
This blog post is another in the series on the Percona Server for MongoDB 3.4 bundle release. In this blog, we’ll go over some useful metrics WiredTiger outputs and how we visualize them in Percona Monitoring and Management (PMM).
WiredTiger is the default storage engine for MongoDB since version 3.2. The addition of this full-featured, comprehensive storage engine offered a lot of new, useful metrics  that were not available before in MMAPv1.
that were not available before in MMAPv1.
Percona Monitoring and Management (PMM)
Percona Monitoring and Management (PMM) is an open-source platform for managing and monitoring MySQL and MongoDB, developed by Percona on top of open-source technology. Behind the scenes, the graphing features this article covers use Prometheus (a popular time-series data store), Grafana (a popular visualization tool), mongodb_exporter (our MongoDB database metric exporter) plus other technologies to provide database and operating system metric graphs for your database instances.
Please see a live demo of our PMM 1.1.1 release of the MongoDB WiredTiger graphs covered in this article: https://pmmdemo.percona.com/graph/dashboard/db/mongodb-wiredtiger.
You can see a sneak peak demo of our Percona Memory Engine graphs we’ll release in PMM 1.1.2 here: https://pmmdemo.percona.com/graph/dashboard/db/mongodb-inmemory.
WiredTiger and Percona Memory Engine
WiredTiger is a storage engine that was developed outside of MongoDB, and was acquired and integrated into MongoDB in version 3.0. WiredTiger offers document-level locking, inline compression and many other useful storage engine features. WiredTiger writes data to disk in “checkpoints” and internally uses Multi-Version Concurrency Control (MVCC) to create “transactions” or “snapshots” when accessing data in the engine. In WiredTiger’s metrics, you will see the term “transactions” used often. It is important to note, however, that MongoDB does not support transactions at this time (this only occurs within the storage engine).
WiredTiger has an in-heap cache for mostly uncompressed pages (50% RAM by default). Like many other engines, it relies on the performance of the Linux filesystem cache, which ends up caching hot, compressed WiredTiger disk blocks.
Besides supporting WiredTiger, Percona Server for MongoDB also ships with a free, open-source in-memory storage engine: Percona Memory Engine for MongoDB. Since we based the Memory Engine on WiredTiger, all graphs and troubleshooting techniques for in-memory are essentially the same (the database data is not stored on disk, of course).
Checkpointing Graphs
WiredTiger checkpoints data to disk every 60 seconds, or after writing 2GB of journaled data.
PMM graphs the current minimum and maximum checkpoint times for WiredTiger checkpoints in the “WiredTiger Checkpoint Time” graph: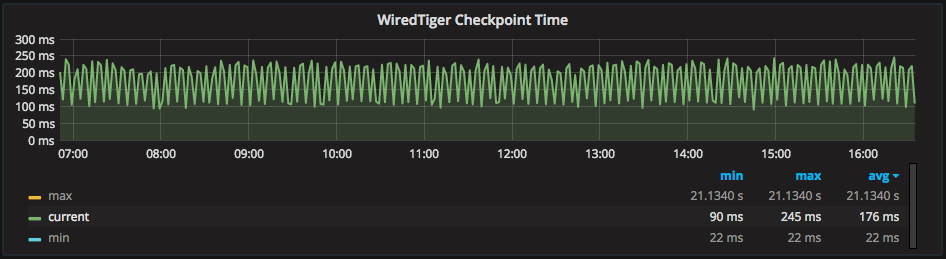
Above I have selected “current,” and we can see we have an average of 176ms checkpoints and over a long period it remains flat, not worsening or “snowballing” each checkpoint (which may indicate a performance issue).
Checkpointing is important to watch because it requires WiredTiger to use system resources, and also can affect query performance in an possibly unexpected way — WiredTiger Cache dirty pages:
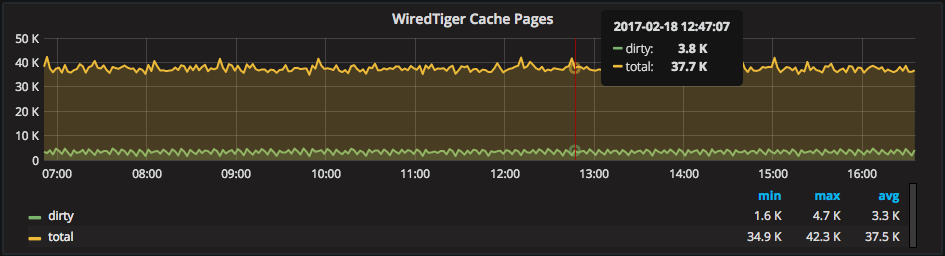
The WiredTiger Cache is an LRU cache of mostly uncompressed pages. Like most caches, it creates dirty pages that can take up useful memory until flushed. The WiredTiger Cache uses checkpointing as the point in which it clears dirty pages, making the relationship between dirty pages and checkpointing important to note. WiredTiger cleans dirty pages less often if checkpoint performance is slow. They then can slowly consume more and more of the available cache memory.
In the above graph, we can see on average about 8.8% of the cache is dirty pages with spikes up/down aligning with checkpointing. Systems with a very high rate of dirty pages benefit from more RAM to provide more room for “clean” pages. Another option could be improving storage performance, so checkpoints happen faster.
Concurrency Graph
Similar to InnoDB, WiredTiger uses a system of tickets to control concurrency. Where things differ from InnoDB is both “reads” and “writes” have their own ticket pools with their own maximum-ticket limits. The defaults of “128” tickets for both read and write concurrency is generally enough for even medium-high usage systems. Some systems are capable of more than the default concurrency limit, however (usually systems with very fast storage). Also, concurrency can sometimes reduce overhead on network-based storage.
If you notice higher ticket usage, it can sometimes be due to a lot of single-document locking in WiredTiger. This is something to check if you see high rates alongside storage performance and general query efficiency.
In Percona Monitoring and Management, we have the “WiredTiger Concurrent Transactions” graph to visualize the usage of the tickets. In most cases, tickets shouldn’t reach the limit and you shouldn’t need to tweak this tuneable. If you do require more concurrency, however, PMM’s graphing helps indicate when limits are being reached and whether a new limit will mitigate the problem.

Here we can see a max usage of 8/128 write tickets and 5/128 read tickets. This means this system isn’t having any concurrency issues.
Throughput Graphs
There are several WiredTiger graphs to explain the rate of data moving through the engine. As storage is a common bottleneck, I generally look at “WiredTiger Block Activity” first when investigating storage resource usage. This graph shows the total rates written and read to/from storage by WiredTiger (disk for WiredTiger, memory for in-memory).
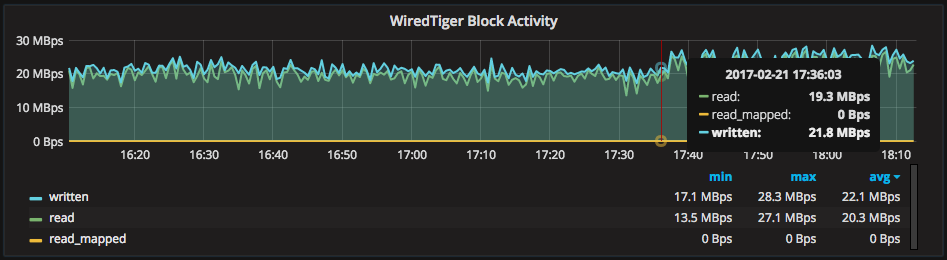
For correlation, there are also rates for the amount of data written from and read into the WiredTiger cache, from disk. The “read” metric shows the rate of data added to the cache due to query patterns (e.g.: scanning), while the “written” metric shows the rate of data written out to storage from the WiredTiger cache.
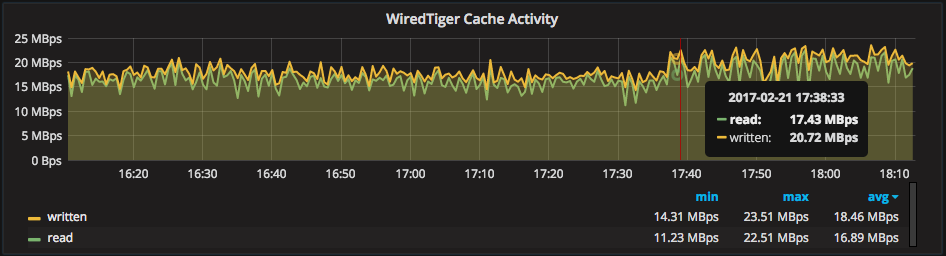
Also there are rates to explain the IO caused by the WiredTiger Log. The metric “payload” is the essentially the write rate of raw BSON pages, and “written” is a combined total of log bytes written (including overhead, likely the frames around the payload, etc.). You should watch changes to the average rate of “read” carefully, as they may indicate changes in query patterns or efficiency.
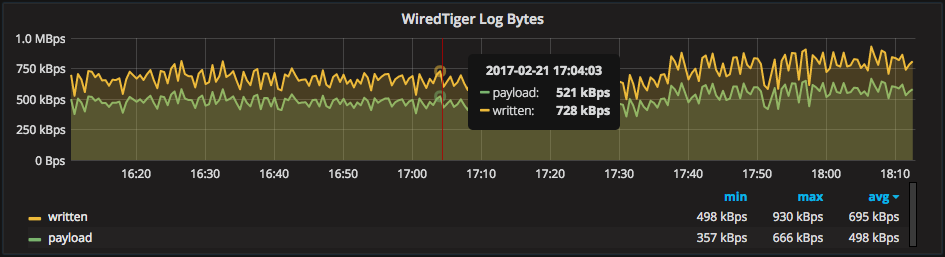
Detailed Cache Graphs
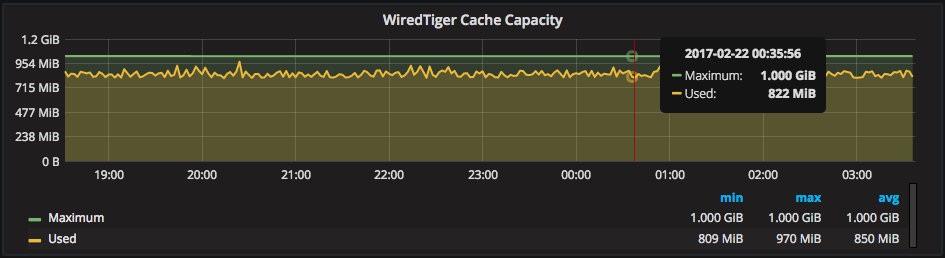
In addition to the Dirty Pages in the cache graph, “WiredTiger Cache Capacity” graphs the size and usage of the WiredTiger cache:
The rate of cache eviction is graphed in “WiredTiger Cache Eviction,” with a break down of modified vs. unmodified pages:
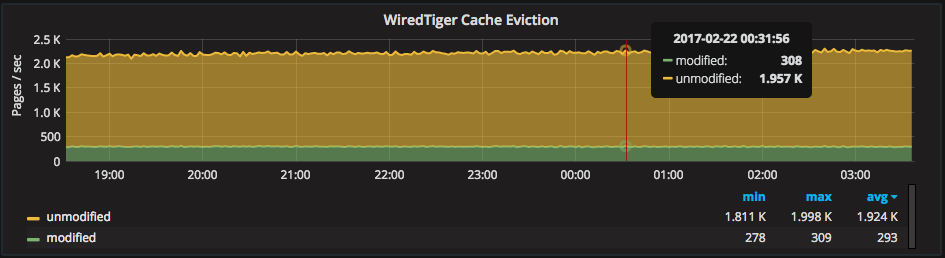
Very large spikes in eviction can indicate collection scanning or generally poor performing queries. This pushes data out of caches. You should avoid high rates of cache evictions, as they can cause a high overhead to the overall engine.
When increasing the size of the WiredTiger cache it is useful to look at both of the above cache graphs. You should look for more “Used” memory in the “WiredTiger Cache Capacity” graph and less rate of eviction in the “WiredTiger Cache Eviction” graph. If you do not see changes to these metrics, you may see better performance leaving the cache size as-is.
Transactions and Document Operations
The “WiredTiger Transactions” graph shows the overall operations happening inside the engine. All transactions start with a “begin,” and operations that changed data end with a “commit.” Read-only operations show a “rollback” at the time they returned data:
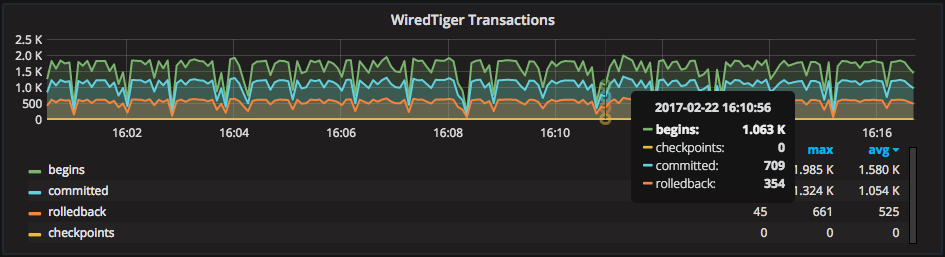
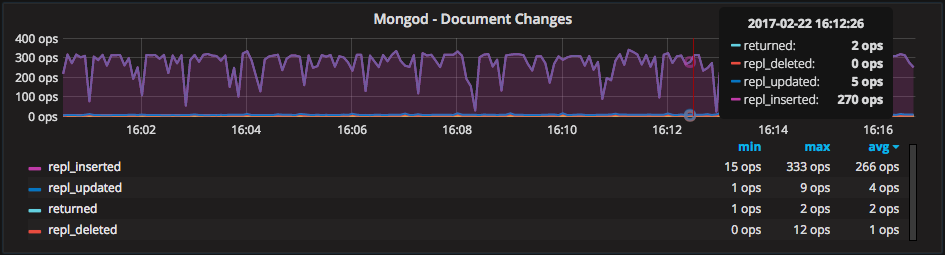
This graph above correlates nicely with the “Mongod – Document Activity” graph, which shows the rate of operations from the MongoDB-layer perspective instead of the storage engine level:
Detailed Log Graphs
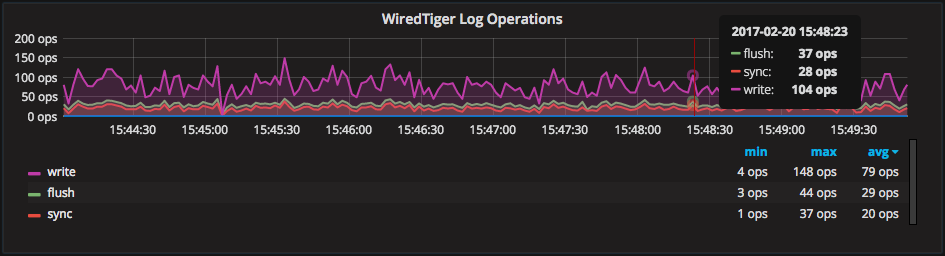
The graph “WiredTiger Log Operations” explains activity inside the WiredTiger Log system:
Also, the rate of log record compression is graphed as “WiredTiger Log Records.” WiredTiger only compresses log operations that are greater than 128 bytes, which explains why some log records are not compressed:
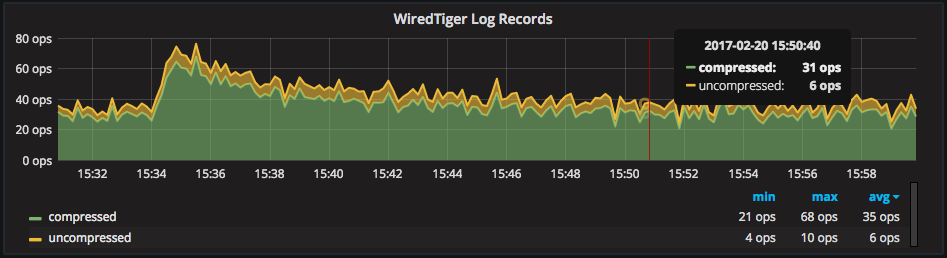
In some cases, changes in the ratio of compressed vs. uncompressed pages may help explain changes in CPU% used.
What’s Missing?
As you’ll see in my other blog post “Percona Monitoring and Management (PMM) Graphs Explained: MongoDB with RocksDB” from this series, RocksDB includes read latency metrics and a hit ratio for the RocksDB block cache. These are two things I would like to see added to WiredTiger’s metric output, and thus PMM. I would also like to improve the user-experience of this dashboard. Some areas use linear-scaled graphs when a logarithmic-scaled graph could provide more value. “WiredTiger Concurrent Transactions” is one example of this.
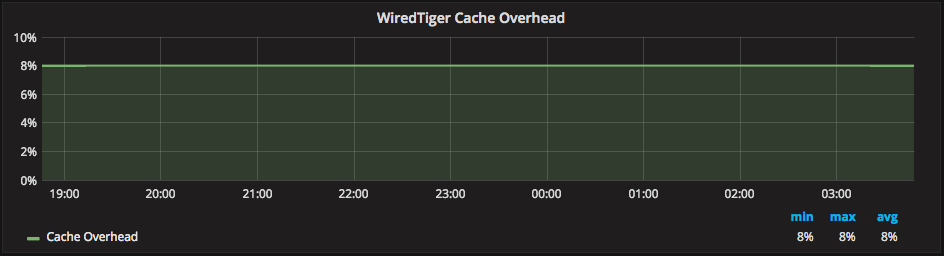
A known-mystery (so-to-speak) is why WiredTiger reports the cache “percentage overhead” always as 8% in “db.serverStatus().cache.” We added this metric to PMM as a graph named “WiredTiger Cache Overhead.” We assumed it provided a variable overhead metric. However, I’ve seen that it returns 8% regardless of usage: it is 8% on a busy system or even on an empty system with no data or traffic. We’re aware of this, and plan to investigate, as a hit ratio for the cache is a very valuable metric:
Also, if you’ve ever seen the full output of the WiredTiger status metrics (‘db.serverStatus().wiredTiger’ in Mongo shell), you’ll know that there are a LOT more WiredTiger metrics than are currently graphed in Percona Monitoring and Management. In our initial release, we’ve aimed to only include high-value graphs to simplify monitoring WiredTiger. A major barrier in our development of monitoring features for WiredTiger has been the little-to-no documentation on the meaning of many status metrics. I hope this improves with time. As we understand more correlations and useful metrics to determine the health of WiredTiger, we plan to integrate those into Percona Monitoring and Management in the future. As always, we appreciate your suggestions.
Lastly, look out for an upcoming blog post from this series regarding creating custom dashboards, graphs and raw data queries with Percona Monitoring and Management!
Resources
RELATED POSTS




