
 This is a followup to my previous post Apache Spark with Air ontime performance data.
This is a followup to my previous post Apache Spark with Air ontime performance data.
To recap an interesting point in that post: when using 48 cores with the server, the result was worse than with 12 cores. I wanted to understand the reason is was true, so I started digging. My primary suspicion was that Java (I never trust Java) was not good dealing with 100GB of memory.
There are few links pointing to the potential issues with a huge HEAP:
http://stackoverflow.com/questions/214362/java-very-large-heap-sizes
https://blog.codecentric.de/en/2014/02/35gb-heap-less-32gb-java-jvm-memory-oddities/
Following the last article’s advice, I ran four instances of Spark’s slaves. This is an old technique to better utilize resources, as often (as is well known from old MySQL times) one instance doesn’t scale well.
I added the following to the config:
|
1 2 3 |
export SPARK_WORKER_INSTANCES=4 export SPARK_WORKER_CORES=12 export SPARK_WORKER_MEMORY=25g |
The full description of the test can be found in my previous post Apache Spark with Air ontime performance data
The results:
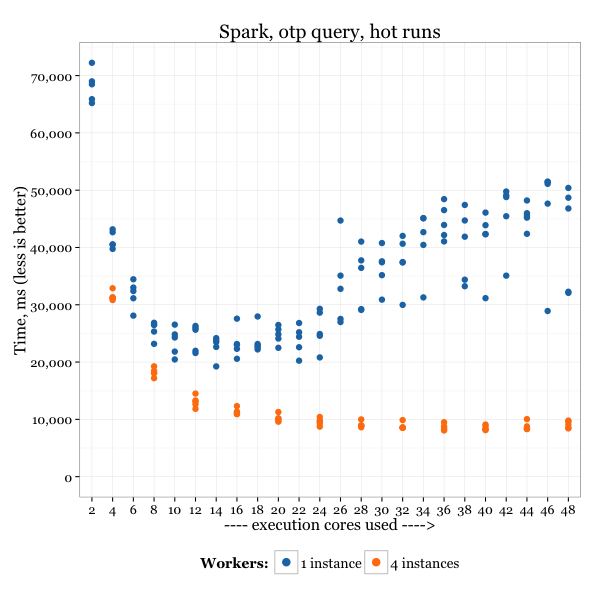
Although the results for four instances still don’t scale much after using 12 cores, at least there is no extra penalty for using more.
It could be that the dataset is just not big enough to show the setup’s full potential.
I think there is a clear indication that with the 25GB HEAP size, Java performs much better than with 100GB – at least with Oracle’s JDK (there are comments that a third-party commercial JDK may handle this better).
This is something to keep in mind when working with Java-based servers (like Apache Spark) on high end servers.





When has Java worked complimentarily ? Try with OpenJDK, with and without Zero JIT engine, might make a difference.
Hi Vadim,
There are challenges in running java with large heap. Please have a look at this article https://engineering.linkedin.com/garbage-collection/garbage-collection-optimization-high-throughput-and-low-latency-java-applications there is an example of JVM options at the end for 40gb heap, it may increase performance of your test with a single instance.
Cheers
I don’t think OpenJDK and Zero would make a difference, after all Zero is built for compatibility, not necessarily performance. Azul Zing has modifications that allow for Garbage Collection without pauses.
Java Garbage collection, the bane of my existence. I work for a client who uses elasticsearch for a few things (mainly logging) and even at smallish heap sizes garbage collection becomes a major headache – especially on virtualized systems. This is particularly hard to debug for someone who isn’t a Java developer. It seems Garbage Collection in go is a lot better.
Once you pass the threshold of 32 GiB you’ll also lose a lot of RAM because the pointer size has to be increased to 64bit.
I wonder have you tried tinkering with the JVM options? Maybe switching to HugeTLB (Large Pages) helps, but I currently lack a test setup. And it’s usually a bit awkward to configure.
‘@Nils, @Dimasik
Thanks for comments.
I should say it is quite frustrating to see that enterprise oriented software like Java still can’t handle 32GB+ of RAM. I consider 32GB of RAM is a minimal requirement for the current bare-metal servers.
What’s perhaps worse is that there is little effort underway addressing this flaw within in the JVM. The JVM now defaults to the G1 Garbage Collector, but even that one doesn’t seem that much faster (compared to for example Go).
Best wishes publishing.
I add pluri-core vs quicktime, is key to improove PC-engin
The Java GC has always been a curse in Java development projects.
You can visit me in linkedin: https://www.linkedin.com/home?trk=nav_responsive_tab_home