
This is the fourth post in our MySQL Fabric series. In case you’re joining us now, we started with an introductory post, and then discussed High Availability (HA) using MySQL Fabric here (Part 1) and here (Part 2). Today we will talk about how MySQL Fabric can help you scale out MySQL databases with sharding.
At the time of writing, MySQL Fabric includes support for range- and hash-based sharding. As with HA, the functionality is split between client, through a MySQL Fabric-aware connector; and server, through the mysqlfabric utility and the XML-RPC server we’ve talked about before.
In this post, we’ll go through the process of setting up a sharded table for use with MySQL Fabric, and then go through some usage examples, again using the Python connector.
In our next post, we’ll talk about shard management operations, and go into more detail about how we can combine the Sharding and HA features of MySQL Fabric.
For our examples, we’ll be using a sharding branch from our vagrant-fabric repository. If you have been following previous posts and already have a local copy of the repo, you can get this one just by running the following command:
|
1 |
git checkout sharding |
from the root of your copy. Bear in mind that the node names are the same in the Vagrantfile, so while in theory just running vagrant provision should be enough, you may have to run vagrant destroy and vagrant up again, if you hit unexpected behavior.
The only difference between this branch and the original one is that you’ll have two mysqld instances per node: one on port 3306 and one on port 13306. This will let us achieve high availability for our shard groups. But don’t worry about that for now, it’s something we’ll discuss more in depth in our next post.
In today’s examples, we’ll be using the three group architecture described by this diagram:
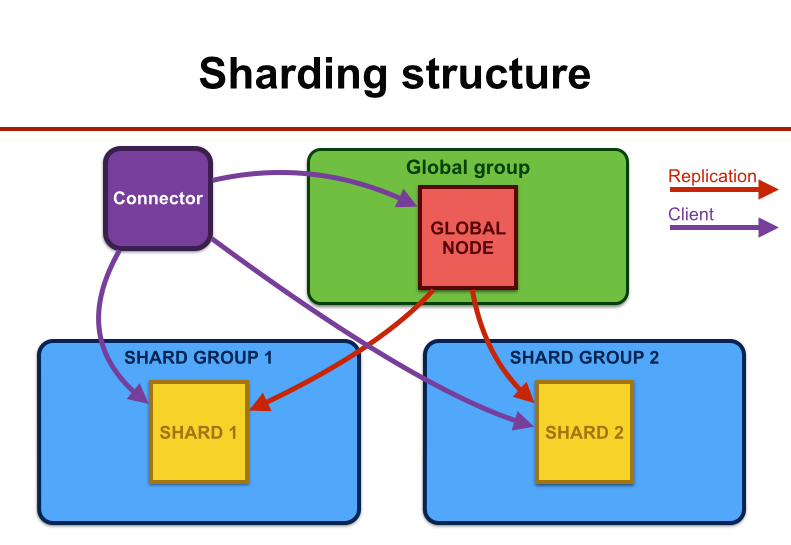
The blue boxes represent shard-groups and the green box represent the global-group. The red arrows indicate the flow of replication and the violet arrows represent client connections.
The official documentation about sharding with MySQL Fabric can be found here. We’ll be using the same example employees database and shard the salaries table.
As we said, to keep things simple for the introduction, we’ll create all the groups but only add one instance to each one of them. In our next post, we’ll use two instances per group to evaluate how MySQL Fabric can make our shards highly available, and how it can rearrange replication topologies automatically after a failure.
To start, let’s create three groups:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[vagrant@store ~]$ mysqlfabric group create salaries-global Procedure : { uuid = 390aa6c0-acda-40e2-ad52-8c0869613635, finished = True, success = True, return = True, activities = } [vagrant@store ~]$ for i in 1 2; do mysqlfabric group create salaries-$i; done Procedure : { uuid = 274742a2-5e84-49b8-8446-5a8fc55f1899, finished = True, success = True, return = True, activities = } Procedure : { uuid = 408cfd6a-ff3a-493e-b39b-a3241d83fda6, finished = True, success = True, return = True, activities = } |
The global group will be used to propagate schema changes and to store unpartitioned data. Think of configuration tables that don’t need to be sharded, for example.
The other two groups will host shards, that is, tables that will have the same structure across all the nodes, but not the same data (and that will be empty in the global group’s nodes).
Now, let’s add one instance to each group:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
[vagrant@store ~]$ mysqlfabric group add salaries-global node1:3306 Procedure : { uuid = 0d0f657c-9304-4e3f-bf5b-a63a5e2e4390, finished = True, success = True, return = True, activities = } [vagrant@store ~]$ mysqlfabric group add salaries-1 node2:3306 Procedure : { uuid = b0ee9a52-49a2-416e-bdfd-eda9a384f308, finished = True, success = True, return = True, activities = } [vagrant@store ~]$ mysqlfabric group add salaries-2 node3:3306 Procedure : { uuid = ea5d8fc5-d4f9-48b1-b349-49520aa74e41, finished = True, success = True, return = True, activities = } |
We also need to promote the groups. Even though each group has a single node, MySQL Fabric sets up that node as SECONDARY, which means it can’t take writes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[vagrant@store ~]$ mysqlfabric group promote salaries-global Procedure : { uuid = 5e764b97-281a-49f0-b486-25088a96d96b, finished = True, success = True, return = True, activities = } [vagrant@store ~]$ for i in 1 2; do mysqlfabric group promote salaries-$i; done Procedure : { uuid = 7814e96f-71d7-4865-a278-cb6ed32a2d11, finished = True, success = True, return = True, activities = } Procedure : { uuid = cd30e9a9-b9ea-4b2d-a8ae-5e70f22363d6, finished = True, success = True, return = True, activities = } |
Finally, we are ready to create a shard definition and associate ranges to groups:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[vagrant@store ~]$ mysqlfabric sharding create_definition RANGE salaries-global Procedure : { uuid = fffcbb5f-24c6-47a2-9348-f1d810c8ef2f, finished = True, success = True, return = 1, activities = } [vagrant@store ~]$ mysqlfabric sharding add_table 1 employees.salaries emp_no Procedure : { uuid = 8d0a3c51-d543-49a6-b47a-36a4ab499ab4, finished = True, success = True, return = True, activities = } [vagrant@store ~]$ mysqlfabric sharding add_shard 1 "salaries-1/1, salaries-2/25000" --state=ENABLED Procedure : { uuid = 2585a5ea-a097-44a4-89fa-a948298d0595, finished = True, success = True, return = True, activities = |
The integer after each shard group is the lower bound for emp_no values found on that shard.
After the last command, the shard groups should be replicating off the global one. We can verify that this is the case by checking salaries-3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
[vagrant@node3 ~]$ mysql -uroot -e 'show slave statusG' *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: node1 Master_User: fabric Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 151 Relay_Log_File: mysqld-relay-bin.000002 Relay_Log_Pos: 361 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 151 Relay_Log_Space: 566 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 870101 Master_UUID: e34ab4cd-00b9-11e4-8ced-0800274fb806 Master_Info_File: /var/lib/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 1 |
Looks good. Let’s go ahead and create the database schema. To avoid being too verbose, we’re only including the create statement for the salaries table in this example. Notice we run this on the PRIMARY node for the global group:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
[vagrant@node1 ~]$ mysql -uroot Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 8 Server version: 5.6.19-log MySQL Community Server (GPL) Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> CREATE DATABASE IF NOT EXISTS employees; Query OK, 1 row affected (0.01 sec) mysql> USE employees; Database changed mysql> CREATE TABLE salaries ( -> emp_no INT NOT NULL, -> salary INT NOT NULL, -> from_date DATE NOT NULL, -> to_date DATE NOT NULL, -> KEY (emp_no)); Query OK, 0 rows affected (0.06 sec) |
And again, check that it made it to the shard groups:
|
1 2 3 4 5 6 7 8 9 |
[vagrant@node2 ~]$ mysql -uroot -e 'show databases' +--------------------+ | Database | +--------------------+ | information_schema | | employees | | mysql | | performance_schema | +--------------------+ |
Good. We’re now ready to use the Python connector and load some data into this table. We’ll be using the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import mysql.connector from mysql.connector import fabric from mysql.connector import errors import time import random import datetime config = { 'fabric': { 'host': 'store', 'port': 8080, 'username': 'admin', 'password': 'admin', 'report_errors': True }, 'user': 'fabric', 'password': 'f4bric', 'database': 'employees', 'autocommit': 'true' } from_min = datetime.datetime(1980,1,1,00,00,00) to_max = datetime.datetime(2014,1,1,00,00,00) fcnx = None print "starting loop" while 1: if fcnx == None: print "connecting" fcnx = mysql.connector.connect(**config) fcnx.reset_cache() try: print "will run query" emp_no = random.randint(1,50000) salary = random.randint(1,200000) from_date = from_min + datetime.timedelta(seconds=random.randint(0, int((to_max - from_min).total_seconds()))) to_date = from_min + datetime.timedelta(seconds=random.randint(0, int((to_max - from_min).total_seconds()))) fcnx.set_property(tables=["employees.salaries"], key=emp_no, mode=fabric.MODE_READWRITE) cur = fcnx.cursor() cur.execute("insert into employees.salaries (emp_no,salary,from_date,to_date) values (%s, %s, %s, %s)",(emp_no,salary,from_date,to_date)) print "inserted", emp_no, ", will now sleep 1 second" time.sleep(1) except (errors.DatabaseError, errors.InterfaceError): print "sleeping 1 second and reconnecting" time.sleep(1) del fcnx fcnx = None |
This is similar to the script we used in our HA post. It inserts rows with random data in an endless loop. The sleep on every iteration is there just to make it easier to cancel the script, and to keep row insert rate under control.
If you leave this running for a while, you should then be able to check the global server and individual shards, and confirm they have different data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[vagrant@store ~]$ for i in 1 2 3; do mysql -ufabric -pf4bric -hnode$i -e "select count(emp_no),max(emp_no) from employees.salaries"; done Warning: Using a password on the command line interface can be insecure. +---------------+-------------+ | count(emp_no) | max(emp_no) | +---------------+-------------+ | 0 | NULL | +---------------+-------------+ Warning: Using a password on the command line interface can be insecure. +---------------+-------------+ | count(emp_no) | max(emp_no) | +---------------+-------------+ | 36 | 24982 | +---------------+-------------+ Warning: Using a password on the command line interface can be insecure. +---------------+-------------+ | count(emp_no) | max(emp_no) | +---------------+-------------+ | 43 | 49423 | +---------------+-------------+ |
As you can see, the global group’s server has no data for this table, and each shard’s server has data within the defined boundaries.
Querying data is done similarly (though with a READ_ONLY connection), and we can also lookup the group a row belongs to using the mysqlfabric utility directly:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[vagrant@store ~]$ mysqlfabric sharding lookup_servers employees.salaries 2045 Command : { success = True return = [['ecab7dd2-00b9-11e4-8cee-0800274fb806', 'node2:3306', True]] activities = } [vagrant@store ~]$ mysqlfabric sharding lookup_servers employees.salaries 142045 Command : { success = True return = [['f8a90096-00b9-11e4-8cee-0800274fb806', 'node3:3306', True]] activities = } |
Bear in mind that this lookups only use the fabric store, which means they can tell you on which servers a given row may be, but can’t confirm if the row exists or not. You need to actually query the given servers for that. If you use the connector, both steps are done for you when you issue the query.
The following code snippets illustrate the point:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>>> fcnx = mysql.connector.connect(**config) >>> emp_no = random.randint(1,50000) >>> fcnx.set_property(tables=["employees.salaries"], key=emp_no, mode=fabric.MODE_READONLY) >>> >>> cur = fcnx.cursor() >>> cur.execute("select count(*) as cnt from employees.salaries where emp_no = %s", (emp_no,)) >>> >>> for row in cur: ... print row ... (0,) >>> fcnx.set_property(tables=["employees.salaries"], key=20734, mode=fabric.MODE_READONLY) >>> cur = fcnx.cursor() >>> cur.execute("select count(*) as cnt from employees.salaries where emp_no = 20734") >>> for row in cur: ... print row ... ... (1,) >>> |
In our examples, we connected directly to the PRIMARY node of the global group in order to execute DDL statements, but the same can be done requesting a global connection to MySQL Fabric, like so:
|
1 2 3 4 |
fcnx.set_property(group="salaries-global",scope=fabric.SCOPE_GLOBAL,mode=fabric.MODE_READWRITE) cur = fcnx.cursor() cur.execute("USE employees") cur.execute("CREATE TABLE test (id int not null primary key)") |
We can see that the table gets replicated as expected:
|
1 2 3 4 5 6 7 |
[vagrant@node3 ~]$ mysql -uroot -e 'show tables from employees' +---------------------+ | Tables_in_employees | +---------------------+ | salaries | | test | +---------------------+ |
Note that we’re explicitly indicating we want to connect to the global group here. When establishing a MySQL Fabric connection, we need to specify either a group name or a key and table pair (as in the insert example).
Today we’ve presented the basics of how MySQL Fabric can help you scale out by sharding, but we’ve intentionally left a few things out of the picture to keep this example simple.
In our next post, we’ll see how we can combine MySQL Fabric’s HA and sharding features, what support we have for shard operations and how HASH sharding works in MySQL Fabric.





Excellent article. Is it possible to show few examples using PHP ?
‘@adam: thank you for taking the time to comment!
We have a follow up post which should go online sometime next week, and while we have been using python for the examples too, I’ll see if we can make it on time with a PHP example.
If that’s not the case, we have a webinar coming up soon (https://www.percona.com/resources/mysql-webinars/putting-mysql-fabric-use) and I’ll make sure to include PHP examples there. We’ll be doing a post announcing it shortly.
I have watched the excellent webinar (Putting MySQL Fabric to Use) but there is no PHP examples.
I also looking forward to examples about connect to a Fabric HA group with PHP.
I create 3 groups, global-group, group_id-1 and group_id-2, then built a shard. Till now, everything is OK. But when i split the shard with a new group named group_id-3, there is an error occurred. The message is as follows:
# mysqlfabric sharding split_shard 2 group_id-3 –split_value=100000
Password for admin:
Procedure :
{ uuid = a0eaff93-f6fe-4a7d-9c44-e7e53882fbfe,
finished = True,
success = False,
return = BackupError: (‘Error while restoring the backup using the mysql clientn, %s’, “ERROR 1840 (HY000) at line 24 in file: ‘MySQL_132.228.239.19_3316.sql’: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.n”),
activities =
}
I run the “reset master” command first, but the error is still there.what is this error?
Regards
Shen
‘@Tim: I have PHP examples on my list. Will do either a blog post or add examples to our vagrant repo. I’ve been away on vacation the last couple of weeks so I don’t yet have an ETA for when this will be published, but it should be soon 🙂
@Shen: It seems you’re hitting http://bugs.mysql.com/bug.php?id=73212. If you think that’s the case, please mark the bug as “affects me”, to help Oracle prioritise it.
Hi, I am trying to create LIST defination i am getting error (ShardingError: Invalid Sharding Type LIST) please help me out… thanks