
Recently, I’ve been looking into issues with the interactions between MySQL asynchronous replication and Galera replication. In this blog post, I’d like to share what I’ve learned.
These interactions are complicated due to the number of factors involved (Galera replication vs. asynchronous replication, replication filters, and row-based vs. statement-based replication). So as a start, I’ll look at an issue that came up with setting up an asynchronous replication channel between two Percona XtraDB Cluster (PXC) clusters.
Here’s a view of the desired topology:
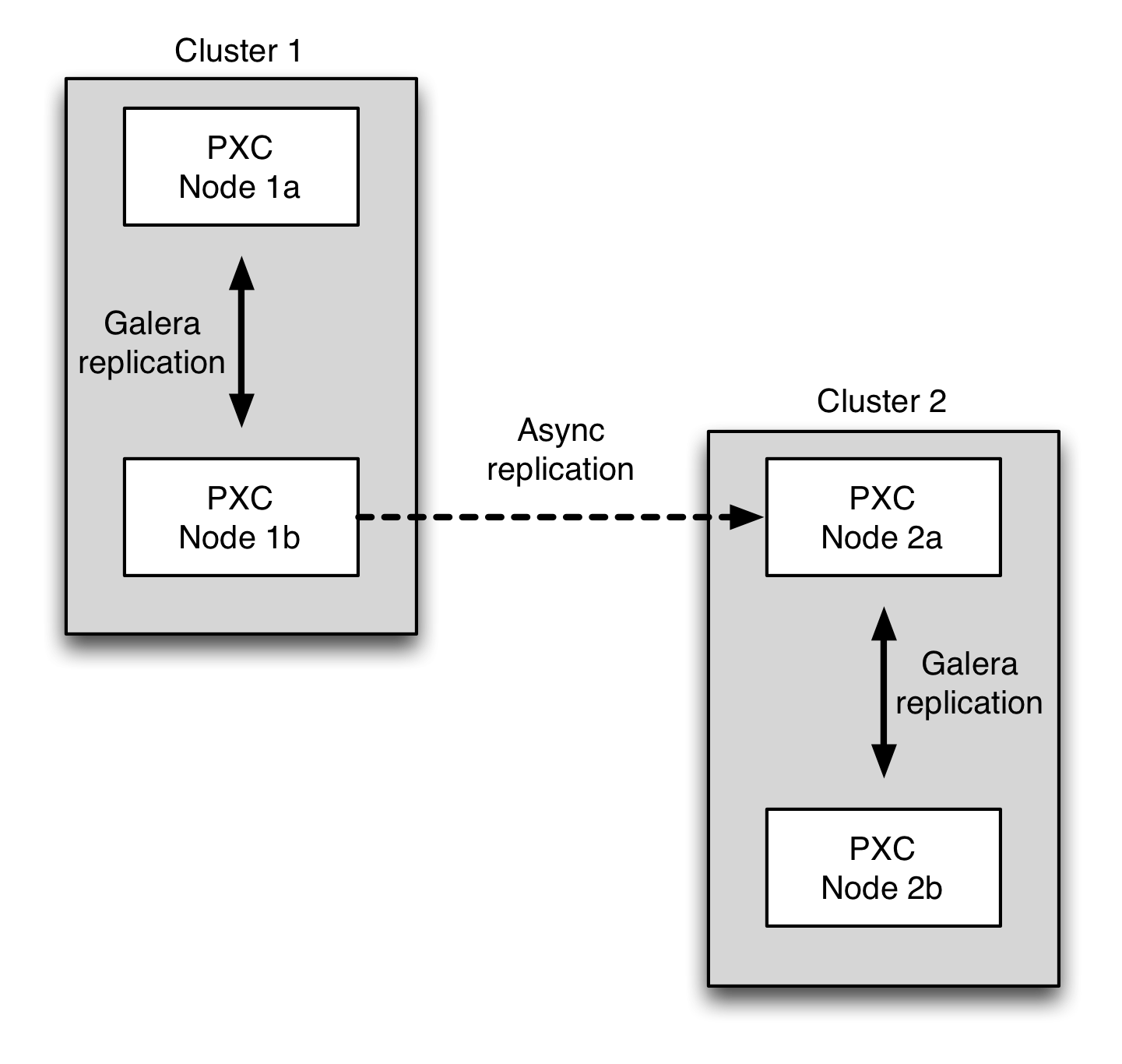
We want to set up an asynchronous replication channel between two PXC clusters. We also set log-slave-updates on the async slave (PXC node 2a in the topology diagram).
This is an interesting configuration and results in unexpected behavior as the replication depends on the node where the operation was performed. Let’s use CREATE TABLE as an example.
CREATE TABLE on Node 1a. The table replicates to Node 1b, but not to the nodes in cluster 2.
CREATE TABLE on Node 1b. The table replicates to all nodes (both cluster 1 and cluster 2).Understanding the problem requires some knowledge of MySQL threads. However, as a simplification, I’ll group the threads into three groups:
In the first case (CREATE TABLE executed on Node1a)
In the second case (CREATE TABLE executed on Node 1b)
log-slave-updates has been enabled on Node2a.That last part is the important bit. We can view the Galera replication threads as another set of asynchronous replication threads. So if data is coming in via async replication, they have to be made visible to Galera by log-slave-updates. This is true in the other direction also: log-slave-updates must be enabled for Galera to supply data to async replication.
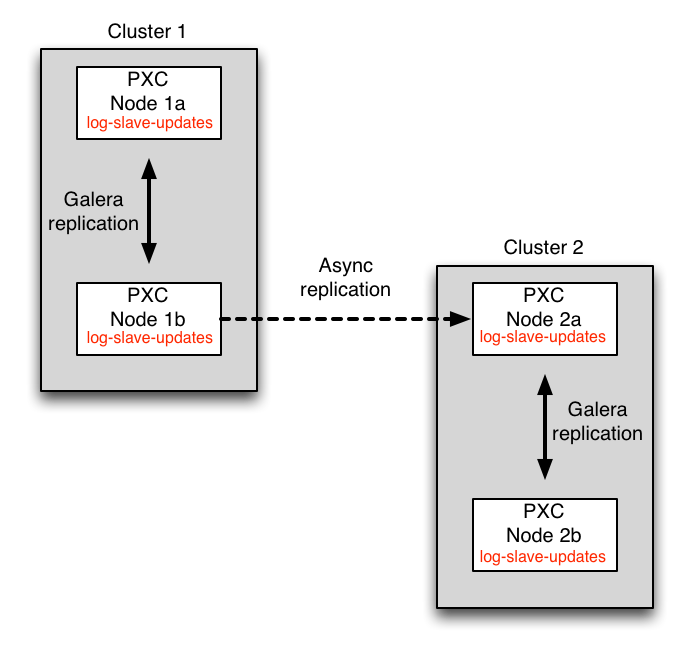
In this scenario, the answer is to set log-slave-updates on Node 1b (the async master) and on Node 2a (the async slave).
We set log-slave-updates on node 1b to allow the async threads to pickup the changes from the Galera threads.
We set log-slave-updates on node 2a to allow the Galera threads to pickup the changes from the async threads. Starting with PXC 5.7.17, calling START SLAVE on a PXC node will return an error unless log-slave-updates is enabled.
You must enable log-slave-updates on the node for data to be transferred between Galera and asynchronous replication.
If you plan to use MySQL asynchronous replication with Percona XtraDB Cluster (either as async master or slave), we recommend that you enable log-slave-updates on all nodes within the cluster. This to (1) to ensure that any async replication connections to/from the cluster work correctly and (2) to ensure that all the nodes within a cluster share the same configuration and behavior.
Recommended configuration diagram for the clusters:
 You May Also Like
You May Also LikeToday’s developers are tasked with operating in an increasingly competitive business world. They must be ready to capitalize on new trends, as well as develop, test and deploy technologies faster than ever before. Enter MongoDB, which is as flexible as it is powerful. With it, developers can design extremely high-performance apps. Read our white paper, Why Developers Prefer MongoDB, for a discussion of each of MongoDB’s advantages and when they make the best business sense.
Embark on a seamless MySQL database setup with Percona Server for MySQL. Our solution brief guides you through establishing a robust, on-premises MySQL database, complete with failover and essential business continuity features.

Resources
RELATED POSTS





Based on your recommended configuration diagram:
What is the purpose of enabling the *log-slave-updates* on Node 2a? based on my understanding, as this is under the *sync-replication* and the it has been taken care by galera itself.
Enabling log-slave-updates on node 2a will cause node 2a’s async replication thread to write its events to the binlog, thus allowing galera to see the events (galera is acting like any other async replication thread, thus this is like chained replication).
What will happen when we use semi-sync replication instead of async between two cluster. Given two clusters are far apart, and latency can cause the thread to wait for slave response. Does this effect Galera internal replication and slow down the cluster due to async setup ?
I haven’t done much with semi-sync replication, so I can’t answer definitely. I can see this causing a slowdown in the cluster because the speed of the cluster is determined by the slowest node (so in this case it would probably be the node sending the transaction to the other cluster).
(1) galera cluster 1 tries to commit
(2) Before it can commit it sends the transaction to cluster2 (via semi-sync), and has to wait until cluster2 has acknowledged receipt of the data
(3) cluster2 receives the data and returns back
(4) cluster1 can now commit
I was playing with such schema and I do not understand the issue. To make it working you need to enable log_bin= ON on all cluster members
Let’s imagine:
— 1. Run CREATE TABLE on Node 1a. The table replicates to Node 1b, but not to the nodes in cluster 2.:
Create statement will be in binary logs of all cluster members will not be?
— Run CREATE TABLE on Node 1b. The table replicates to all nodes (both cluster 1 and cluster 2).
The only difference in binary logs will be “server id” value, but the statement will appear in binary logs.
slave_log_updates is not an option that you need worry about.
Please correct me if I am wrong.
Hi Timur,
The issue is that the replication threads (both async replication and galera replication) do not write to the binlog unless log-slave-updates is set. So the events will not jump between async replication and galera replication unless log-slave-updates is set. So within cluster 1, the table will replicate but the binlog event may not.
Here’s the relevant section from the MySQL 5.7 documenation (https://dev.mysql.com/doc/refman/5.7/en/binary-log.html)
A replication slave server by default does not write to its own binary log any data modifications that are received from the replication master. To log these modifications, start the slave with the –log-slave-updates option in addition to the –log-bin option (see Section 16.1.6.3, “Replication Slave Options and Variables”). This is done when a slave is also to act as a master to other slaves in chained replication.
Does this also require GTID or can we use bin-log’s?