
In our previous post, we introduced the MySQL Fabric utility and said we would dig deeper into it. This post is the first part of our test of MySQL Fabric’s High Availability (HA) functionality.
Today, we’ll review MySQL Fabric’s HA concepts, and then walk you through the setup of a 3-node cluster with one Primary and two Secondaries, doing a few basic tests with it. In a second post, we will spend more time generating failure scenarios and documenting how Fabric handles them. (MySQL Fabric is an extensible framework to manage large farms of MySQL servers, with support for high-availability and sharding.)
Before we begin, we recommend you read this post by Oracle’s Mats Kindahl, which, among other things, addresses the issues we raised on our first post. Mats leads the MySQL Fabric team.
All our tests will be using our test environment with Vagrant (https://github.com/percona/vagrant-fabric)
If you want to play with MySQL Fabric, you can have these VMs running in your desktop following the instructions in the README file. If you don’t want full VMs, our colleague Jervin Real created a set of wrapper scripts that let you test MySQL Fabric using sandboxes.
Here is a basic representation of our environment.
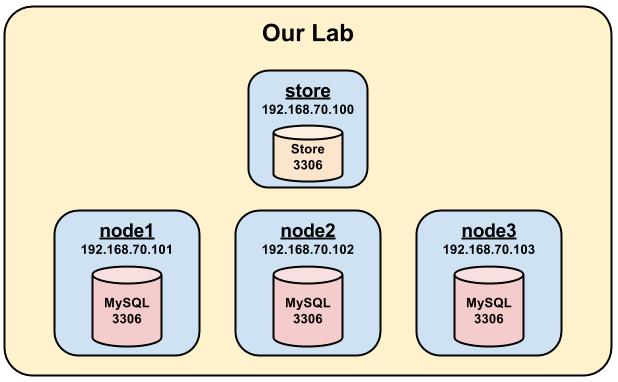
To set up MyQSL Fabric without using our Vagrant environment, you can follow the official documentation, or check the ansible playbooks in our lab repo. If you follow the manual, the only caveat is that when creating the user, you should either disable binary logging for your session, or use a GRANT statement instead of CREATE USER. You can read here for more info on why this is the case.
A description of all the options in the configuration file can be found here. For HA tests, the one thing to mention is that, in our experience, the failure detector will only trigger an automatic failover if the value for failover_interval in the [failure_tracking] section is greater than 0. Otherwise, failures will be detected and written to the log, but no action will be taken.
In order to manage a mysqld instance with MySQL Fabric, the following options need to be set in the [mysqld] section of its my.cnf file:
|
1 2 3 4 |
log_bin gtid-mode=ON enforce-gtid-consistency log_slave_updates |
Additionally, as in any replication setup, you must make sure that all servers have a distinct server_id.
When everything is in place, you can setup and start MySQL Fabric with the following commands:
|
1 2 |
[vagrant@store ~]$ mysqlfabric manage setup [vagrant@store ~]$ mysqlfabric manage start --daemon |
The setup command creates the database schema used by MySQL Fabric to store information about managed servers, and the start one, well, starts the daemon. The –daemon option makes Fabric start as a daemon, logging to a file instead of to standard output. Depending on the port and file name you configured in fabric.cfg, this may need to be run as root.
While testing, you can make MySQL Fabric reset its state at any time (though it won’t change existing node configurations such as replication) by running:
|
1 2 |
[vagrant@store ~]$ mysqlfabric manage teardown [vagrant@store ~]$ mysqlfabric manage setup |
If you’re using our Vagrant environment, you can run the reinit_cluster.sh script from your host OS (from the root of the vagrant-fabric repo) to do this for you, and also initialise the datadir of the three instances.
A High Availability Cluster is a set of servers using the standard Asynchronous MySQL Replication with GTID.
The first step is to create the group by running mysqlfabric with this syntax:
|
1 |
$ mysqlfabric group create <group_name> |
In our example, to create the cluster “mycluster” you can run:
|
1 2 3 4 5 6 7 8 |
[vagrant@store ~]$ mysqlfabric group create mycluster Procedure : { uuid = 605b02fb-a6a1-4a00-8e24-619cad8ec4c7, finished = True, success = True, return = True, activities = } |
The second step is add the servers to the group. The syntax to add a server to a group is:
|
1 |
$ mysqlfabric group add <group_name> <host_name or IP>[:port] |
The port number is optional and only required if distinct from 3306. It is important to mention that the clients that will use this cluster must be able to resolve this host or IP. This is because clients will connect directly both with MySQL Fabric’s XML-PRC server and with the managed mysqld servers. Let’s add the nodes to our group.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[vagrant@store ~]$ for i in 1 2 3; do mysqlfabric group add mycluster node$i; done Procedure : { uuid = 9d65c81c-e28a-437f-b5de-1d47e746a318, finished = True, success = True, return = True, activities = } Procedure : { uuid = 235a7c34-52a6-40ad-8e30-418dcee28f1e, finished = True, success = True, return = True, activities = } Procedure : { uuid = 4da3b1c3-87cc-461f-9705-28a59a2a4f67, finished = True, success = True, return = True, activities = } |
Now that we have all our nodes in the group, we have to promote one of them. You can promote one specific node or you can let MySQL Fabric to choose one for you.
The syntax to promote a specific node is:
|
1 |
$ mysqlfabric group promote <group_name> --slave_id='<node_uuid>' |
or to let MySQL Fabric pick one:
|
1 |
$ mysqlfabric group promote <group_name> |
Let’s do that:
|
1 2 3 4 5 6 7 8 |
[vagrant@store ~]$ mysqlfabric group promote mycluster Procedure : { uuid = c4afd2e7-3864-4b53-84e9-04a40f403ba9, finished = True, success = True, return = True, activities = } |
You can then check the health of the group like this:
|
1 2 3 4 5 6 |
[vagrant@store ~]$ mysqlfabric group health mycluster Command : { success = True return = {'e245ec83-d889-11e3-86df-0800274fb806': {'status': 'SECONDARY', 'is_alive': True, 'threads': {}}, 'e826d4ab-d889-11e3-86df-0800274fb806': {'status': 'SECONDARY', 'is_alive': True, 'threads': {}}, 'edf2c45b-d889-11e3-86df-0800274fb806': {'status': 'PRIMARY', 'is_alive': True, 'threads': {}}} activities = } |
One current limitation of the ‘health’ command is that it only identifies servers by their uuid. To get a list of the servers in a group, along with quick status summary, and their host names, use lookup_servers instead:
|
1 2 3 4 5 6 |
[vagrant@store ~]$ mysqlfabric group lookup_servers mycluster Command : { success = True return = [{'status': 'SECONDARY', 'server_uuid': 'e245ec83-d889-11e3-86df-0800274fb806', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': 'node1'}, {'status': 'SECONDARY', 'server_uuid': 'e826d4ab-d889-11e3-86df-0800274fb806', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': 'node2'}, {'status': 'PRIMARY', 'server_uuid': 'edf2c45b-d889-11e3-86df-0800274fb806', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': 'node3'}] activities = } |
We sent a merge request to use a Json string instead of the “print” of the object in the “return” field from the XML-RPC in order to be able to use that information to display the results in a friendly way. In the same merge, we have added the address of the servers in the health command too.
Now we have the three lab machines set up in a replication topology of one master (the PRIMARY server) and two slaves (the SECONDARY ones). To make MySQL Fabric start monitoring the group for problems, you need to activate it:
|
1 2 3 4 5 6 7 8 |
[vagrant@store ~]$ mysqlfabric group activate mycluster Procedure : { uuid = 230835fc-6ec4-4b35-b0a9-97944c18e21f, finished = True, success = True, return = True, activities = } |
Now MySQL Fabric will monitor the group’s servers, and depending on the configuration (remember the failover_interval we mentioned before) it may trigger an automatic failover. But let’s start testing a simpler case, by stopping mysql on one of the secondary nodes:
|
1 2 |
[vagrant@node2 ~]$ sudo service mysqld stop Stopping mysqld: [ OK ] |
And checking how MySQL Fabric report’s the group’s health after this:
|
1 2 3 4 5 6 |
[vagrant@store ~]$ mysqlfabric group health mycluster Command : { success = True return = {'e245ec83-d889-11e3-86df-0800274fb806': {'status': 'SECONDARY', 'is_alive': True, 'threads': {}}, 'e826d4ab-d889-11e3-86df-0800274fb806': {'status': 'FAULTY', 'is_alive': False, 'threads': {}}, 'edf2c45b-d889-11e3-86df-0800274fb806': {'status': 'PRIMARY', 'is_alive': True, 'threads': {}}} activities = } |
We can see that MySQL Fabric successfully marks the server as faulty. In our next post we’ll show an example of this by using one of the supported connectors to handle failures in a group, but for now, let’s keep on the DBA/sysadmin side of things, and try to bring the server back online:
|
1 2 3 4 5 6 7 8 |
[vagrant@node2 ~]$ sudo service mysqld start Starting mysqld: [ OK ] [vagrant@store ~]$ mysqlfabric group health mycluster Command : { success = True return = {'e245ec83-d889-11e3-86df-0800274fb806': {'status': 'SECONDARY', 'is_alive': True, 'threads': {}}, 'e826d4ab-d889-11e3-86df-0800274fb806': {'status': 'FAULTY', 'is_alive': True, 'threads': {}}, 'edf2c45b-d889-11e3-86df-0800274fb806': {'status': 'PRIMARY', 'is_alive': True, 'threads': {}}} activities = } |
So the server is back online, but Fabric still considers it faulty. To add the server back into rotation, we need to look at the server commands:
|
1 2 3 4 5 6 7 |
[vagrant@store ~]$ mysqlfabric help server Commands available in group 'server' are: server set_weight uuid weight [--synchronous] server lookup_uuid address server set_mode uuid mode [--synchronous] server set_status uuid status [--update_only] [--synchronous] |
The specific command we need is set_status, and in order to add the server back to the group, we need to change it’s status twice: first to SPARE and then back to SECONDARY. You can see what happens if we try to set it to SECONDARY directly:
|
1 2 3 4 5 6 7 8 |
[vagrant@store ~]$ mysqlfabric server set_status e826d4ab-d889-11e3-86df-0800274fb806 SECONDARY Procedure : { uuid = 9a6f2273-d206-4fa8-80fb-6bce1e5262c8, finished = True, success = False, return = ServerError: Cannot change server's (e826d4ab-d889-11e3-86df-0800274fb806) status from (FAULTY) to (SECONDARY)., activities = } |
So let’s try it the right way:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[vagrant@store ~]$ mysqlfabric server set_status e826d4ab-d889-11e3-86df-0800274fb806 SPARE Procedure : { uuid = c3a1c244-ea8f-4270-93ed-3f9dfbe879ea, finished = True, success = True, return = True, activities = } [vagrant@store ~]$ mysqlfabric server set_status e826d4ab-d889-11e3-86df-0800274fb806 SECONDARY Procedure : { uuid = 556f59ec-5556-4225-93c9-b9b29b577061, finished = True, success = True, return = True, activities = } |
And check the group’s health again:
|
1 2 3 4 5 6 |
[vagrant@store ~]$ mysqlfabric group health mycluster Command : { success = True return = {'e245ec83-d889-11e3-86df-0800274fb806': {'status': 'SECONDARY', 'is_alive': True, 'threads': {}}, 'e826d4ab-d889-11e3-86df-0800274fb806': {'status': 'SECONDARY', 'is_alive': True, 'threads': {}}, 'edf2c45b-d889-11e3-86df-0800274fb806': {'status': 'PRIMARY', 'is_alive': True, 'threads': {}}} activities = } |
In our next post, when we discuss how to use the Fabric aware connectors, we’ll also test other failure scenarios like hard VM shutdown and network errors, but for now, let’s try the same thing but on the PRIMARY node instead:
|
1 2 |
[vagrant@node3 ~]$ sudo service mysqld stop Stopping mysqld: [ OK ] |
And let’s check the servers again:
|
1 2 3 4 5 6 |
[vagrant@store ~]$ mysqlfabric group lookup_servers mycluster Command : { success = True return = [{'status': 'SECONDARY', 'server_uuid': 'e245ec83-d889-11e3-86df-0800274fb806', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': 'node1'}, {'status': 'PRIMARY', 'server_uuid': 'e826d4ab-d889-11e3-86df-0800274fb806', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': 'node2'}, {'status': 'FAULTY', 'server_uuid': 'edf2c45b-d889-11e3-86df-0800274fb806', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': 'node3'}] activities = } |
We can see that MySQL Fabric successfully marked node3 as FAULTY, and promoted node2 to PRIMARY to resolve this. Once we start mysqld again on node3, we can add it back as SECONDARY using the same process of setting it’s status to SPARE first, as we did for node2 above.
Remember that unless failover_interval is greater than 0, MySQL Fabric will detect problems in an active group, but it won’t take any automatic action. We think it’s a good thing that the value for this variable in the documentation is 0, so that automatic failover is not enabled by default (if people follow the manual, of course), as even in mature HA solutions like Pacemaker, automatic failover is something that’s tricky to get right. But even without this, we believe the main benefit of using MySQL Fabric for promotion is that it takes care of reconfiguring replication for you, which should reduce the risk for error in this process, specially once the project becomes GA.
In this post we’ve presented a basic replication setup managed by MySQL Fabric and reviewed a couple of failure scenarios, but many questions are left unanswered, among them:
We’ll try to answer these and other questions in our next post. If you have some questions of your own, please leave them in the comments section and we’ll address them in the next or other posts, depending on the topic.
Resources
RELATED POSTS





Hi,
I am facing the following issue while adding mysql instance into the group
mysqlfabric group create group1 192.168.0.211:3306
Result:
success : false
return : server error : Error Accessing Server (192.168.0.211:3306)
What could be the reasons.
Waiting for your positive reply
Regards
MWM
‘@MWM: The group create command does not need a host, so just:
> mysqlfabric group create group1
should work.
You can check the help to confirm this on your version:
> [vagrant@store ~]$ mysqlfabric help group create
> group create group_id [–description=NONE] [–synchronous]
>
> Create a group.
That said, if you experience this error with other commands (like mysqlfabric group add group1 192.168.0.211:3306), my guess would be that either the fabric user is missing on that mysqld instance, or that it does not allow connections from the host you’re running the mysqlfabric command.
You can verify what IP or host name this is if you have the error log enabled on the 0.211:3306 server and you set log_warnings to something greater than 1 (see http://dev.mysql.com/doc/refman/5.6/en/server-system-variables.html#sysvar_log_warnings for a full description).
Dear Fernando,
Thank you for replying.
You are right, I mistakenly wrote “create” instead of “add” in the question.
Secondly, my machine @192.168.0.211 allows connection with user and password. So, issue was with the fabric.cfg file. I did’nt give any value against ‘password’ parameter of [servers] section.
After setting the above mentioned parameter, utility allowed to add MySQL instance into the group.
Regards
MWM
[root@store vagrant]# mysqlfabric manage start –daemon
mysqlfabric: error: no such option: –daemon
This is having pulled down the git repo and following the instructions… Perhaps the documentation needs to be updated?
‘@Drew:
This is due to this: http://bugs.mysql.com/bug.php?id=72818
But you’re right, while this is not resolved, we need to update the instructions. Just running mysqlfabric manage start should be enough, though it will stay attached to your stdin/stdout, so you may want to use nohup and redirect the output to a log file instead.
When I use the following command
“mysqlfabric group promote –slave_uuid=””,
I got mysqlfabric: error: no such option: –slave_uuid.
The command sould be
“mysqlfabric group promote –slave_id=””.
Am I right?
‘@Tim:
You’re right, thanks for pointing that out!
I’ve corrected the example.
‘@martin Arrieta and Fernando Ipar and @ALL fabric enthusiast,
Nice blog, am playing around HA aspect of Fabric and am struck. I have backing store and 3 mysql nodes on different machines. i created fabric user on backing store to access fabric database and fabric user on mysql nodes for fabric system to connect to mysql nodes. i created ha group and added 3 hosts to the group. when i promote the group the selection of master based on our choice and also auto pick is doing great. The problem starts with the secondary nodes. They are trying to connect to master using user fabric@masterhost(mysql host that is picked as primary when i promoted the group) and having error ‘io_running’: False, ‘io_error’: “error connecting to master ‘fabric@masterhost:3306. Funny part when i do show slave status on secondary nodes i see slave_SQL_running=yes, slave_IO_running says connecting and Last_IO_Error: error connecting to master ‘fabric@masterhostname:3306’ – retry-time: 60 retries: 4.
I may be missing the step of setting up user credentials in fabric.cfg for servers to use for setting up replication among the ha group hosts. Any help is appreciated.
Thanks
DL
‘@Lakshma:
Thanks for taking the time to comment.
You’re right in that you’re probably missing a step while setting up credentials. I’d start looking at the error log on the (elected) master node, with @@log_warnings > 1 (i.e. run “set @@global.log_warnings=2;” on it, as root).
With that variable set, you should see failed connection attempts in the error log, which should help you create any needed user. After setting this variable, error log messages should look like this:
140813 18:55:54 [Warning] Access denied for user ‘test’@’localhost’ (using password: YES)
Hmm, well… I had this working earlier in the week. I did a vagrant destroy and now can’t remake a fabric group for the life of me. I did modify /etc/my.cnf on the store machine. Anyone have any ideas?
[vagrant@store ~]$ mysqlfabric manage setup
[INFO] 1411662261.237829 – MainThread – Initializing persister: user (store), server (localhost:3306), database (fabric).
Error: (“Command (CREATE DATABASE fabric, ()) failed: 1007 (HY000): Can’t create database ‘fabric’; database exists”, 1007)
[vagrant@store ~]$ nohup mysqlfabric manage start &
[1] 10331
[vagrant@store ~]$ nohup: ignoring input and appending output to `nohup.out’
mysqlfabric group create mycluster
[Errno 111] Connection refused
[1]+ Exit 2 nohup mysqlfabric manage start
‘@paul: I have the same problem as you, and the problem is that mysqlfabric manage start is not working. Take a look at your nohup.out file and you should find an error similar like this:
mysqlfabric: error: Wrong number of parameters were provided for command ‘manage start’.
Fabric is a rapidly changing project and it seems as part of fixing http://bugs.mysql.com/bug.php?id=72818 something else broke. Unfortunately, we are not specifying a version number in our playbooks and so the latest release is always installed.
I don’t have time to fix this right now, but I’ll try to do this during the weekend, and I’ll changa the playbook to always get the same version number so at least it is consistent with examples.
‘@paul: If that was indeed your problem, you can click ‘Affects me’ on http://bugs.mysql.com/bug.php?id=74086
Yep, that’s exactly my problem. Which would explain the behavior I saw. Thanks!
I did try MySQL Utilities 1.5.1 rc briefly yesterday as it’s supposed to fix the connect –daemonize issue. I didn’t and don’t have the time to trace down all the other pieces that would have needed to be upgraded.
‘@paul: Can you please check and see if this fixes your problem?: https://github.com/percona/vagrant-fabric
Looks like the only thing you updated is the fabric.cfg file. Which you have:
[connector]
ttl = 1
in twice with the only difference being whitespace. Not sure if you meant to do that.
I’m not running 1.5.1 ATM. Just the fabric.cfg change didn’t fix anything for me. If I get time, I’ll update the MySQL Utilities again and give it another try.
‘@paul: Which branch are you using? You should get this contents added to the cfg file too:
[protocol.mysql]
disable_authentication = no
ssl_cert =
ssl_key =
ssl_ca =
user = admin
address = localhost:32275
password =
‘@paul: Now that I read your comment again, my last change will only help you if running Fabric 1.5. That’s what you should get if you run ‘vagrant provision store’ while being up to date on either the ‘sharding’ or ‘master’ branches of the new repo.
When you have a moment to test this, please let me know how it goes.
Hmm, I assumed it would pull down 1.4 again. I haven’t provisioned my servers again. Too busy patching bash on servers where I’m not allowed to run ansible.
Anyway my statement was poor. I do have those changes in the cfg file. I also noticed
[connector]
ttl = 1
in the file twice, which I assume is a mistake, and I was trying to point out.
‘@paul: You were right to expect me to pull down 1.4 again, since that’s what I told you in a previous comment 🙂
The thing is that between then and now, 1.5 went GA so I think it’s best if I stick to that in a test environment, otherwise we’ll all be testing old software. One specific benefit is that on 1.5, Connector/J finally works, while on 1.4 I was hitting a bug that prevented me from even establishing a connection, for example.
Thanks for clarifying your comment about the [connector] section, that’s obviously a paste error on my side which I’ll fix soon.
I expected to get 1.4 again since when I grabbed 1.5 on Thursday or Friday it was still RC 😀
Anyway, I get the following when I try and start mysqlfabric manage start –daemonize (After doing the setup). It’s a new error, so progress. I’ll play with it some tonight
“Error: Command (SELECT password, username, protocol, user_id FROM users WHERE username = %s AND protocol = %s, (‘admin’, ‘mysql’)) failed accessing (localhost:3306). 1146 (42S02): Table ‘fabric.users’ doesn’t exist.”
mysqlfabric manage setup was returning:
“Error: Command (CREATE DATABASE fabric, ()) failed accessing (localhost:3306). 1007 (HY000): Can’t create database ‘fabric’; database exists.”
I’ll try deleting the local db in the store, rerunning setup.
Is what I get now on freshly provisioned servers after a destroy.
‘@paul: That error does seem like you’re running Fabric 1.5 against a store created by 1.4, so I’d try ‘mysqlfabric manage teardown’ and then ‘mysqlfabric manage setup’ again.
If you’re using the Vagrant env, there’s a script that erases everything (including datadir), to start from scratch without having to reinstall the nodes. It’s called reinit_cluster.sh
Hi Fernando,
I wasn’t using vagrant environment, but created the same fabric setup that you have created.
I created the clusters, added the nodes to cluster and automatically promoted the clusters. The setup was up and running
But even before I executed “mysqlfabric group activate mycluster” fabric stared monitoring the nodes, and when I stopped one of the nodes and executed “mysqlfabric group health mycluster” it showed faulty. And when I started the node fabric automatically showed the node is healthy.
I didn’t have to execute the steps “set status to SPARE and SECONDARY” so that fabric shows the status is healthy.
Is it something to do with different versions of fabric( I used 1.5, going to try 1.4)
–Aravinth
Update to my previous question.
After some testing found what “mysqlfabric group health mycluster” soes. This command actually enables the automatic failover and not failover_interval > 0.
Even if “failover_interval=0” automatic failover happens
So after failover activation it is necessary to manually “set status to SPARE and SECONDARY”
Fernando,
Kindly correct me if I am wrong
–Aravinth
‘@Aravinth: Thank you for commenting. My understanding is that what enables failover is “mysqlcluster group promote mycluster”, but I have not done a lot of tests with 1.5 yet.
I’ll test this sometime this week and will get back to you on this.
Hi Fernando:
I have two slaves , slave1 and slave2 , I want fabric to choose slave1 as first candidate when failover or switchover happens .
how can I configure the sersers?
Sorry that I had made a typo in my previous comment. I had commented that “mysqlcluster group promote mycluster” enables automatic fail-over.
But it is the command “mysqlfabric group activate mycluster” enables automatic fail-over regardless of setting “failover_interval ” to 0 or greater than 0.
–Aravinth
When can we safely purge the binary logs on the slaves?
I think binary logs on slaves would only be needed if it gets promoted as master, and in that case, having enough to cover the max possible lag across all slaves should be enough. In theory, I think expire_logs_days at a few days (say 7) should be more than enough.
Having said that, unless you have pressing disk space issues, I’d just use the same configuration across all nodes and hence the same value as on the master, and on a master, you may want to keep binlogs available for longer if possible (even with monitoring in place, it’s not uncommon for me to find cases where replication on a slave has been stopped for a few days without anyone noticing, and if expire_logs_days is too low on the master then you’d have to rebuild such slave instead).
Thank you very much!
hi!
I just started to deploy your lab with vagrant and it gives me an error
TASK: [Disable binary logging due to http://bugs.mysql.com/bug.php?id=72281. This does a SET GLOBAL so it’s only meant to be run on test servers] ***
REMOTE_MODULE mysql_variables login_user=root login_password=VALUE_HIDDEN variable=sql_log_bin value=0
failed: [node1] => {“changed”: false, “failed”: true}
msg: (1231, “Variable ‘sql_log_bin’ can’t be set to the value of ‘0’”)
FATAL: all hosts have already failed — aborting
It is normal? How can I fix that?
Thanks!
‘@Ruben:
Thanks for trying this, and I’m sorry you hit this right away!
This is due to http://bugs.mysql.com/bug.php?id=67433
It’s a good problem to have though, as it’s good that they fix that bug 🙂
I’ve updated the playbook and it seems to work for me now (I only tried node1, but all mysql nodes are provisioned the same way so it should be ok). Please pull the latest version and try again, and let me know if you still have problems.
Forgot to say, the reason we were doing a set global on that is that we were using http://docs.ansible.com/mysql_variables_module.html, which only manages global variables.
The reason we needed that was due to a bug in Fabric that may have been fixed by now (http://bugs.mysql.com/bug.php?id=72281) but just in case, instead of messing with sql_log_bin, I’m now manually creating the users implicitly via GRANT, instead of with CREATE, which should not break replication.
Wow, excellent news! Nice job! 😀
Hi,
I am not able to change the FAULTY to Spare and it is giving some error but no much informative.
mysqlfailoverconsole:/home # mysqlfabric group lookup_servers HAmysqlgroup
Fabric UUID: 5ca1ab1e-a007-feed-f00d-cab3fe13249e
Time-To-Live: 1
server_uuid address status mode weight
———————————— ————- ——- ———- ——
58074de4-dc82-11e4-a618-fa163ec495d8 10.52.201.11 PRIMARY READ_WRITE 1.0
e764fe3f-dc73-11e4-a5ba-fa163eed3b8d 10.52.201.101 FAULTY READ_WRITE 1.0
mysqlfailoverconsole:/home # mysqlfabric server set_status 10.52.201.101 spare
Fabric UUID: 5ca1ab1e-a007-feed-f00d-cab3fe13249e
Time-To-Live: 1
ServerError: Error trying to configure server (e764fe3f-dc73-11e4-a5ba-fa163eed3b8d) as slave: Command (STOP SLAVE , ()) failed accessing (10.52.201.101:3306). MySQL Connection not available…
Am i missing something here?
-Ravi
SPARE AND SECONDARY must be in capital letters with set_status command.
Hello Ravi,
The error message just indicates a failure from Fabric to establish a connection to the node.
Can you connect to it using MySQL’s CLI?
i am flowing blog : https://schlueters.de/blog/archives/175-Sharding-PHP-with-MySQL-Fabric.html
Error :
Warning: mysqlnd_ms_fabric_select_global(http://localhost:8080/): failed to open stream: Permission denied in /var/www/html/test.php on line 22
Warning: mysqlnd_ms_fabric_select_global(): Didn’t receive usable servers from MySQL Fabric in /var/www/html/test.php on line 22
Warning: mysqli::query(): (mysqlnd_ms) Couldn’t find the appropriate master connection. 0 masters to choose from. Something is wrong in /var/www/html/test.php on line 26
Warning: mysqli::query(): (mysqlnd_ms) No connection selected by the last filter in /var/www/html/test.php on line 26 [2000] (mysqlnd_ms) No connection selected by the last filter
fabric.json file :
{
“myapp”: {
“fabric”: {
“hosts”: [
{
“host” : “localhost”,
“port” : 8080
}
],
“trx_warn_serverlist_changes” : 1
},
“trx_stickiness”: “on”
}
}
also i have notice mysqlfabric command response in my case is like
::::: mysqlfabric manage ping
Fabric UUID: 5ca1abde-a0107-feed-f00d-cab3fd45249e
Time-To-Live: 1
Success (empty result set)
other response
[mysql@fab1 ~]$ mysqlfabric manage ping
Command :
{ success = True
return = True
activities =
}
what is difference in both and how to remove these error
Hi,
Error when run “mysqlfabric group add my_group “: ServerError: Error accessing server (ipaddress): 1045 (28000): Access denied for user ‘fabric_server’@’ipaddress’ (using password: YES).
Please!
hi, have you resolved your issue please?
i have exactly the same. and i made sure credential worked from node1:
node1>mysql -ufabric -p -h10.1.30.97
Enter password:
mysql>
however,
mysqlfabric group add group_id-1 10.1.30.97:3306
still failed:
ServerError: Error accessing server (10.1.30.97:3306): 1045 (28000): Access denied for user ‘fabric’@’10.1.30.96’ (using password: NO).
please help.
thanks a lot in advance
Hello James. Can you reply with the output to ‘show grants’, from a connection established via the CLI, as the one you demonstrate from node1?
Thanks.
Hi Fernado,
My issue resolved, trial and error:
just set all password = “mysecretypasswd” in /etc/mysql/fabric.cfg
Thanks
Thanks for letting me know!
Hi,
Error when run “mysqlfabric group add my_group “: ServerError: Server (55723d64-a495-11e5-8fb0-0800272ca670) does not have the binary log or gtid enabled.
Please!
‘@Phuong, The blog is not the best way to get help, so I’d suggest that you use our forums instead (https://www.percona.com/forums/). That said, I think:
– Your first error may just be a privileges problem. I’d look into that before considering other possibilities (like a bug). For example, the docs always use ‘localhost’ (see https://dev.mysql.com/doc/mysql-utilities/1.4/en/fabric-create-user.html), and that won’t let you authenticate from ‘ipaddress’. Did you explicitly create the ‘fabric_server’@’ipaddress’ account, with the required privileges? Remember on MySQL, a ‘user’ is the combination of user and host. fabric_server@localhost and fabric_server@ipaddress are two independent users that may have different privileges (or one of them may not exist.
– Your second error may also be just what it says. In order to use Fabric, the servers must be configured with binary logging and gtid enabled. Did you add the lines specified on this post to your servers’ my.cnf file? If you did, and you get this message from fabric, check the server’s error log to see if maybe one of the options is not being used for some reason (can be a typo, etc).
Hi Fernado,
Please see my reply to Phuong. and please shed some light.
Thanks a lot in advance
James
Can some one see why this is coming when I try to add server to the group
linux@linux08:~$ sudo mysqlfabric group add groupname 10.0.0.208:3306
Password for admin:
Traceback (most recent call last):
File “/usr/local/bin/mysqlfabric”, line 451, in
sys.exit(main())
File “/usr/local/bin/mysqlfabric”, line 434, in main
return fire_command(cmd, *cargs)
File “/usr/local/bin/mysqlfabric”, line 362, in fire_command
result = command.dispatch(*(command.append_options_to_args(args)))
File “/usr/local/lib/python2.7/dist-packages/mysql/fabric/command.py”, line 549, in dispatch
return self.client.dispatch(self, *args)
File “/usr/local/lib/python2.7/dist-packages/mysql/fabric/protocols/xmlrpc.py”, line 818, in dispatch
packet = getattr(self, reference)(*args)
File “/usr/lib/python2.7/xmlrpclib.py”, line 1233, in __call__
return self.__send(self.__name, args)
File “/usr/lib/python2.7/xmlrpclib.py”, line 1587, in __request
verbose=self.__verbose
File “/usr/local/lib/python2.7/dist-packages/mysql/fabric/protocols/xmlrpc.py”, line 753, in request
result = opener.open(req)
File “/usr/lib/python2.7/urllib2.py”, line 410, in open
response = meth(req, response)
File “/usr/lib/python2.7/urllib2.py”, line 523, in http_response
‘http’, request, response, code, msg, hdrs)
File “/usr/lib/python2.7/urllib2.py”, line 442, in error
result = self._call_chain(*args)
File “/usr/lib/python2.7/urllib2.py”, line 382, in _call_chain
result = func(*args)
File “/usr/lib/python2.7/urllib2.py”, line 1085, in http_error_401
host, req, headers)
File “/usr/lib/python2.7/urllib2.py”, line 970, in http_error_auth_reqed
return self.retry_http_digest_auth(req, authreq)
File “/usr/lib/python2.7/urllib2.py”, line 981, in retry_http_digest_auth
resp = self.parent.open(req, timeout=req.timeout)
File “/usr/lib/python2.7/urllib2.py”, line 404, in open
response = self._open(req, data)
File “/usr/lib/python2.7/urllib2.py”, line 422, in _open
‘_open’, req)
File “/usr/lib/python2.7/urllib2.py”, line 382, in _call_chain
result = func(*args)
File “/usr/lib/python2.7/urllib2.py”, line 1214, in http_open
return self.do_open(httplib.HTTPConnection, req)
File “/usr/lib/python2.7/urllib2.py”, line 1187, in do_open
r = h.getresponse(buffering=True)
File “/usr/lib/python2.7/httplib.py”, line 1051, in getresponse
response.begin()
File “/usr/lib/python2.7/httplib.py”, line 415, in begin
version, status, reason = self._read_status()
File “/usr/lib/python2.7/httplib.py”, line 379, in _read_status
raise BadStatusLine(line)
httplib.BadStatusLine: ”
Hi guys!
I have a during changing the status of any server from FAULTY to SPARE. Sometimes it changes its status successfully in second try, but sometimes I am trying many many times and I got several different errors returned randomly:
• ServerError: Error trying to configure server (5935d453-3142-11e6-9913-005056943929) as slave: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the –replicate-same-server-id option must be used on slave but this does not always make sense; please check the manual before using it)..
• ServerError: Error trying to configure server (5935d453-3142-11e6-9913-005056943929) as slave: Command (SHOW SLAVE STATUS, ()) failed accessing (server.locald:3306). MySQL Connection not available…
• ServerError: Error trying to configure server (5935d453-3142-11e6-9913-005056943929) as slave: Command (CHANGE MASTER TO MASTER_HOST = %s, MASTER_PORT = %s, MASTER_USER = %s, MASTER_PASSWORD = %s, MASTER_AUTO_POSITION = 1, (‘server3.locald’, 3306, ‘fabric_server’, ‘secret’)) failed accessing (server3.locald:3306). MySQL Connection not available…
• ServerError: Error trying to configure server (5935d453-3142-11e6-9913-005056943929) as slave: Command (START SLAVE , ()) failed accessing (server3.locald:3306). 2055: Lost connection to MySQL server at ‘server3.locald:3306’, system error: 104 Connection reset by peer..
I am sure that every host has different server_id, I increased connection timeout and max allowed packet. I can successfully connect from client to server using MySQL CLI using any username (fabric_server as well).
From the mysqld.log:
[Note] Aborted connection 457 to db: ‘unconnected’ user: ‘fabric_server’ host: ‘server.locald’ (Got timeout reading communication packets)
From general log:
440 Connect [email protected] on using TCP/IP
440 Query SET NAMES ‘utf8’ COLLATE ‘utf8_general_ci’
440 Query SET @@session.autocommit = ON
440 Query SELECT @@GLOBAL.SERVER_UUID as SERVER_UUID
440 Query SELECT @@GLOBAL.SERVER_ID as SERVER_ID
440 Query SELECT @@GLOBAL.VERSION as VERSION
440 Query SELECT @@GLOBAL.GTID_MODE as GTID_MODE
440 Query SELECT @@GLOBAL.LOG_BIN as LOG_BIN
440 Query SELECT @@GLOBAL.READ_ONLY as READ_ONLY
439 Query STOP SLAVE
439 Query SHOW SLAVE STATUS
439 Query SHOW SLAVE STATUS
439 Query CHANGE MASTER TO MASTER_HOST = ‘server3.locald’ MASTER_USER = ‘fabric_server’ MASTER_PASSWORD = MASTER_PORT = 3306
439 Query SET @@GLOBAL.READ_ONLY = ON
439 Query SELECT @@GLOBAL.READ_ONLY as READ_ONLY
439 Query START SLAVE
439 Query SHOW SLAVE STATUS
443 Connect [email protected] on using SSL/TLS
441 Connect Out [email protected]:3306
443 Query SELECT UNIX_TIMESTAMP()
443 Query SELECT @@GLOBAL.SERVER_ID
443 Quit
Thank you in advance for any response!
[root@newgen09 scripts]# ./mysqlfabric.py group add my_group 192.168.137.92:3306
Password for admin:
Fabric UUID: 5ca1ab1e-a007-feed-f00d-cab3fe13249e
Time-To-Live: 1
ServerError: The MySQL Server instance used as Fabric’s state store cannot be managed.
whis is this problem????