
In our latest release of Percona XtraDB Cluster, we’ve introduced major performance improvements to the MySQLwrite-set replication layer. In this post, we want to show what these improvements look like.
For the test, we used the sysbench OLTP_RW, UPDATE_KEY and UPDATE_NOKEY workloads with 100 tables, 4mln rows each, which gives about 100GB of datasize. In all the tests we use a three-node setup, connected via a 10GB network, with the sysbench load directed to the one primary node.
In the first chart, we show improvements comparing to the previous version (5.7.16):

The main improvements come from concurrent workloads, under multiple threads.
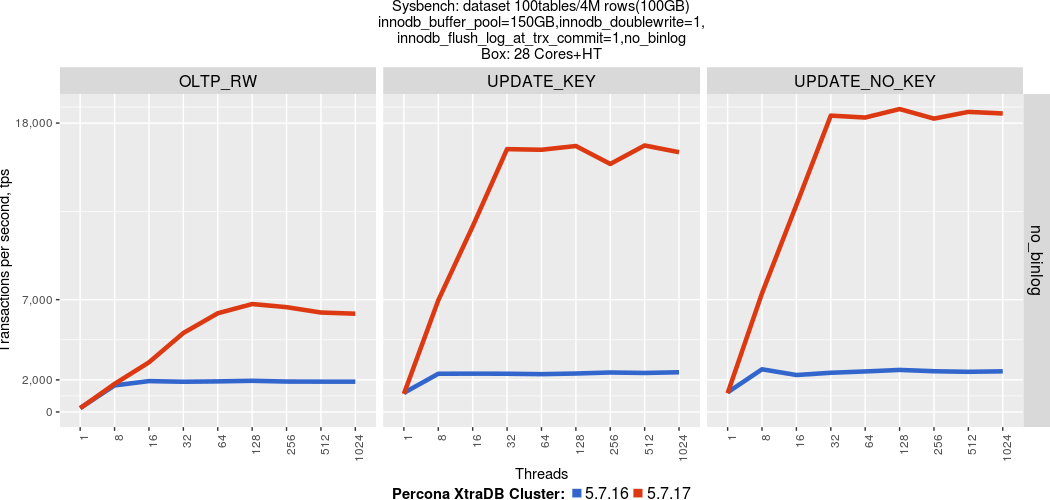
The previous chart is for cases using enabled binary logs, but in some situations we will have deployments without binary logs enabled (Percona XtraDB Cluster does not require them). The latest release significantly improves performance for this case as well.
Here is a chart showing throughput without binary logs:
Where does Percona XtraDB Cluster place in comparison with similar technologies? To find out, we’ll compare this release with MySQL 5.7.17 Group Replication and with the recently released MariaDB 10.2.5 RC.
For MySQL 5.7.17 Group Replication, I’ve reviewed two cases: “durable” with sync_binlog=1, and “relaxed durability” with sync_binlog=0.
Also for MySQL 5.7.17 Group Replication, we want to review two cases with different flow_control settings. The first setting is flow_control=25000 (the default setting). It provides better performance, but with the drawbacks that non-primary nodes will fall behind significantly and MySQL Group Replication does not provide a way to protect from reading stale data. So with a default flow_control=25000, we risk reading very outdated data. We also tested MySQL Group Replication with flow_control=1000 to minimize stale data on non-primary nodes.
A note on the Flow Control topic: it is worth mentioning that we also changed the flow_control default for Percona XtraDB Cluster. The default value is 100 instead of 16 (as in version 5.7.16).
Comparison chart with sync_binlog=1 (for MySQL Group Replication):

Comparison chart with sync_binlog=0 (for MySQL Group Replication):

So there are couple conclusions we can make out of these charts.
The reference our benchmark files and config files are here.





Hello,
Thank you for the nice information. This test result is very interesting for me.
I would like to confirm one thing in this blog post.
> The main improvements come from concurrent workloads, under multiple threads.
I consider “multiple threads” means “wsrep_slave_threads” variable > 1.
But your cnf file and script in Github don’t include this variable.
Do we benefit this improvements with “wsrep_slave_threads=1” (=default value) ?
Best regard,
Hello,
Thank you for your question, we indeed in all our experiments for PXC/MDB/MGR used number of slave workers = 16, so yes we used wsrep_slave_threads=16 and it was just accidentally missed in the published scripts. I have updated starting script for pxc with proper options.
Hi Alexey,
Thank you for reply. I understand all your test use “wsrep_slave_threads=16” setting.
By the way, I tried to the similar performance test in my test environment
by using official PXC docker image.
My machine don’t have rich resources, so I decrease some parameter.
(ex. wsrep_slave_threads=4)
In the results, It seems that PXC 5.7.17 is about 2.5 times faster than PXC 5.7.16.
This is very wonderful !!
5.7.16 : 8500 transactions (14.00 per sec.)
5.7.17 : 20040 transactions (33.12 per sec.)
I’m appreciate the effort of your team.
Thanks. Good to know you are already experiencing the power of new PXC.
In my test experiment,wsrep_slave_threads is 8 at default.The tps increase to 4800 from 2800 when I changed set global wsrep_slave_threads=16 . The performance improvements of increase wsrep_slave_threads is significantly.
Can we set wsrep_slave_threads=16 in some other PXC ,such as Percona-XtraDB-Cluster-57-5.7.16-27.19?
wsrep_slave_threads is dynamic variable and available with older pxc too. You can increase it based on your workload. It will surely help in performance to some level in relative fashion. Significance of slave-thread is more in latest version since things are are completing faster and there is more work than worker.
Also, avoid setting to too high value since that will only increase cpu contention among these threads.
Hi, what is/does UPDATE_KEY and UPDATE_NOKEY, I could not find a definition in sysbench manual. TIA
UPDATE_KEY and NOKEY corresponds to workload where UPDATE updates a column that is part of an index (KEY) or no part of an index (NOKEY)
you can find tests there:
https://github.com/akopytov/sysbench/blob/master/src/lua/oltp_update_index.lua
https://github.com/akopytov/sysbench/blob/master/src/lua/oltp_update_non_index.lua
Hello,
I my benchmark tests, the Percona MySQL 5.7 (single no bin logs) server was 20% faster on reads and 40%-50% on writes versus the Percona XtraDB Cluster (3 nodes PXC with ProxySQL).
I performed the tests on a MacBook PRO with Docker.
On the writes, I get that that there is going to be a penalty, but I was not expecting 40%-50%.
If this difference expected or I am doing something wrong?
What puzzled me was that the performance of MariaDB cluster using Galera was so bad