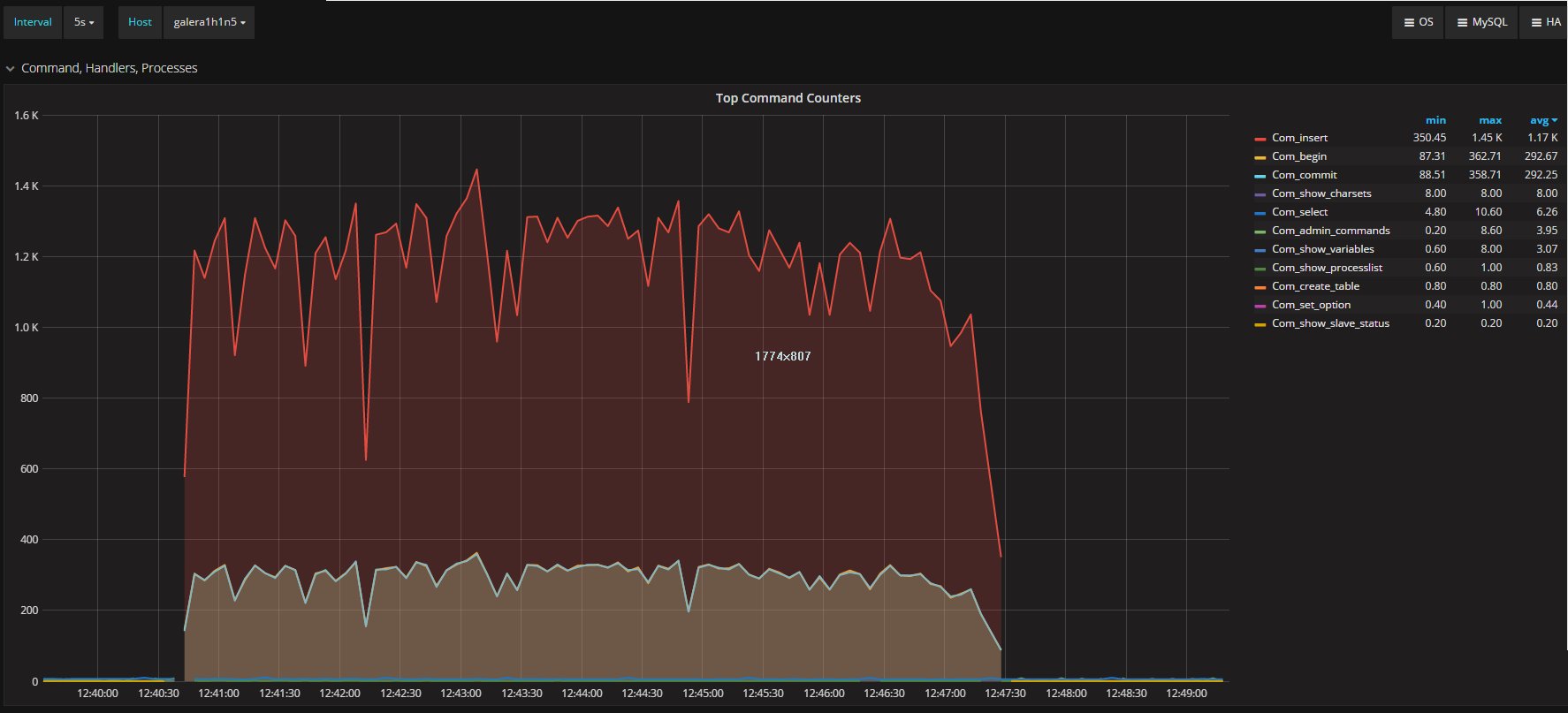
Secondary
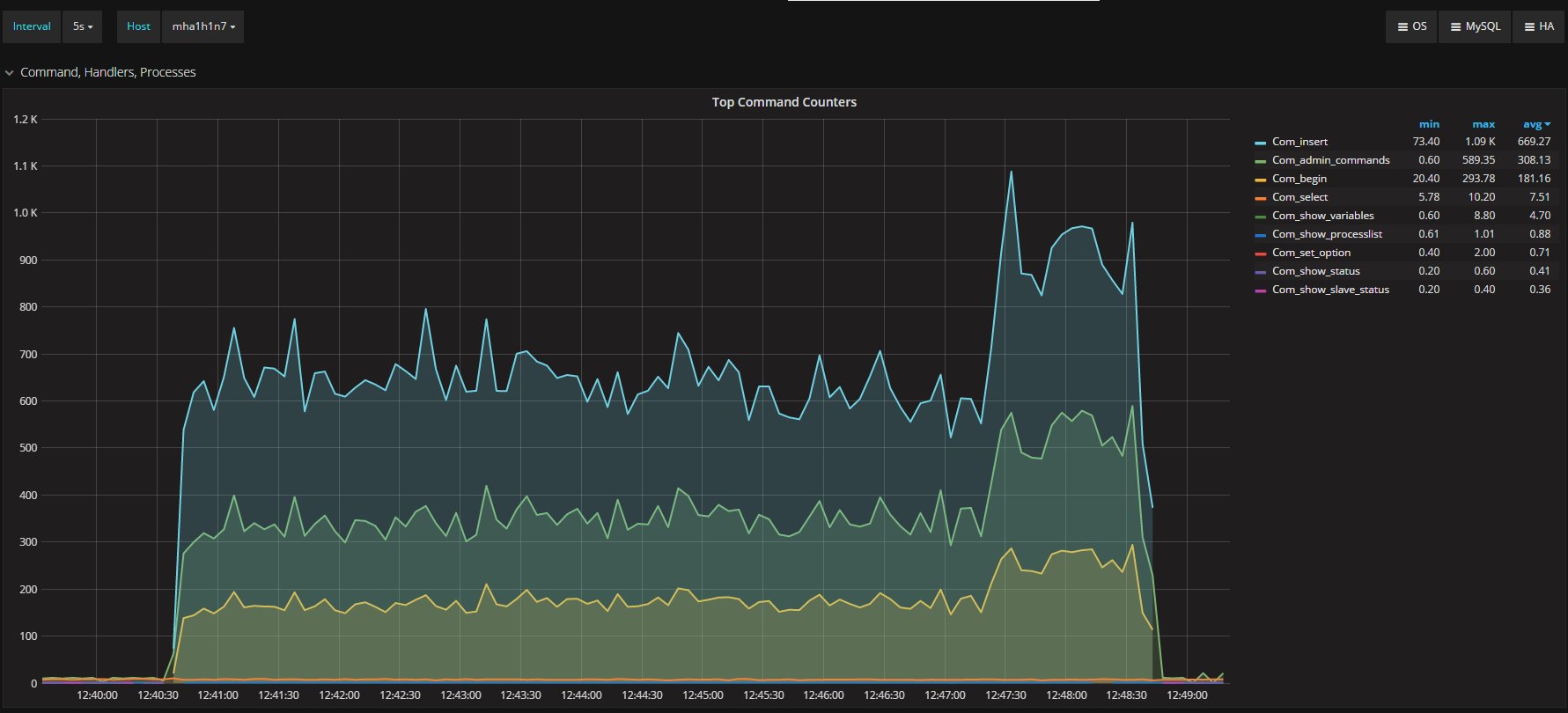
As you can see, the traffic on the secondary was significantly less (669 on average, compared to Percona XtraDB Cluster’s 1.17K). Then it spikes when the main load on the Percona XtraDB Cluster node terminates. In short it is quite clear that ProxySQL is not able to scale following the traffic existing in Percona XtraDB Cluster, and actually loses a significant amount of data on the secondary.
Doubling the load in Test 3 shows the same behavior, with ProxySQL reaches its limit for traffic duplication.
But can this be optimized?
The answer is, of course, yes! This is what the mysql-mirror_max_concurrency is for, so let;’s see what happens if we increase the value from 16 to 100 (just to make it crazy high).
The first thing that comes to attention is that both Percona XtraDB Cluster and secondary report the same number of rows in the tables (240,000). That is a good first win.
Second, note the number of running connections:
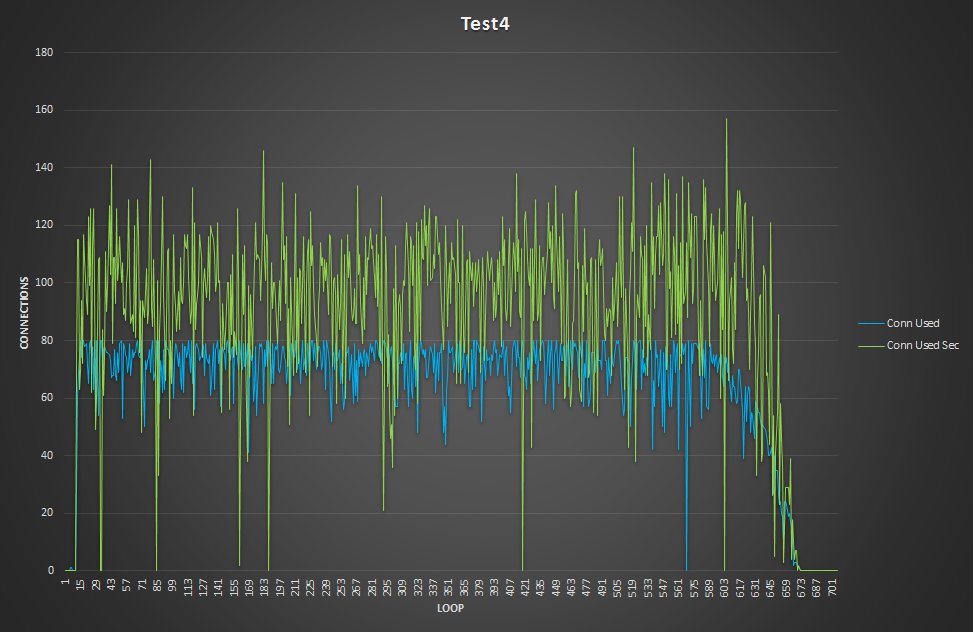
The graphs are now are much closer, and the queue drops to just a few entries.
Commands executed in Percona XtraDB Cluster:
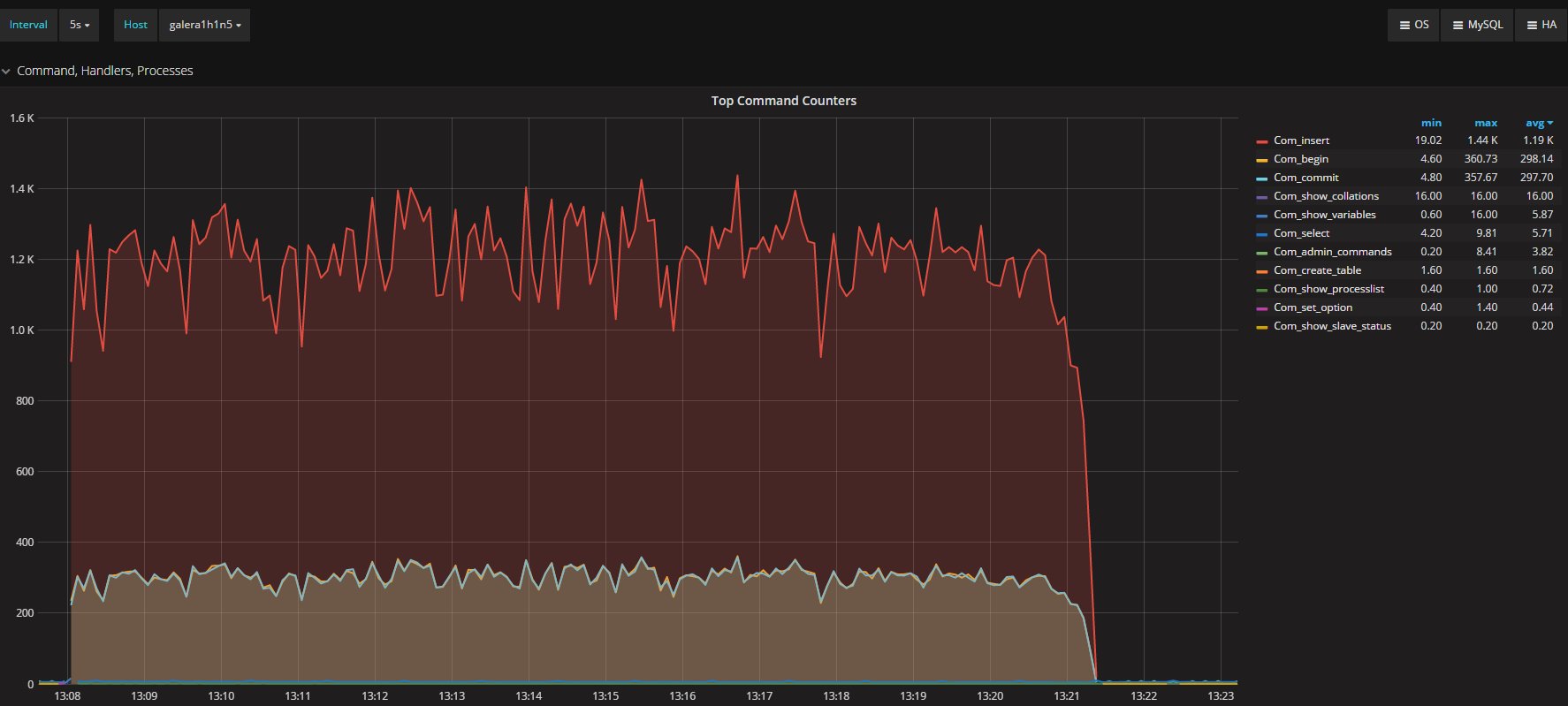
And commands executed in the secondary:
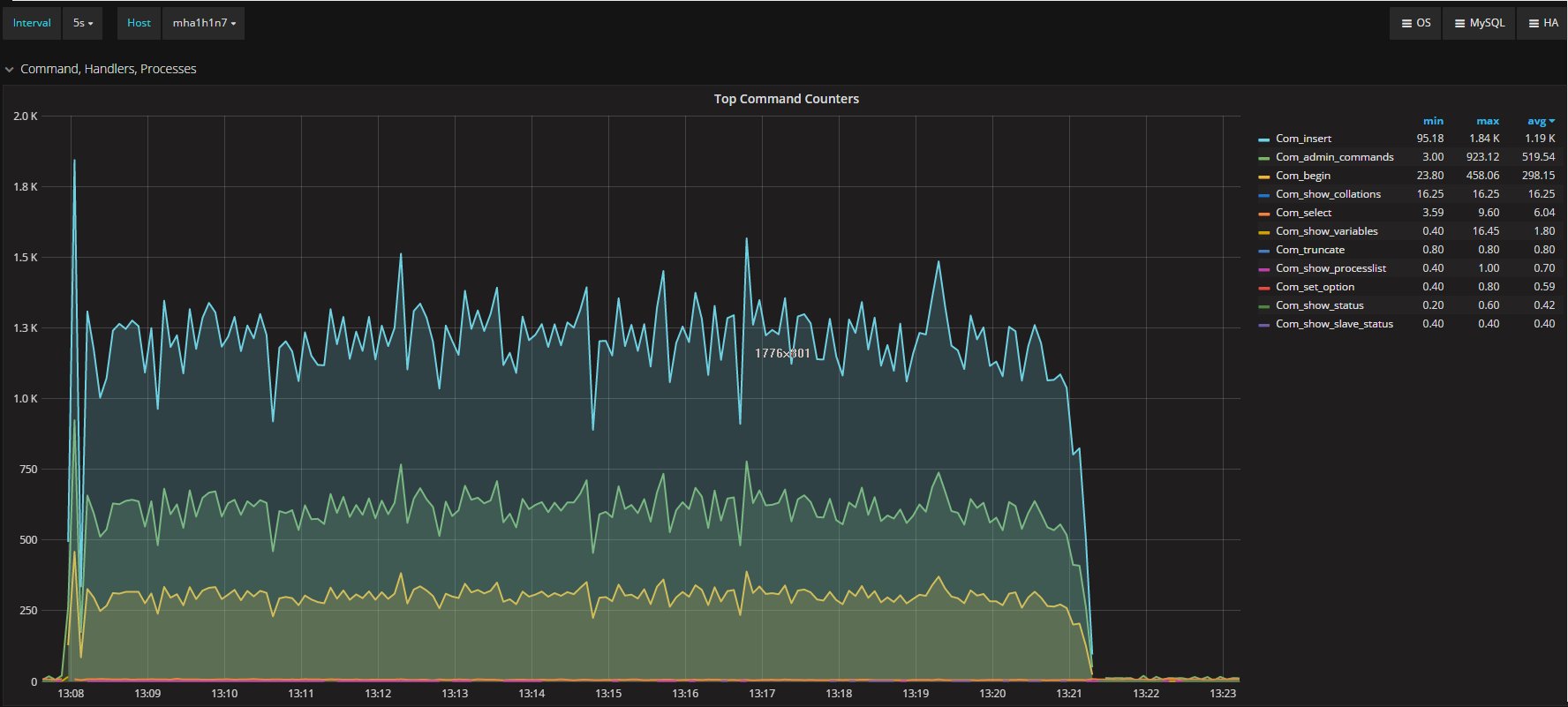
Average execution reports the same value, and very similar trends.
Finally, what was the CPU cost and effect?
Percona XtraDB Cluster and secondary CPU utilization:
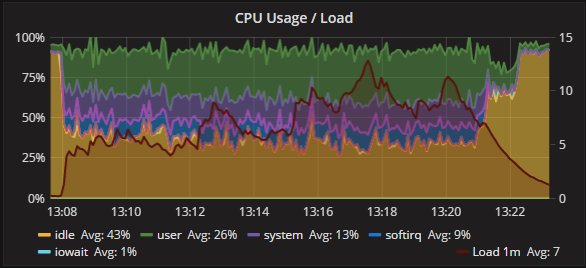
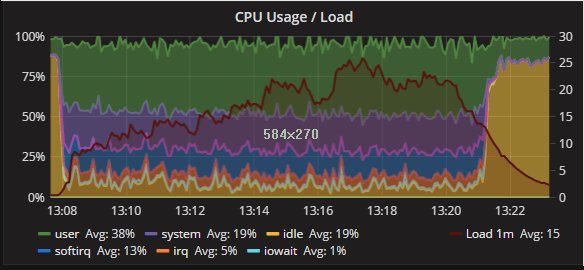
As expected, some difference in the CPU usage distribution exists. But the trend is consistent between the two nodes, and the operations.
The ProxySQL CPU utilization is definitely higher than before:
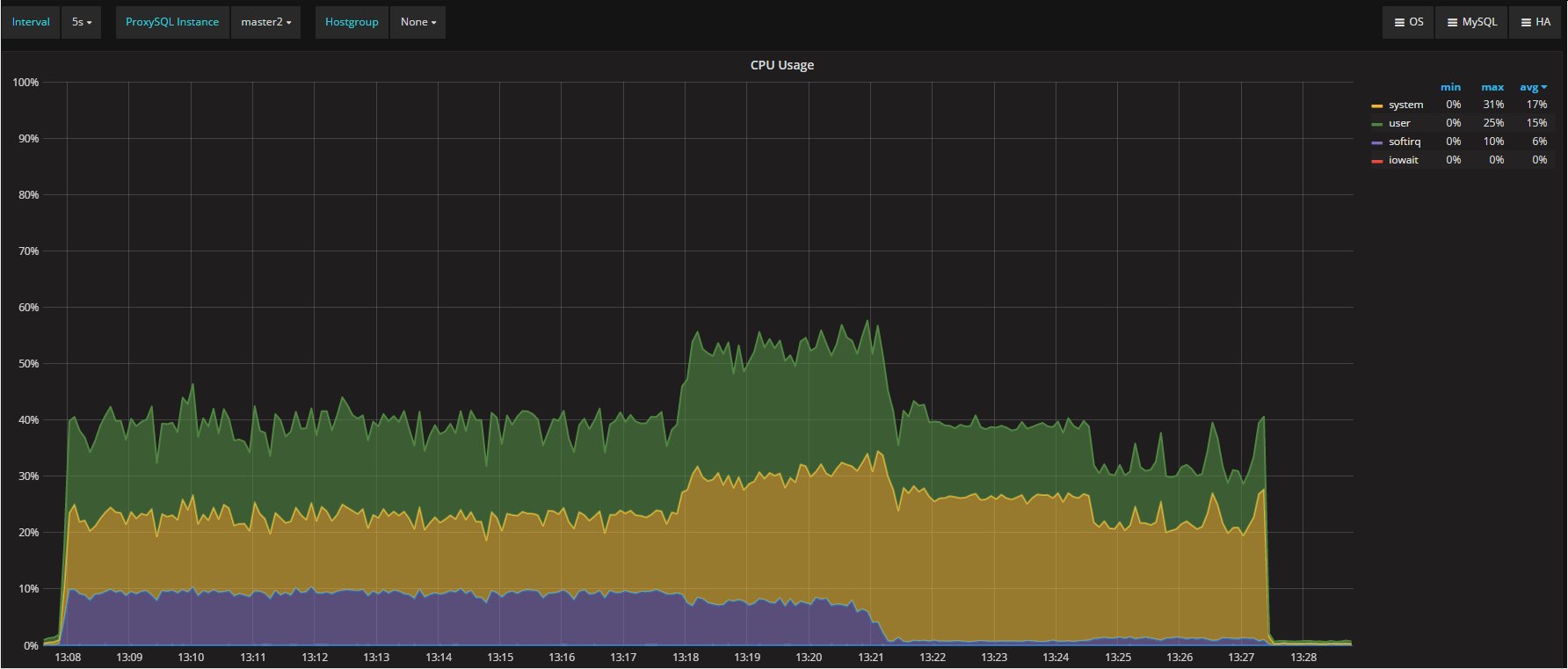
But it’s absolutely manageable, and still reflects the initial distribution.
What about CRUD? So far I’ve only tested the insert operation, but what happen if we run a full CRUD set of tests?
First of all, let’s review the executed commands in Percona XtraDB Cluster:
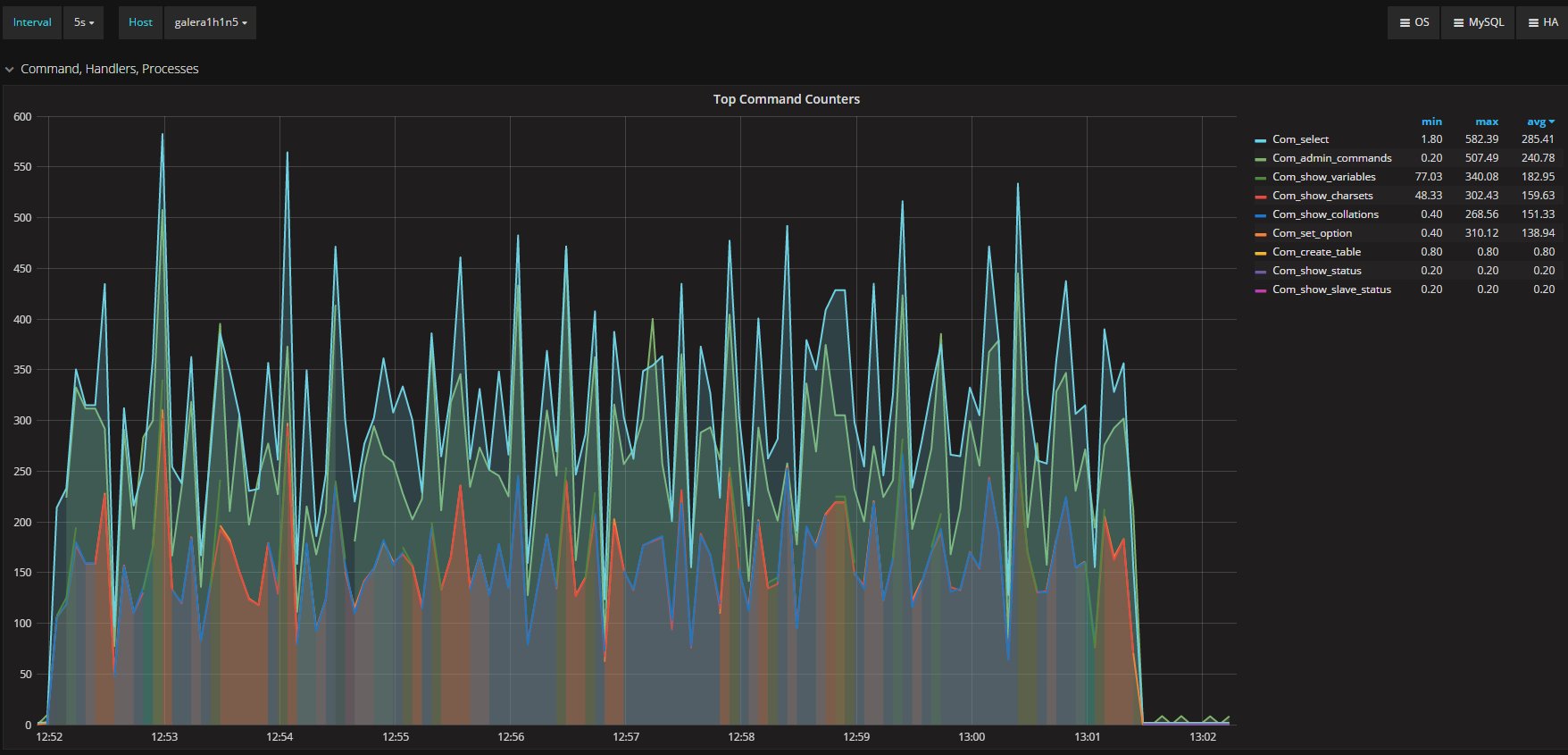
And the secondary:
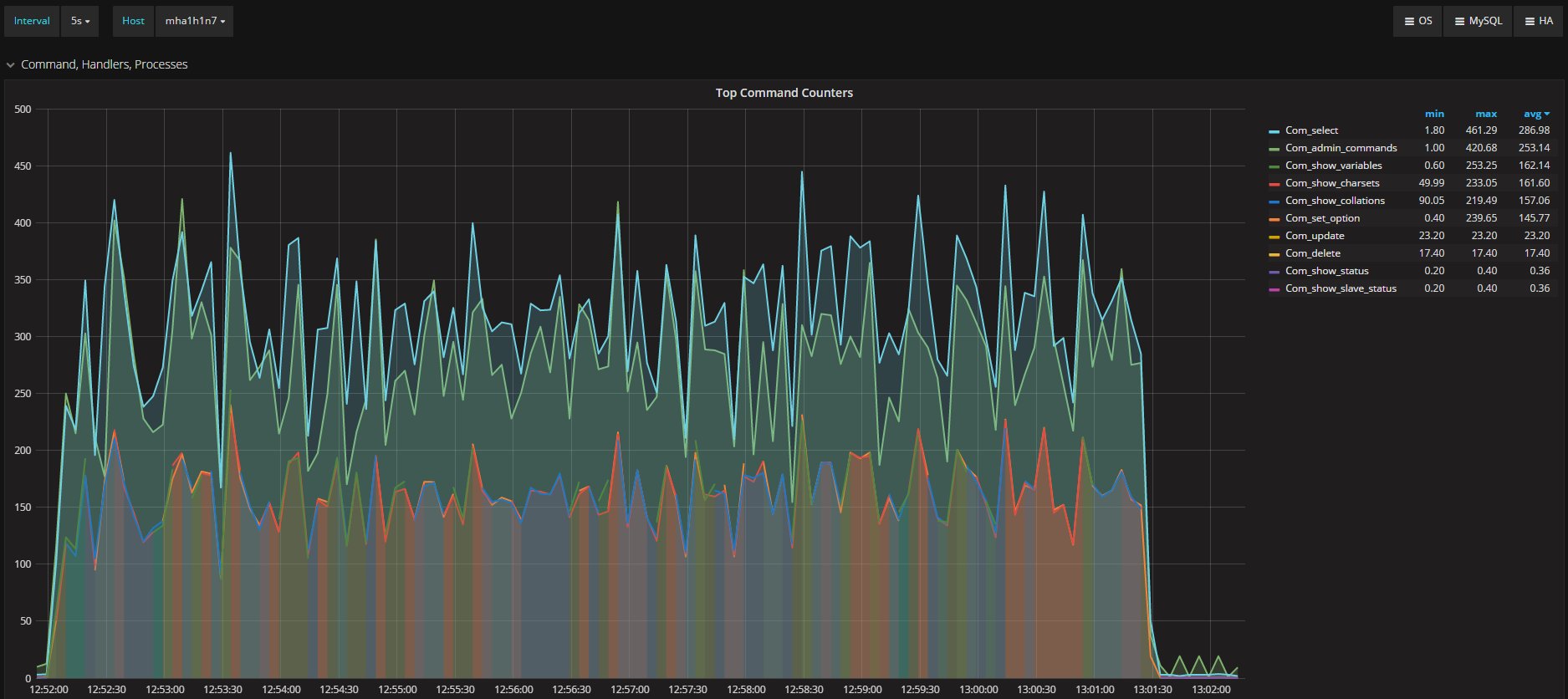
While in appearance we have very similar workloads, selects aside the behavior will significantly diverge. This is because in the secondary the different operations are not encapsulated by the transaction. They are executed as they are received. We can see a significant difference in update and delete operations between the two.
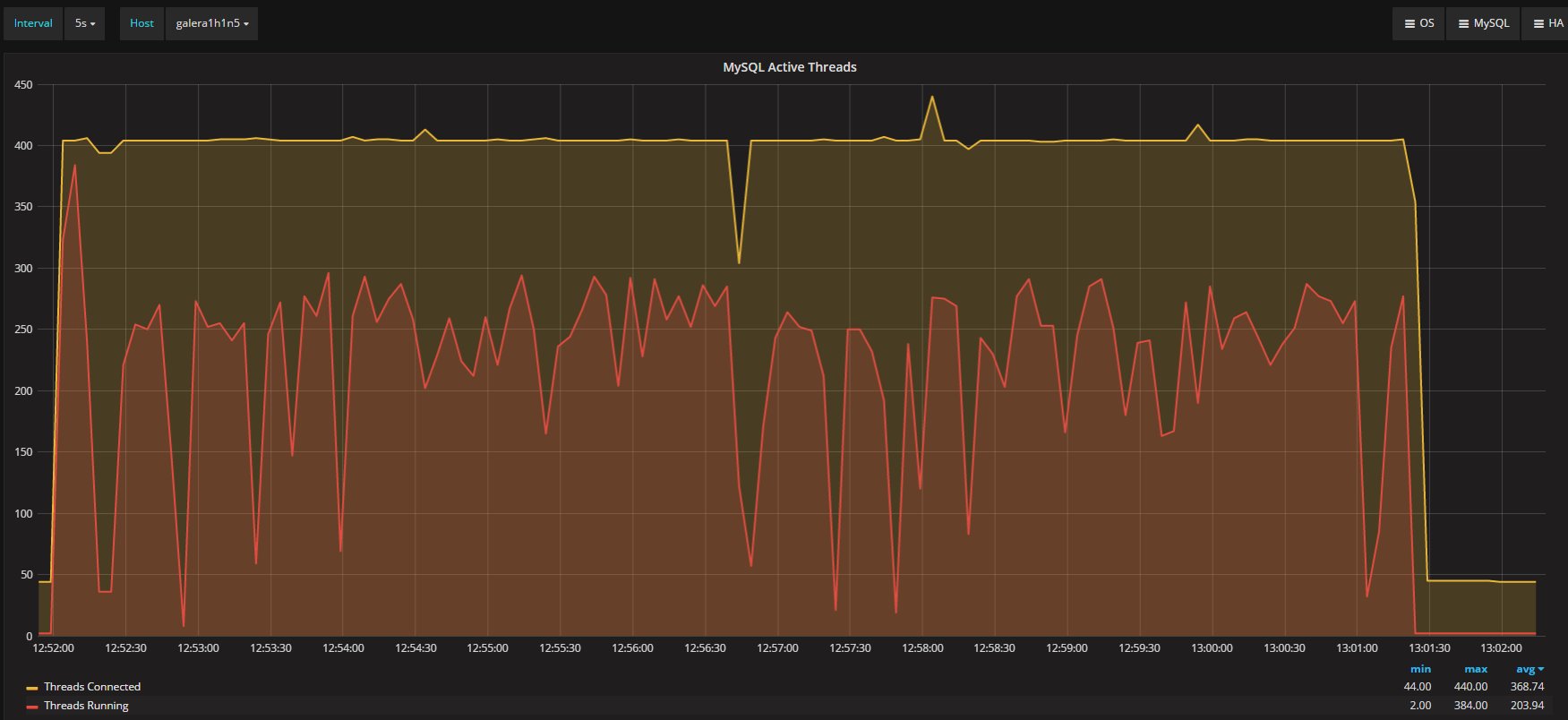
Also, the threads in the execution show a different picture between the two platforms:
Percona XtraDB Cluster
Secondary
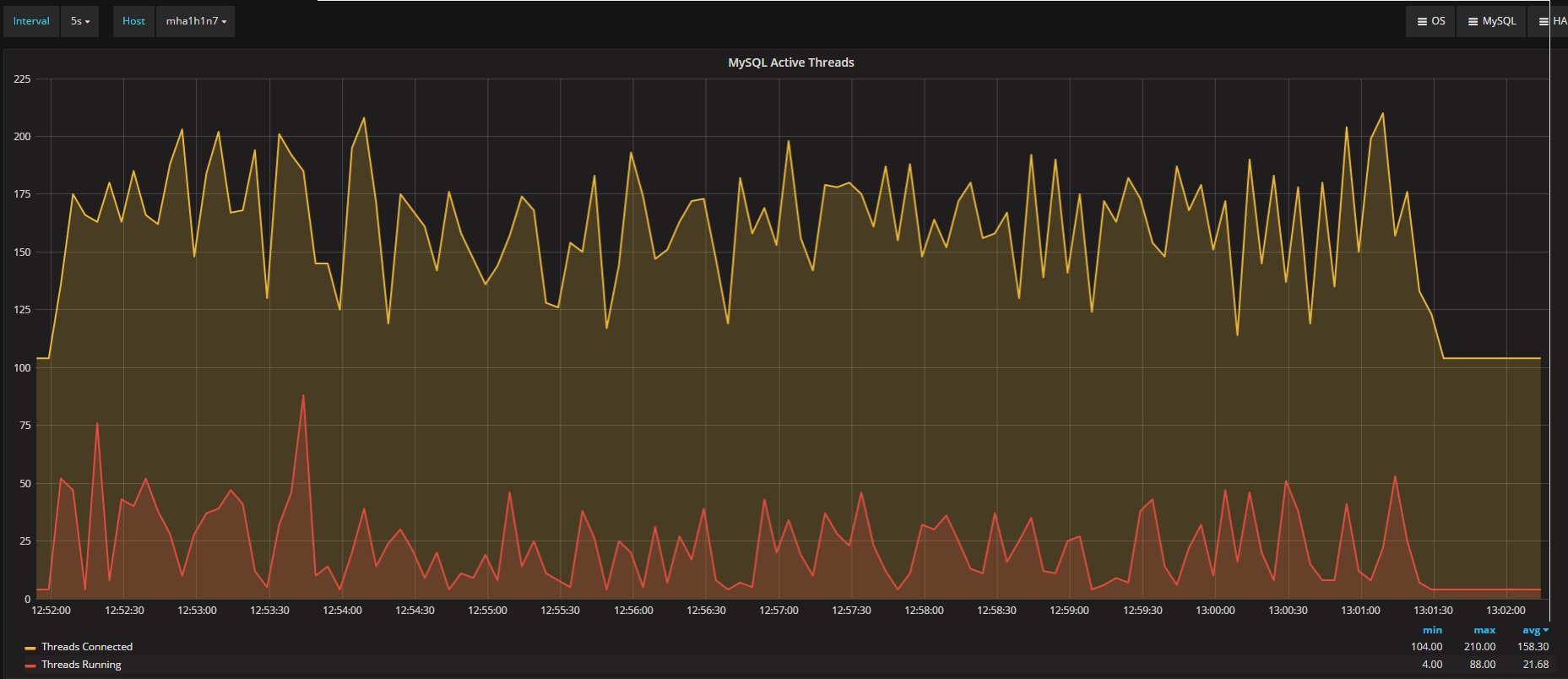
It appears quite clear that Percona XtraDB Cluster is constantly running more threads and more connections. Nevertheless, both platforms process a similar total number of questions:
Percona XtraDB Cluster
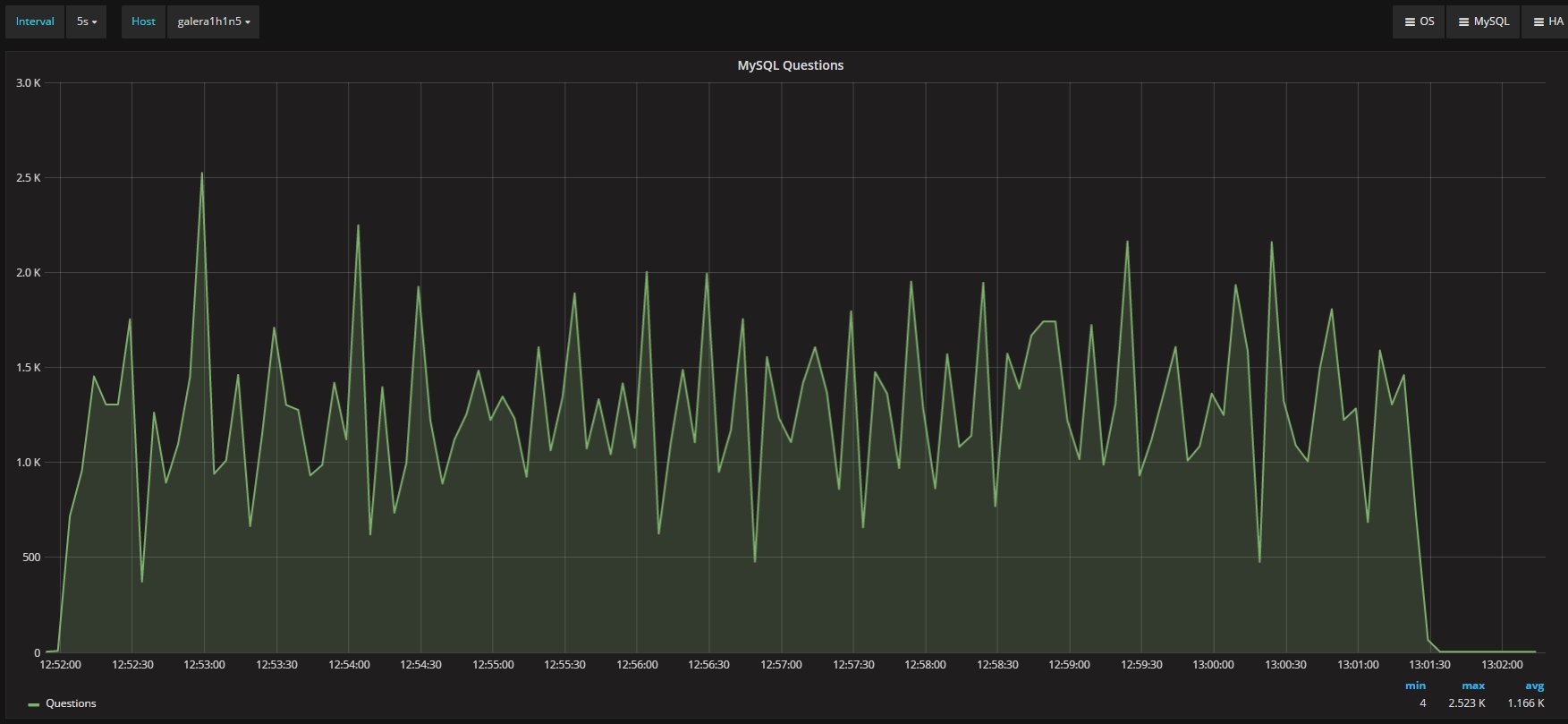
Secondary
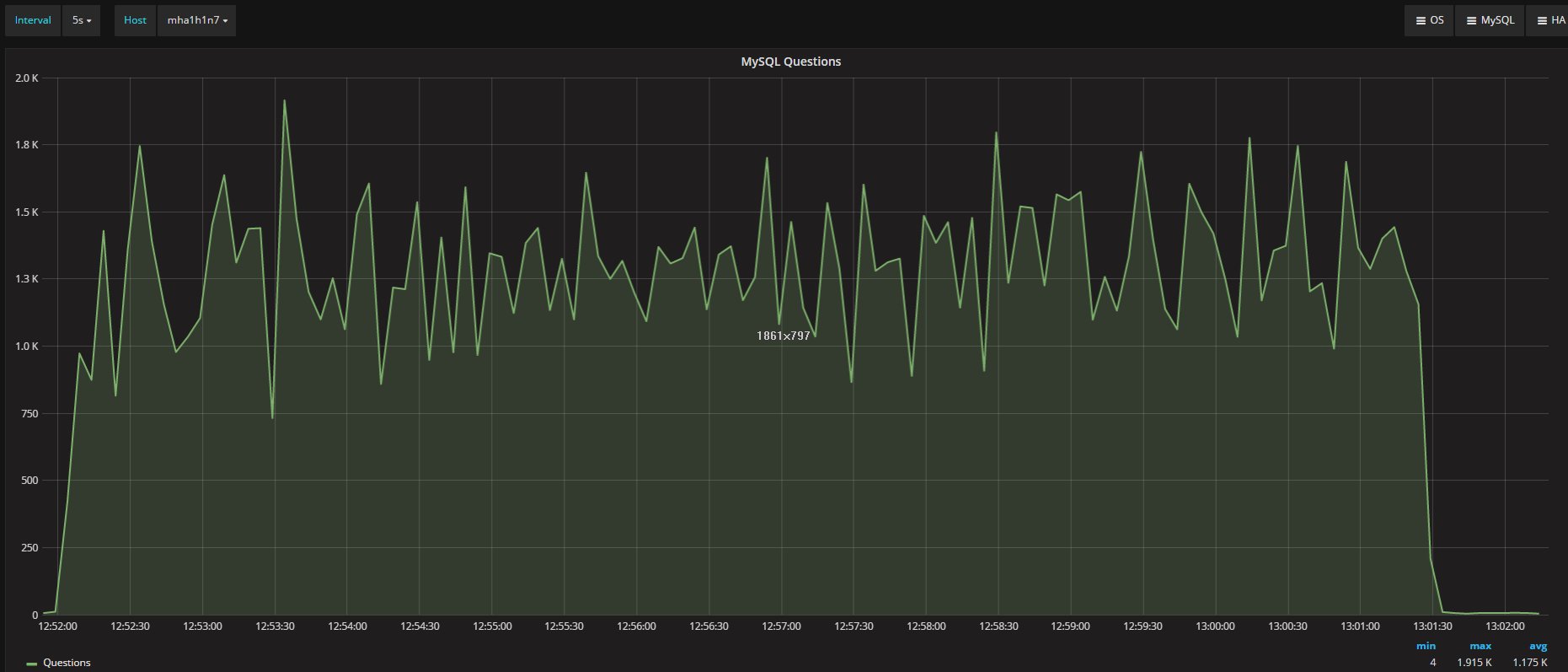
Both have an average or around 1.17K/second questions.
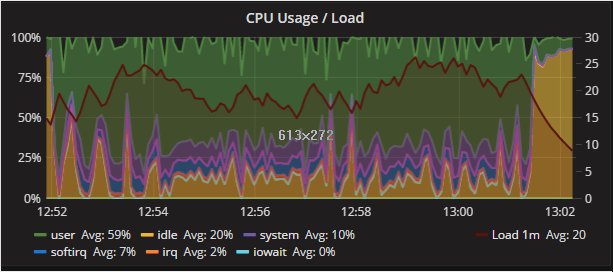
This is also another indication of how much the impact of concurrent operation on behavior, with no respect to the isolation or execution order. Below we can clearly see different behavior by reviewing the CPU utilization:
Percona XtraDB Cluster
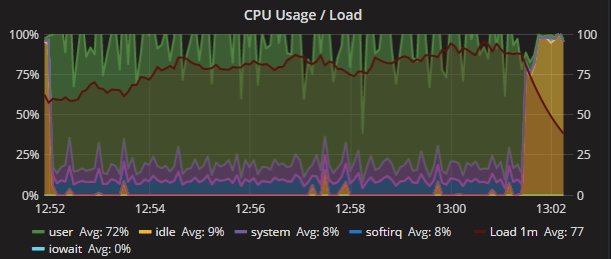
Secondary
To close this article, I want to go back to the start. We cannot consider the mirror function in ProxySQL as a real mirroring, but more as traffic redirection (check here for more reasoning on mirroring from my side).
Using ProxySQL with this approach is still partially effective in testing the load and the effect it has on a secondary platform. As we know, data consistency is not guaranteed in this scenario, and Selects, Updates and Deletes are affected (given the different data-set and result-set they manage).
The server behaviors change between the original and mirror, if not in the quantity or the quality.
I am convinced that when we need a tool able to test our production load on a different or new platform, we would do better to look to something else. Possibly query Playback, recently reviewed and significantly patched by DropBox.
In the end, ProxySQL is already a cool tool. If it doesn’t cover mirroring well, I can live with that. I am interested in having it working as it should (and it does in many other functionalities).
As usual, to Rene, who worked on fixing and introducing new functionalities associated with mirroring, like queue and concurrency control.
To the Percona team who developed Percona Monitoring and Management (PMM): all the graphs here (except 3) come from PMM (some of them I customized).
Resources
RELATED POSTS





Hi,
It seems that playback-query is not able to run against all the databases present in slow query log file.
The parameter mysql-schema accepts only one value.
How can we make it working and replaying all the queries contained in the slow query log indipendenly of the number of the databases?
Thanks.