
 This blog post is another in the series on the Percona Server for MongoDB 3.4 bundle release. In mid-2016, Percona Monitoring and Management (PMM) added support for RocksDB with MongoDB, also known as “MongoRocks.” In this blog, we will go over the Percona Monitoring and Management (PMM) 1.1.0 version of the MongoDB RocksDB dashboard, how PMM is useful in the day-to-day monitoring of MongoDB and what we plan to add and extend.
This blog post is another in the series on the Percona Server for MongoDB 3.4 bundle release. In mid-2016, Percona Monitoring and Management (PMM) added support for RocksDB with MongoDB, also known as “MongoRocks.” In this blog, we will go over the Percona Monitoring and Management (PMM) 1.1.0 version of the MongoDB RocksDB dashboard, how PMM is useful in the day-to-day monitoring of MongoDB and what we plan to add and extend.
Percona Monitoring and Management (PMM)
Percona Monitoring and Management (PMM) is an open-source platform for managing and monitoring MySQL and MongoDB, developed by Percona on top of open-source technology. Behind the scenes, the graphing features this article covers use Prometheus (a popular time-series data store), Grafana (a popular visualization tool), mongodb_exporter (our MongoDB database metric exporter) plus other technologies to provide database and operating system metric graphs for your database instances.
The mongodb_exporter tool, which provides our monitoring platform with MongoDB metrics, uses RocksDB status output and optional counters to provide detailed insight into RocksDB performance. Percona’s MongoDB 3.4 release enables RocksDB’s optional counters by default. On 3.2, however, you must set the following in /etc/mongod.conf to enable this: storage.rocksdb.counters: true .
This article shows a live demo of our MongoDB RocksDB graphs: https://pmmdemo.percona.com/graph/dashboard/db/mongodb-rocksdb.
RocksDB/MongoRocks
RocksDB is a storage engine available since version 3.2 in Percona’s fork of MongoDB: Percona Server for MongoDB.
The first thing to know about monitoring RocksDB is compaction. RocksDB stores its data on disk using several tiered levels of immutable files. Changes written to disk are written to the first RocksDB level (Level0). Later the internal compactions merge the changes down to the next RocksDB level when Level0 fills. Each level before the last is essentially deltas to the resting data set that soon merges down to the bottom.
We can see the effect of the tiered levels in our “RocksDB Compaction Level Size” graph, which reflects the size of each level in RocksDB on-disk:
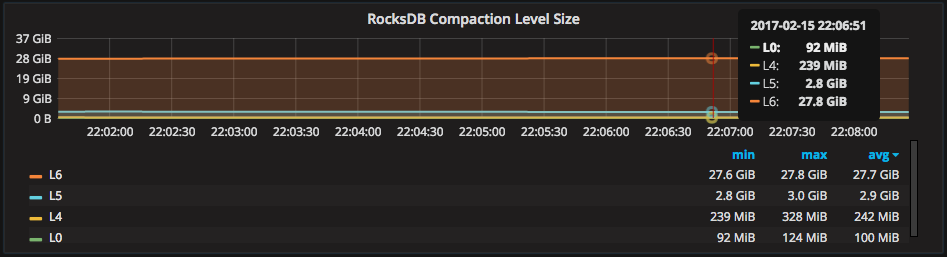
Note that most of the database data is in the final level “L6” (Level 6). Levels L0, L4 and L5 hold relatively smaller amounts of data changes. These get merged down to L6 via compaction.
More about this design is explained in detail by the developers of MongoRocks, here: https://www.percona.com/live/plam16/sessions/everything-you-wanted-know-about-mongorocks.
RocksDB Compaction
Most importantly, RocksDB compactions try to happen in the background. They generally do not “block” the database. However, the additional resource usage of compactions can potentially cause some spikes in latency, making compaction important to watch. When compactions occur, between levels L4 and L5 for example, L4 and L5 are read and merged with the result being written out as a new L5.
The memtable in MongoRocks is a 64mb in-memory table. Changes initially get written to the memtable. Reads check the memtable to see if there are unwritten changes to consider. When the memtable has filled to 100%, RocksDB performs a compaction of the memtable data to Level0, the first on-disk level in RocksDB.
In PMM we have added a single-stat panel for the percentage of the memtable usage. This is very useful in indicating when you can expect a memtable-to-level0 compaction to occur:
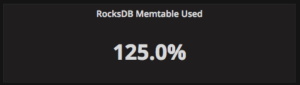
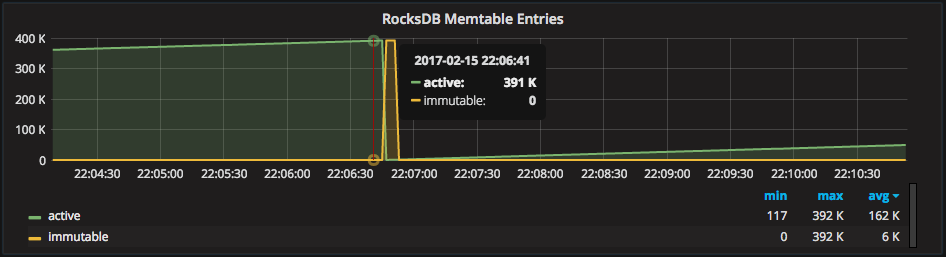
Above we can see the memtable is 125% used, which means RocksDB is late to finish (or start) a compaction due to high activity. Shortly after taking this screenshot above, however, our test system began a compaction of the memtable and this can be seen at the drop in active memtable entries below:
Following this compaction further through PMM’s graphs, we can see from the (very useful) “RocksDB Compaction Time” graph that this compaction took 5 seconds.
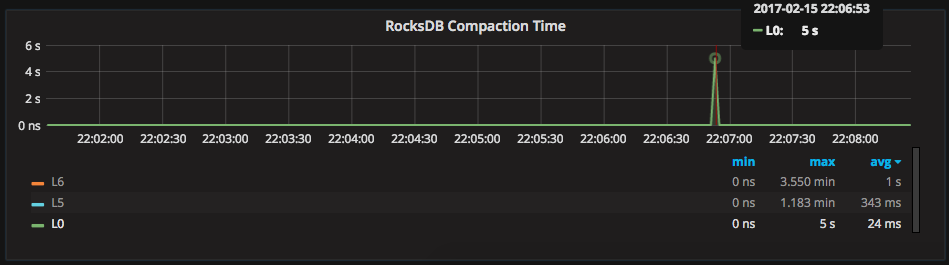
In the graph above, I have singled-out “L0” to show Level0’s compaction time. However, any level can be selected either per-graph (by clicking on the legend-item) or dashboard-wide (by using the RocksDB Level drop-down at the top of the page).
In terms of throughput, we can see from our “RocksDB Write Activity” graph (Read Activity is also graphed) that this compaction required about 33MBps of disk write activity:
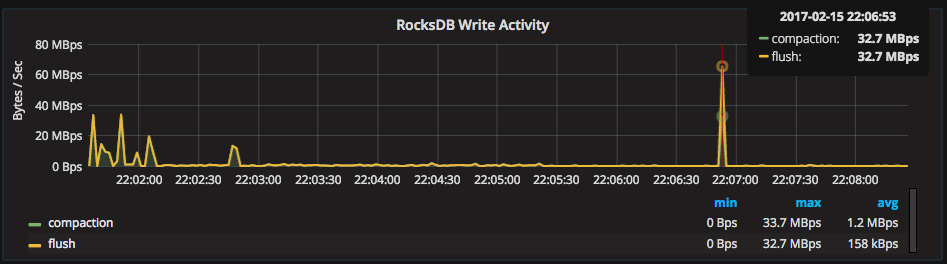
On top of additional resource consumption such as the write activity above, compactions cause caches to get cleared. One example is the OS cache due to new level files being written. These factors can cause some increases to read latencies, demonstrated in this example below by the bump in L4 read latency (top graph) caused by the L4 compaction (bottom graph):
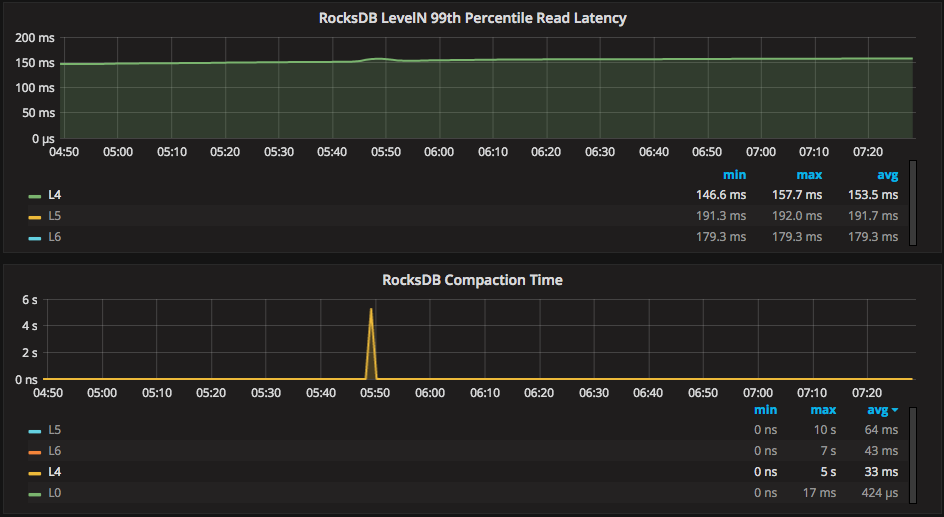
This pattern above is one area to check if you see latency spikes in RocksDB.
RocksDB Stalls
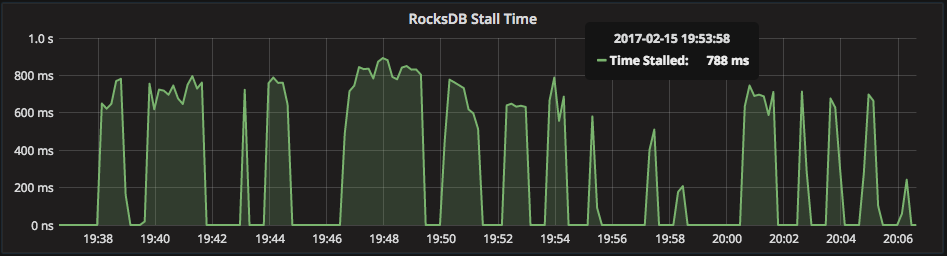
When RocksDB is unable to perform compaction promptly, it uses a feature called “stalls” to try and slow down the amount of data coming into the engine. In my experience, stalls almost always mean something below RocksDB is not up to the task (likely the storage system).
Here is the “RocksDB Stall Time” graph of a host experiencing frequent stalls:
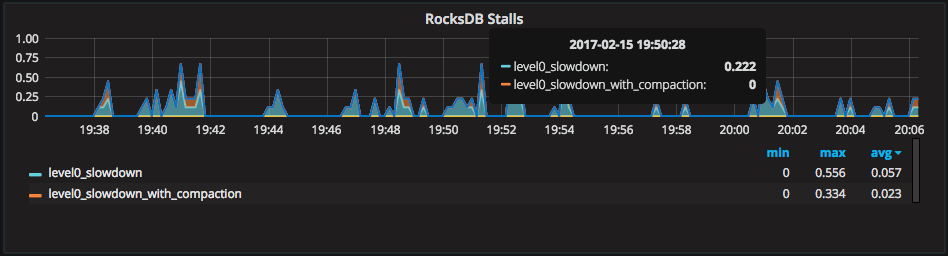
PMM can graph the different types of RocksDB stalls in the “RocksDB Stalls” graph. In our case here, we have 0.3-0.5 stalls per second due to “level0_slowdown” and “level0_slowdown_with_compaction.” This happens when Level0 stalls the engine due to slow compaction performance below its level.
Another metric reflecting the poor compaction performance is the pending compactions in “RocksDB Pending Operations”:
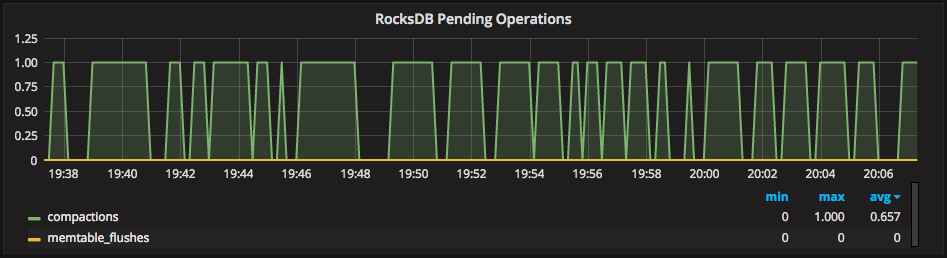
As I mentioned earlier, this almost always means something below RocksDB itself cannot keep up. In the top-right of PMM, we have OS-level metrics in a drop-down, I recommend you look at “Disk Performance” in these scenarios:
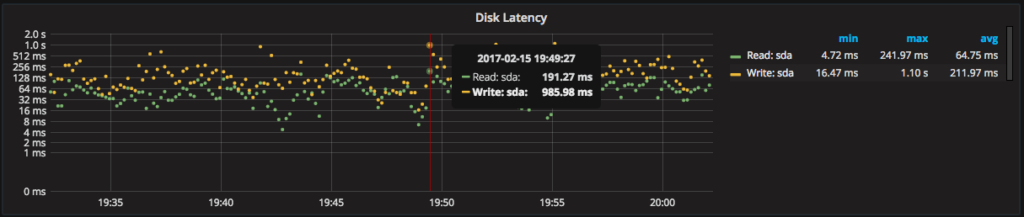
On the “Disk Performance” dashboard you can see the “sda” disk has an average write time of 212ms, and a max of 1100ms (1.1 seconds). This is fairly slow.
Further, on the same dashboard I can see the CPU is waiting on disk I/O 98.70% of the time on average. This explains why RocksDB needs to stall to hold back some of the load!
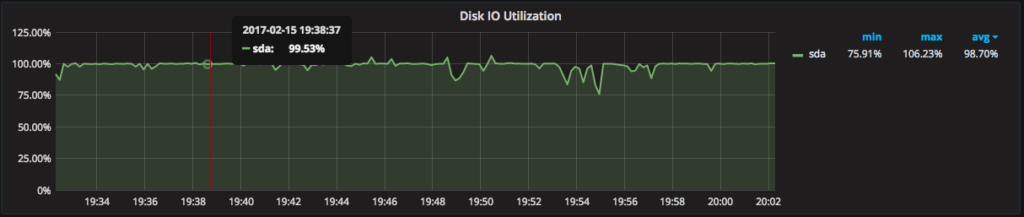
The disks seem too busy to keep up! Looking at the “Mongod – Document Activity” graph, it explains the cause of the high disk usage: 10,000-60,000 inserts per second:
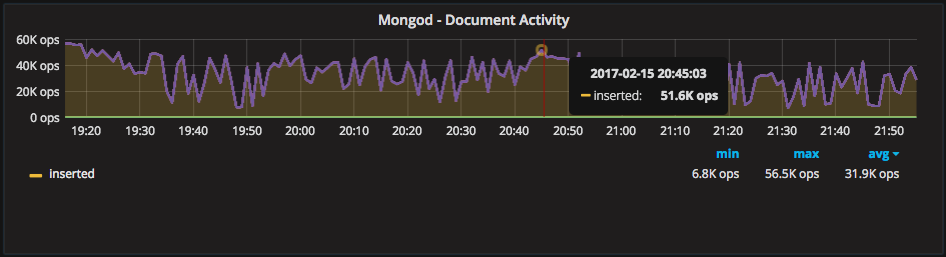
Here we can draw the conclusion that this volume of inserts on this system configuration causes some stalling in RocksDB.
RocksDB Block Cache
The RocksDB Block Cache is the in-heap cache RocksDB uses to cache uncompressed pages. Generally, deployments benefit from dedicating most of their memory to the Linux file system cache vs. the RocksDB Block Cache. We recommend using only 20-30% of the host RAM for block cache.
PMM can take away some of the guesswork with the “RocksDB Block Cache Hit Ratio” graph, showing the efficiency of the block cache:
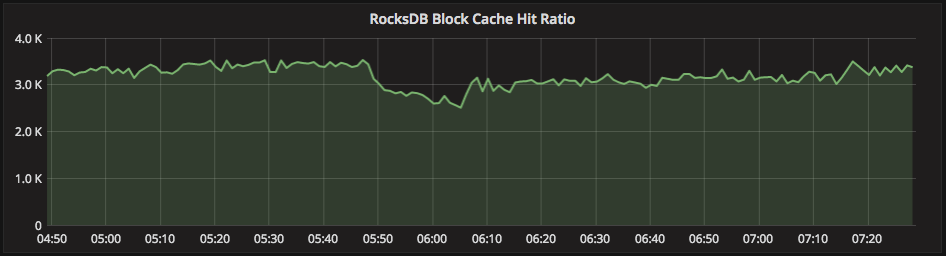
It is difficult to define a “good” and “bad” number for this metric, as the number varies for every deployment. However, one important thing to look for is significant changes in this graph. In this example, the Block Cache has a page in cache 3000 times for every 1 time it does not.
If you wanted to test increasing your block cache, this graph becomes very useful. If you increase your block cache and do not see an improvement in the hit ratio after a lengthy period of testing, this usually means more block cache memory is not necessary.
RocksDB Read Latency Graphs
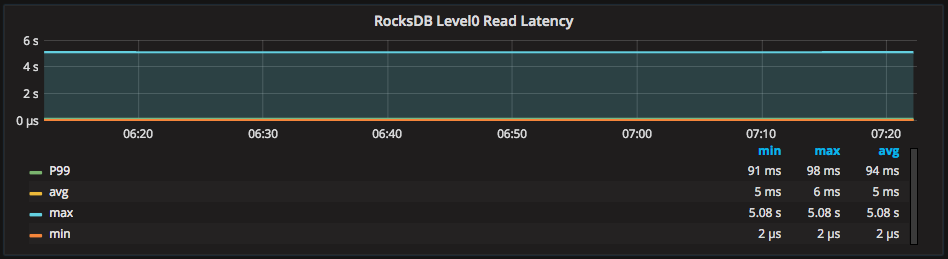
PMM graphs Read Latency metrics for RocksDB in several different graphs, one dedicated to Level0:
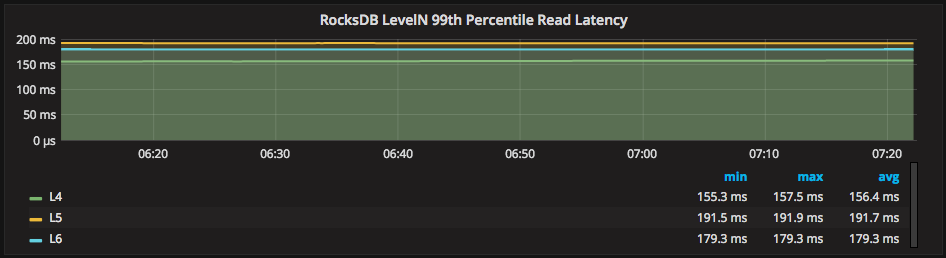
And three other graphs display Average, 99th Percentile and Maximum latencies for each RocksDB level. Here is an example from the 99th Percentile latency metrics:
Coming Soon
Percona Monitoring and Management needs to add some more metrics that explain the performance of the engine. The rate of deletes/tombstones in the system affects RocksDB’s performance. Currently, this metric is not something our system can easily gather like other engine metrics. Percona Monitoring and Management can’t easily graph the efficiency of the Bloom filter yet, either. These are currently open feature requests to the MongoRocks (and likely RocksDB) team(s) to add in future versions.
Percona’s release of Percona Server for MongoDB 3.4 includes a new, improved version of MongoRocks and RocksDB. More is available in the release notes!
Resources
RELATED POSTS





This is awesome