
 There is a growing interest in Apache Spark, so I wanted to play with it (especially after Alexander Rubin’s Using Apache Spark post).
There is a growing interest in Apache Spark, so I wanted to play with it (especially after Alexander Rubin’s Using Apache Spark post).
To start, I used the recently released Apache Spark 1.6.0 for this experiment, and I will play with “Airlines On-Time Performance” database from
http://www.transtats.bts.gov/DL_SelectFields.asp?Table_ID=236&DB_Short_Name=On-Time. You can find the scripts I used here https://github.com/Percona-Lab/ontime-airline-performance. The uncompressed dataset is about 70GB, which is not really that huge overall, but quite convenient to play with.
As a first step, I converted it to Parquet format. It’s a column based format, suitable for parallel processing, and it supports partitioning.
The script I used was the following:
|
1 2 3 4 5 |
# bin/spark-shell --packages com.databricks:spark-csv_2.11:1.3.0 val df = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").option("inferSchema", "true").load("/data/opt/otp/On_Time_On_Time_Performance_*.csv") sqlContext.setConf("spark.sql.parquet.compression.codec", "snappy") df.write.partitionBy("Year").parquet("/data/flash/spark/otp") |
Conveniently, by using just two commands (three if to count setting compression, “snappy” in this case) we can convert ALL of the .csv files into Parquet (doing it in parallel).
The datasize after compression is only 3.5GB, which is a quite impressive compression factor of 20x. I’m guessing the column format with repeatable data allows this compression level.
In general, Apache Spark makes it very easy to handle the Extract, Transform and Load (ETL) process.
Another one of Spark’s attractive features is that it automatically uses all CPU cores and execute complexes in parallel (something MySQL still can’t do). So I wanted to understand how fast it can execute a query compared to MySQL, and how efficient it is in using multiple cores.
For this I decided to use a query such as:
"SELECT avg(cnt) FROM (SELECT Year,Month,COUNT(*) FROM otp WHERE DepDel15=1 GROUP BY Year,Month) t1"
Which translates to the following Spark DataFrame manipulation:
|
1 |
(pFile.filter("DepDel15=1").groupBy("Year","Month").count()).agg(avg("count")).show() |
I should note that Spark is perfectly capable of executing this as SQL query, but I want to learn more about DataFrame manipulation.
The full script I executed is:
|
1 2 3 4 5 6 7 8 9 |
val pFile = sqlContext.read.parquet("/mnt/i3600/spark/otp1").cache(); for( a <- 1 to 6){ println("Try: " +a ) val t1=System.currentTimeMillis; (pFile.filter("DepDel15=1").groupBy("Year","Month").count()).agg(avg("count")).show(); val t2=System.currentTimeMillis; println("Try: "+a+" Time: " + (t2-t1)) } exit |
And I used the following command line to call the script:
|
1 |
for i in `seq 2 2 48` ; do bin/spark-shell --executor-cores $i -i run.scala | tee -a $i.schema.res ; done |
which basically tells it to use from 2 to 48 cores (the server I use has 48 CPU cores) in steps of two.
I executed this same query six times. The first time is a cold run, and data is read from the disk. The rest are hot runs, and the query should be executed from memory (this server has 128GB of RAM, and I allocated 100GB to the Spark executor).
I measured the execution time in cold and hot runs, and how it changed as more cores were added.
There was a lot of variance in the execution time of the hot runs, so I show all the results to demonstrate any trends.
Cold runs:
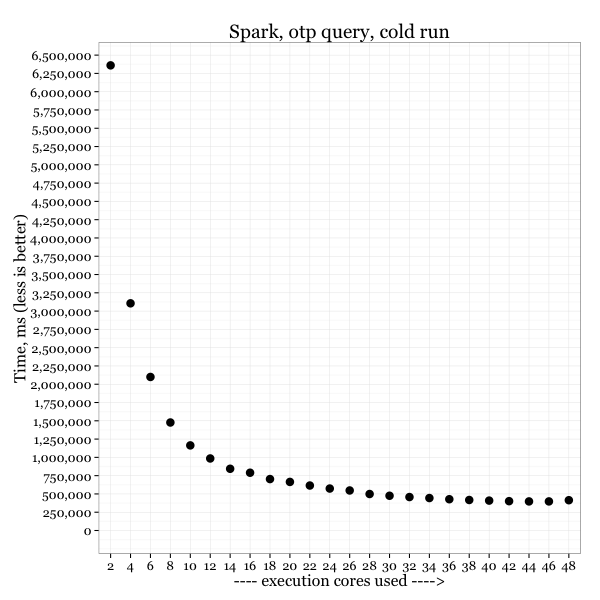
More cores seem to help, but after a certain point – not so much.
Hot runs:
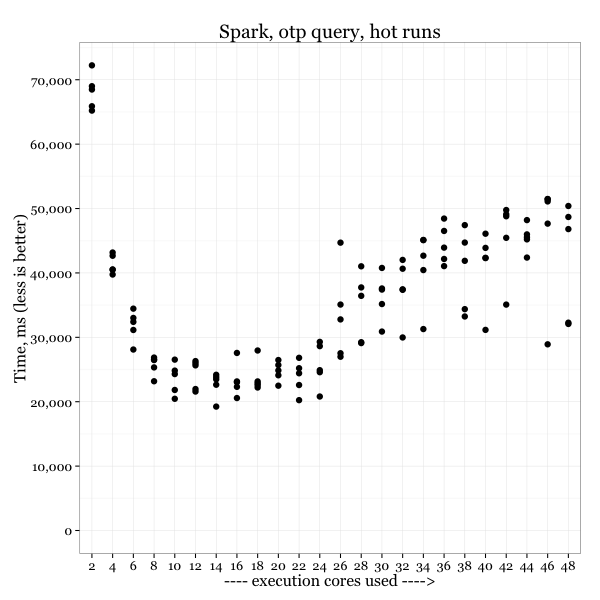
The best execution time was when 14-22 cores were used. Adding more cores after that, seems to actually make things worse. I would guess that the datasize is small enough so that the communication and coordination overhead cost exceeded the benefits of more parallel processing cores.
Comparing to MySQL
Just to have some points for comparison, I executed the same query in MySQL 5.7 using the following table schema: https://github.com/Percona-Lab/ontime-airline-performance/blob/master/mysql/create_table.sql
The hot execution time for the same query in MySQL (MySQL can use only one CPU core to execute one query) is 350 seconds (or 350,000ms to compare with the data on charts) when using the table without indexes. This is about 11 times worse than the best execution time in Spark.
If we use a small trick and createa covering index in MySQL designed for this query:
"ALTER TABLE ontime ADD KEY (Year,Month,DepDel15)"
then we can improve execution time to 90 seconds. This is still worse than Spark, but the difference is not as big. We can’t, however, create index for each ad-hoc query, while Spark is capable of processing a variety of queries.
In conclusion, I can say that Spark is indeed an attractive option for data analytics queries
(and in fact it can do much more). It is worth keep in mind, however, that in this experiment
it did not scale well with multiple CPU cores. I wonder if the same problem appears when we use multiple server nodes.
If you have recommendations on how I can improve the results, please post it in comments.
Spark configuration I used (in Standalone cluster setup):
|
1 2 3 4 5 |
export MASTER=spark://`hostname`:7077 export SPARK_MEM=100g export SPARK_DAEMON_MEMORY=2g export SPARK_LOCAL_DIRS=/mnt/i3600/spark/tmp export SPARK_WORKER_DIR=/mnt/i3600/spark/tmp |





Vadim,
I wonder if you plan to check some other queries, it would be great to see what kind of queries can be paralleled better and worse than others.
It would be also good to validate how things with network of computer works. Scalability with multiple cores in different in two ways. First you get much faster “network” than you have in majority of data centers but second you get shared memory and IO bus which can potentially get saturated with intensive data flow.
Can database cracking, enable ad-hoc query indexing in mysql and relational databases?
http://stratos.seas.harvard.edu/files/IKM_CIDR07.pdf
http://www.cidrdb.org/cidr2005/papers/P18.pdf
Vadim, if you have time take a look at Brendan Gregg’s smart approach in hunting performance issues based on flame graphs scheme.
http://www.brendangregg.com/flamegraphs.html
His technique is universal search for mysql flame graph with Google.
“If you have recommendations on how I can improve the results, please post it in comments.”
I found a good resource showing how to configure a JVM to use more than 32Gbytes for heap.
LINK: https://mrotaru.wordpress.com/
search for Allocated 54 GB for the JVM
Other useful presentation could be found here: http://www.slideshare.net/SpeedmentUS/java-one2015-work-with-hundreds-of-hot-terabytes-in-jvms
Regards,
Cristian