
A common question I get about Percona XtraDB Cluster is if you can mix it with asynchronous replication, and the answer is yes! You can pick any node in your cluster and it can either be either a slave or a master just like any other regular MySQL standalone server (Just be sure to use log-slave-updates in both cases on the node in question!). Consider this architecture:
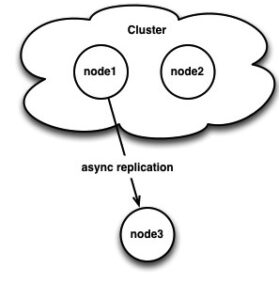
However, there are some caveats to be aware of. If you slave from a cluster node, there is no built in mechanism to fail that slave over automatically to another master node in your cluster. You cannot assume that the binary log positions are the same on all nodes in your cluster (even if they start binary logging at the same time), so you can’t issue a CHANGE MASTER without knowing the proper binary log position to start at.
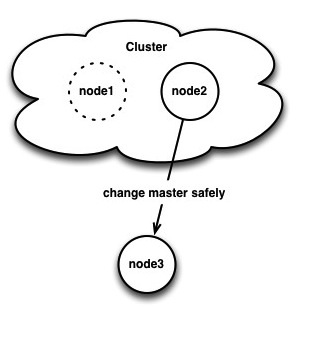
Until recently, I thought it was not possible to easily do this without scanning both the relay log on the slave and the binary log on the new master and trying to match up the (binary) replication event payloads somehow. It turns out it’s actually quite easy to do without the old master being available and without pausing writes on your cluster.
Given the above scenario, we have a 2 node cluster with node3 async replicating from node1. Writes are going to node2. If I stop writes briefly and look at node1’s binary log, I can see something interesting:
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@node1 mysql]# mysqlbinlog node1.000004 | tail MzkzODgyMjg3NDctMjQwNzE1NDU1MjEtNTkxOTQwMzk0MTYtMjU3MTQxNDkzMzI= '/*!*/; # at 442923 #130620 11:07:00 server id 2 end_log_pos 442950 Xid = 86277 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/; |
Notice the Xid field. Galera is modifying this field that exists in a standard binlog with its last commited seqno:
|
1 2 3 4 5 6 |
[root@node1 ~]# mysql -e "show global status like 'wsrep_last_committed'"; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | wsrep_last_committed | 86277 | +----------------------+-------+ |
If I check node2, sure enough its latest binlog has the same Xid, even though it’s in a different file at a different position:
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@node2 mysql]# mysqlbinlog node2.000002 | tail MzkzODgyMjg3NDctMjQwNzE1NDU1MjEtNTkxOTQwMzk0MTYtMjU3MTQxNDkzMzI= '/*!*/; # at 162077 #130620 11:07:00 server id 2 end_log_pos 162104 Xid = 86277 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/; |
So, with both nodes doing log-bin (and both with log-slave-updates), even though they are on different log files, they still have the same Xid that is very easy to search for.
But, does our slave (node3) know about these Xids? If we check the latest relay log:
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@node3 mysql]# mysqlbinlog node3-relay-bin.000002 | tail MzkzODgyMjg3NDctMjQwNzE1NDU1MjEtNTkxOTQwMzk0MTYtMjU3MTQxNDkzMzI= '/*!*/; # at 442942 #130620 11:07:00 server id 2 end_log_pos 442950 Xid = 86277 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/; |
Yes, indeed! We’re assuming the SQL thread on this slave has processed everything in the relay log and, if it has, then we know that the Galera transaction seqno 86277 was the last thing written on the slave. If it hasn’t, you’d have to find the last position applied by the SQL thread using SHOW SLAVE STATUS and find the associated Xid with that position.
Now, let’s simulate a failure to see if we can use this information to our advantage. I have write load running against node2 and I kill node1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
root@node2 mysql]# myq_status wsrep mycluster / node2 / Galera 2.5(r150) Wsrep Cluster Node Queue Ops Bytes Flow Conflct PApply Commit time P cnf # cmt sta Up Dn Up Dn Up Dn pau snt lcf bfa dst oooe oool wind 11:13:33 P 24 2 Sync T/T 0 0 2k 11 2.8M 258 0.0 0 0 0 9 0 0 1 11:13:34 P 24 2 Sync T/T 0 0 10 0 16K 0 0.0 0 0 0 9 0 0 1 11:13:35 P 24 2 Sync T/T 0 0 14 0 22K 0 0.0 0 0 0 8 0 0 1 11:13:36 P 24 2 Sync T/T 0 0 10 0 16K 0 0.0 0 0 0 8 0 0 1 11:13:37 P 24 2 Sync T/T 0 0 7 0 11K 0 0.0 0 0 0 8 0 0 1 11:13:38 P 24 2 Sync T/T 0 0 5 0 7.5K 0 0.0 0 0 0 8 0 0 1 11:13:39 P 24 2 Sync T/T 0 0 6 0 9.3K 0 0.0 0 0 0 8 0 0 1 11:13:40 P 24 2 Sync T/T 0 0 10 0 15K 0 0.0 0 0 0 8 0 0 1 11:13:41 P 24 2 Sync T/T 0 0 8 0 12K 0 0.0 0 0 0 8 0 0 1 11:13:42 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:43 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:44 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:45 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:47 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:48 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 mycluster / node2 / Galera 2.5(r150) Wsrep Cluster Node Queue Ops Bytes Flow Conflct PApply Commit time P cnf # cmt sta Up Dn Up Dn Up Dn pau snt lcf bfa dst oooe oool wind 11:13:49 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:50 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:51 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:52 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:53 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:54 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:55 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:56 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:57 P 24 2 Sync T/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:13:58 N 615 1 Init F/T 0 0 0 2 0 234 0.0 0 0 0 8 0 0 0 11:13:59 N 615 1 Init F/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 11:14:00 N 615 1 Init F/T 0 0 0 0 0 0 0.0 0 0 0 8 0 0 0 |
The node failure takes a little while. This is because it was a 2 node cluster and we just lost quorum. Note the node goes to the Init state and it is also non-Primary. This also happened to kill our test client. If we check our slave, we can see it is indeed disconnected since node1 went away:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
node3 mysql> show slave statusG *************************** 1. row *************************** Slave_IO_State: Reconnecting after a failed master event read Master_Host: node1 Master_User: slave Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node1.000004 Read_Master_Log_Pos: 3247513 Relay_Log_File: node3-relay-bin.000002 Relay_Log_Pos: 3247532 Relay_Master_Log_File: node1.000004 Slave_IO_Running: Connecting Slave_SQL_Running: Yes ... |
Since our remaining node is non-Primary, we need to bootstrap it first and restart our load. (Note: This is only because it was a 2 node cluster, this is not strictly necessary to do this procedure in general).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[root@node2 mysql]# mysql -e 'set global wsrep_provider_options="pc.bootstrap=true"' [root@node2 mysql]# myq_status wsrep mycluster / node2 / Galera 2.5(r150) Wsrep Cluster Node Queue Ops Bytes Flow Conflct PApply Commit time P cnf # cmt sta Up Dn Up Dn Up Dn pau snt lcf bfa dst oooe oool wind 11:16:46 P 25 1 Sync T/T 0 0 2k 17 3.0M 1021 0.0 0 0 0 5 0 0 1 11:16:47 P 25 1 Sync T/T 0 0 10 0 16K 0 0.0 0 0 0 5 0 0 1 11:16:48 P 25 1 Sync T/T 0 0 13 0 20K 0 0.0 0 0 0 5 0 0 1 11:16:49 P 25 1 Sync T/T 0 0 10 0 15K 0 0.0 0 0 0 5 0 0 1 11:16:50 P 25 1 Sync T/T 0 0 8 0 11K 0 0.0 0 0 0 5 0 0 1 11:16:51 P 25 1 Sync T/T 0 0 15 0 23K 0 0.0 0 0 0 5 0 0 1 11:16:52 P 25 1 Sync T/T 0 0 11 0 17K 0 0.0 0 0 0 6 0 0 1 11:16:53 P 25 1 Sync T/T 0 0 10 0 15K 0 0.0 0 0 0 6 0 0 1 |
Ok, so our cluster of 1 is back up and taking writes. But, how can we CHANGE MASTER so node3 replicates from node1? First we need to find node3’s last received Xid:
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@node3 mysql]# mysqlbinlog node3-relay-bin.000002 | tail MDk5MjkxNDY3MTUtMDkwMzM3NTg2NjgtMTQ0NTI2MDQ5MDItNzgwOTA5MTcyNTc= '/*!*/; # at 3247505 #130620 11:13:41 server id 2 end_log_pos 3247513 Xid = 88085 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/; |
We can tell from SHOW SLAVE STATUS that all of the relay log was processed, so we know the last applied Xid was 88085. Checking node2, we can indeed tell the cluster has progressed further:
|
1 2 3 4 5 6 |
[root@node2 mysql]# mysql -e "show global status like 'wsrep_last_committed'" +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | wsrep_last_committed | 88568 | +----------------------+-------+ |
It’s easy to grep for node3’s last Xid in node2’s binlog (if the slave has been disconnected a while, you may have to search a bit more through the binlogs):
|
1 2 |
[root@node2 mysql]# mysqlbinlog node2.000002 | grep "Xid = 88085" #130620 11:13:41 server id 2 end_log_pos 2973899 Xid = 88085 |
So, on node2, Xid 88085 is in binary log node2.000002, position 2973899. 2973899 is the “end” position, so that should be where we start from on the slave. Back on node3 we can now issue a correct CHANGE MASTER:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
node3 mysql> slave stop; Query OK, 0 rows affected (0.01 sec) node3 mysql> change master to master_host='node2', master_log_file='node2.000002', master_log_pos=2973899; Query OK, 0 rows affected (0.02 sec) node3 mysql> slave start; Query OK, 0 rows affected (0.00 sec) node3 mysql> show slave statusG *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: node2 Master_User: slave Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node2.000002 Read_Master_Log_Pos: 7072423 Relay_Log_File: node3-relay-bin.000002 Relay_Log_Pos: 4098705 Relay_Master_Log_File: node2.000002 Slave_IO_Running: Yes Slave_SQL_Running: Yes .... |
Of course, we are still scanning relay logs and binary logs, but matching Xid numbers is a lot easier than trying to match RBR payloads.
Resources
RELATED POSTS





It’s even possible to use async replication between galera clusters, but then you need to be aware of a pt-table-checkum/sync bug.
https://bugs.launchpad.net/percona-toolkit/+bug/1169853