
 This post is a continuation of my research of TokuDB’s storage engine to understand if it is suitable for timeseries workloads.
This post is a continuation of my research of TokuDB’s storage engine to understand if it is suitable for timeseries workloads.
While inserting LOAD DATA INFILE into an empty table shows great results for TokuDB, what’s more interesting is seeing some realistic workloads.
So this time let’s take a look at the INSERT benchmark.
What I am going to do is to insert data in 16 parallel threads into the table from the previous post:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE `sensordata` ( `ts` int(10) unsigned NOT NULL DEFAULT '0', `sensor_id` int(10) unsigned NOT NULL, `data1` double NOT NULL, `data2` double NOT NULL, `data3` double NOT NULL, `data4` double NOT NULL, `data5` double NOT NULL, `cnt` int(10) unsigned NOT NULL, PRIMARY KEY (`sensor_id`,`ts`) ) |
The INSERTS are bulk inserts with sequentially increasing ts and with sensor_id from 1 to 1000.
While the inserts are not fully sequential, because the primary key is (sensor_id, ts), it is enough to have in memory workload, so I do not expect performance degradation when data exceeds memory. This will play in favor for InnoDB, as it is known that TokuDB performs worse in CPU-bound benchmarks.
The benchmark executes 1mln events, each event inserts 1000 records in bulk. That is when finished we should about about 1 bln records in the table.
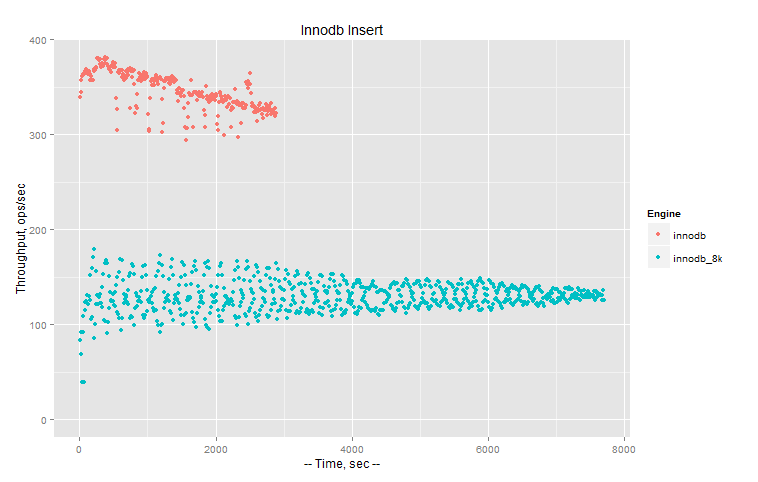
So let’s see how InnoDB (compressed 8K vs not compressed) performs.
Throughput (more is better):
Response time (log 10 scale on the axe Y) (less is better):
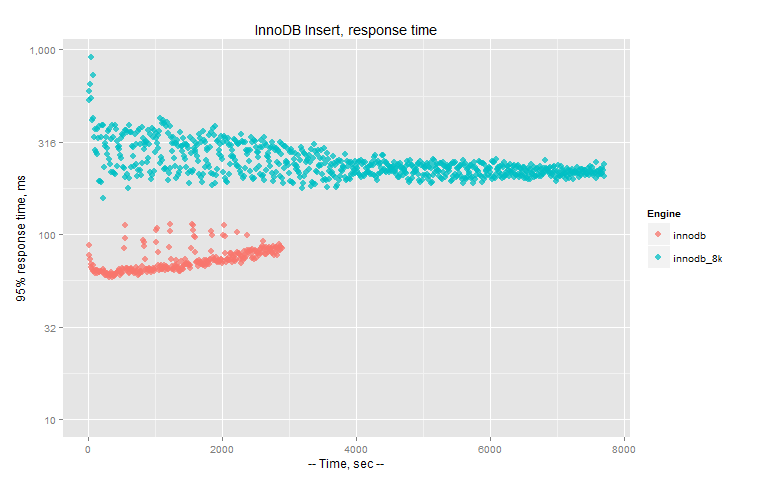
So InnoDB comes with following numbers:
Now, we have a quite bad compression rate, because I used uniform distribution for values of data1-data5 columns, and uniform may not be good for compression. And actually in the real case I expect much more repeating values, so I am going to re-test with pareto (zipfian) distribution.
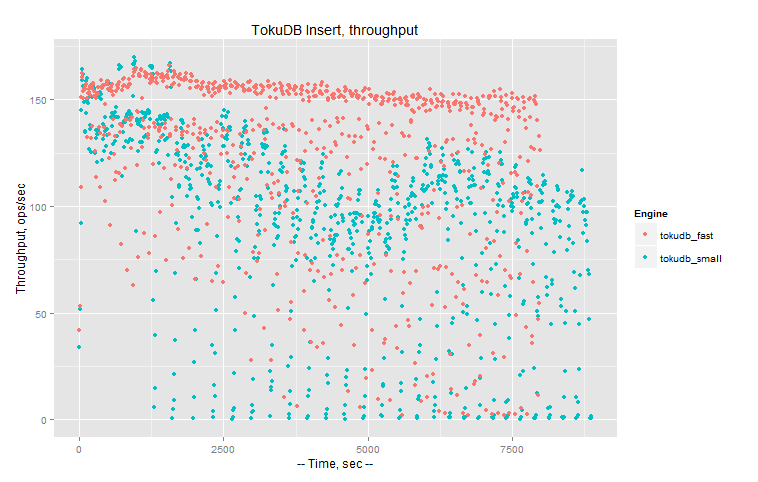
For TokuDB (tested tokudb_fast and tokudb_small formats)
Throughput (more is better):
Response time (log 10 scale on the axe Y) (less is better):
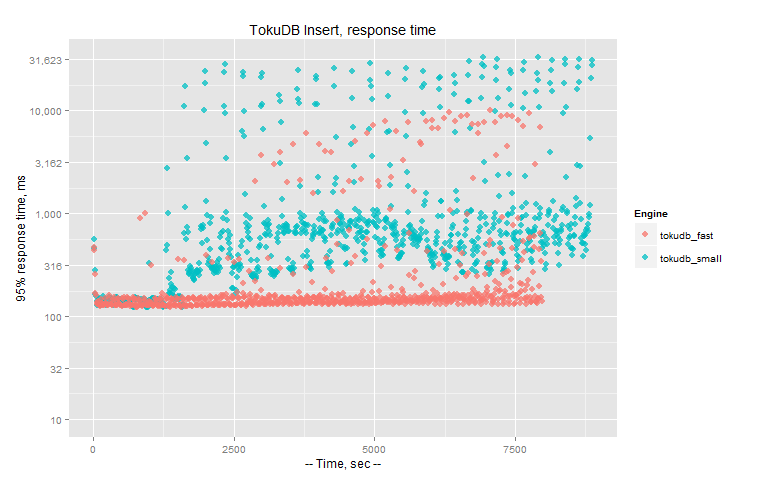
TokuDB observations:
File sizes for TokuDB: tokudb_fast: 50GB, tokudb_small: 45GB. Again I correspond a bad compression rate to uniform distribution. If we switch to pareto, the file size for tokudb_fast is 21GB, and for tokudb_small is 13GB
If we zoom in to 900 sec timeframe we can see periodic behavior of TokuDB:
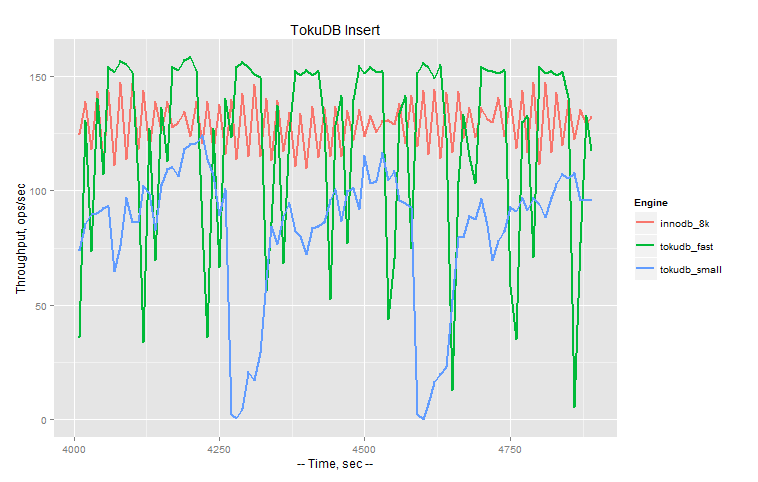
Now I consider these stalls in TokuDB as severe and I do not think I can recommend to use it in production under such workload conditions until the problem is fixed.
The scripts for the timeseries benchmark for sysbench v0.5 you can find there
https://github.com/percona/sysbench-scripts
Software versions, for InnoDB: Percona Server 5.6-RC3 , for TokuDB: mariadb-5.5.30-tokudb-7.0.4
UPDATE (5-Sep-2013):
By many requests I update the post with following information:
TokuDB throughput (tokudb_small row format) with Pareto distribution, for two cases:
sensor_id,ts) (on graph: tokudb_small)
ts,sensor_id), KEY (sensor_id,ts) (on graph: tokudb_small_key)
Throughput in this case:
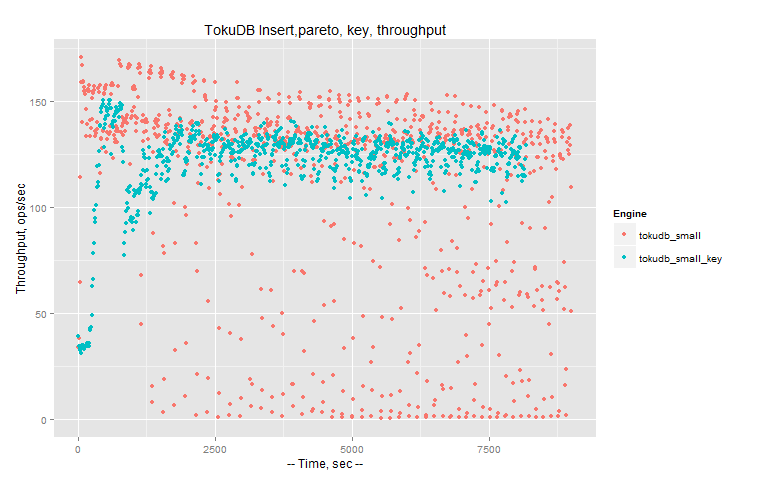
We can see that top throughput for tokudb_small_key is less then for tokudb_small, but there is also less variance in throughput.
The my.cnf files.
For InnoDB
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
[mysqld] # gdb log-error=error.log innodb_file_per_table = true innodb_data_file_path = ibdata1:100M:autoextend innodb_flush_method = O_DIRECT innodb_log_buffer_size = 256M innodb_flush_log_at_trx_commit = 1 innodb_buffer_pool_size = 40G innodb_buffer_pool_instances=1 innodb_file_format = Barracuda innodb_checksum_algorithm = crc32 innodb_log_file_size = 4G innodb_log_files_in_group = 2 #innodb_log_block_size=4096 #####plugin options innodb_read_io_threads = 16 innodb_write_io_threads = 4 innodb_io_capacity = 4000 #not innodb options (fixed) port = 3306 back_log = 50 max_connections = 2000 max_prepared_stmt_count=500000 max_connect_errors = 10 table_open_cache = 2048 max_allowed_packet = 16M binlog_cache_size = 16M max_heap_table_size = 64M sort_buffer_size = 4M join_buffer_size = 4M thread_cache_size = 1000 query_cache_size = 0 query_cache_type = 0 thread_stack = 192K tmp_table_size = 64M server-id = 10 key_buffer_size = 8M read_buffer_size = 1M read_rnd_buffer_size = 4M bulk_insert_buffer_size = 8M myisam_sort_buffer_size = 8M myisam_max_sort_file_size = 10G myisam_repair_threads = 1 myisam_recover socket=/var/lib/mysql/mysql.sock user=root |
for TokuDB (pretty much defaults)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
[mysqld] gdb skip-innodb #not innodb options (fixed) port = 3306 back_log = 50 max_connections = 2000 max_prepared_stmt_count=500000 max_connect_errors = 10 table_open_cache = 2048 max_allowed_packet = 16M binlog_cache_size = 16M max_heap_table_size = 64M sort_buffer_size = 4M join_buffer_size = 4M thread_cache_size = 1000 query_cache_size = 0 query_cache_type = 0 ft_min_word_len = 4 #default_table_type = InnoDB thread_stack = 192K tmp_table_size = 64M server-id = 10 key_buffer_size = 8M read_buffer_size = 1M read_rnd_buffer_size = 4M bulk_insert_buffer_size = 8M myisam_sort_buffer_size = 8M myisam_max_sort_file_size = 10G #myisam_max_extra_sort_file_size = 10G myisam_repair_threads = 1 myisam_recover socket=/var/lib/mysql/mysql.sock user=root |





Vadim,
Wow… this looks like the Innodb fuzzy checkpoint nightmare graphs from few years back.
I wonder when you share some select speeds with us as it is very important too 🙂
So TokuDB engineers gave me some advise, that in this case instability in results is caused
that inserts into table with PRIMARY KEY (
sensor_id,ts) are not sequential.So recommendation is to have
PRIMARY KEY (
ts,sensor_id)and
KEY (
sensor_id,ts)So inserts into PRIMARY KEY in this case are fully sequential.
It actually help, with this schema I have much more stable results almost without drop in throughput.
The drawback is obvious – we increase space on disk. in this case, with tokudb_small format,
the KEY (
sensor_id,ts) takes additional 2GB of space.I am working on SELECT queries, stay tuned.
Thanks Vadim,
So we should treat it as limitation of TokuDB should not be used with non sequential primary key inserts when ?
If “random” inserts cause such dips I would be very curious how updates behave. It is possible to use auto-increment primary keys to get PK sequential essentially for any tables but for some workloads you always need semi random updates.
Peter,
Yes, I think at this point it is a limitation of TokuDB that it requires sequential PK inserts.
TokuDB is aware about this https://github.com/Tokutek/ft-index/issues/60
and hope they will find a solution.
What happens if you add more columns to the secondary index to make it covering and avoid random disk reads on queries?
Vadim,
I assume your hardware configuration is as it was in the prior blog. Can you provide the my.cnf files you used for the tests?
Vadim,
1) is this using SSD? if so the insertion rate of ~100 inserts/s seems extremely low. Why is that?
2) At the beginning of the benchmark when all data fits in memory why isn’t the performance much higher? InnoDB should be able to manage much more than 400 inserts/s on an in-memory data set, no?
3) After you changed TokuDB’s PK to (ts,sensor_id) what insert performance did you get?
‘@Mark.
If we include dataN fields into covered index, obviously the size of covered index will grow.
And as we need to access all data1-data5 and if we include all of them – the size of the index will equal to size of the primary key,
that is space consumption will pretty much double.
‘@Andy.
1) This is very fast PCI-e SSD card. Please note that each insert is insert of 1000 rows. so 100 inserts/sec is actually 100.000 rows/sec inserted.
2) Again, this is 400.000 rows/sec
3) I updated the post with the results for PRIMARY KEY (
ts,sensor_id),KEY (
sensor_id,ts)I don’t understand your concern about doubling space. You wrote that TokuDB is 20x smaller than uncompressed InnoDB, or 10x smaller than InnoDB8K. If giving up a factor of two of the space would speed things up, it might be worth it: the space would still be 10x (or 5x respectively) smaller than InnoDB.
Bradley,
In this case, if we perform INSERTS, the compression ratio is not 20x anymore.
InnoDB uncompressed: 82GB
TokuDB_small: 13GB
So compression ratio is 6.3x , with doubled space it will be only 3.15x.
Which still kind of good, but not so much anymore.
And all this comes as just plan overhead, as I don’t really need
(ts,sensor_id)index.I am curious to see how NDB Cluster (1 node) performs with this workload. Although it needs much more RAM (even if with Disk Data) and disk space.
‘@Vadim Tkachenko
It seems to me as tokudb is much smaller, there is the option of comparing tokudb on SSD/PCI-E vs innodb(uncompressed) on SAS.
So you might be able to say: “Yes, tokudb is slower and has more flushing issues, but because it compresses so well, better hardware may solve those issues”.
In your opinion, is it worth testing that scenario?
Some things that matter for flash:
* how much must you buy (compression matters here)
* how long will it last (doing less random writes or larger writes matters here)
So on these issues TokuDB does better than InnoDB. Sometimes response time is the priority, other times TCO matters more.
Regarding compression, TokuDB has pluggable compression engine
feature (with lz4 added recently to it), whereas InnoDB has been
at zlib all this while (even with 5.6 with all its compression
improvements). So the compression ratio and speed can be impacted
by this too.
I’m following your posts carefully, Vadim, because I too am evaluating tokudb for not-quite-sequential time-series inserts.
I curious, what happens if you PARTITION by sensor_id?
Vadim have you done any tests comparing query performance for InnoDB and TokuDB?
I had some problem with the queries, i posted it here:
http://stackoverflow.com/questions/18697054/tokudb-performance-in-mariadb
‘@Vadim Tkachenko, do you think you could rerun these tests using TokuDB 7.1.6 (or later). There was a major key related bug that was fixed. Although that one deals with deleted keysm
This is a great post, but it doesn’t have the solution to this issue.
TokuDB does NOT require sequential PK inserts for good performance!
You can have good performance for random PK inserts, but you have to use the right type of INSERT command that takes advantage of TokuDB’s tombstone messaging to avoid unnecessary overhead.
For Vadim’s test that uses the Primary KEY (sensor_id,ts), he needs to use the REPLACE INTO command or INSERT IGNORE command.
See these articles for a further explanation:
http://www.tokutek.com/2010/07/why-insert-on-duplicate-key-update-may-be-slow-by-incurring-disk-seeks/
http://www.tokutek.com/2010/06/making-replace-into-fast-by-avoiding-disk-seeks/