
 The microservice architecture is not a new pattern but has become very popular lately for mainly two reasons: cloud computing and containers. That combo helped increase adoption by tackling the two main concerns on every infrastructure: Cost reduction and infrastructure management.
The microservice architecture is not a new pattern but has become very popular lately for mainly two reasons: cloud computing and containers. That combo helped increase adoption by tackling the two main concerns on every infrastructure: Cost reduction and infrastructure management.
However, all that beauty hides a dark truth:
The hardest part of microservices is the data layer
And that is especially true when it comes to classic relational databases like MySQL. Let’s figure out why that is.
Following the same two pillars of microservices (cloud computing and containers), what can one do with that in the MySQL space? What do cloud computing and containers bring to the table?
The magic of the cloud is that it allows you to be cost savvy by letting you easily SCALE UP/SCALE DOWN the size of your instances. No more wasted money on big servers that are underutilized most of the time. What’s the catch? It’s gotta be fast. Quick scale up to be ready to deal with traffic and quick scale down to cut costs when traffic is low.
The magic of containers is that one can slice hardware to the resource requirements. The catch here is that containers were traditionally used on stateless applications. Disposable containers.
Relational databases in general and MySQL, in particular, are not fast to scale and are stateful. However, it can be adapted to the cloud and be used for the data layer on microservices.
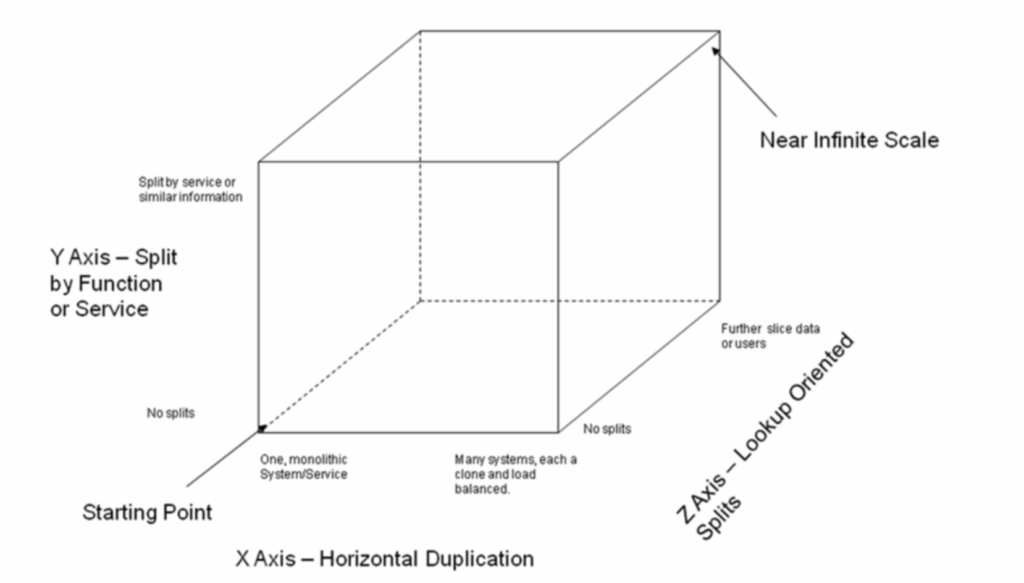
The book “The Art of Scalability” by Abott and Fisher describes a really useful, three dimension scalability model: the Scale Cube. In this model, scaling an application by running clones behind a load balancer is known as X-axis scaling. The other two kinds of scaling are Y-axis scaling and Z-axis scaling. The microservice architecture is an application of Y-axis scaling: It defines an architecture that structures the application as a set of loosely coupled, collaborating services.
On microservices, each service has its own database in order to be decoupled from other services. In other words: a service’s transactions only involve its database; data is private and accessible only via the microservice API.
It’s natural that the first approach to divide the data is by using the multi-tenant pattern:
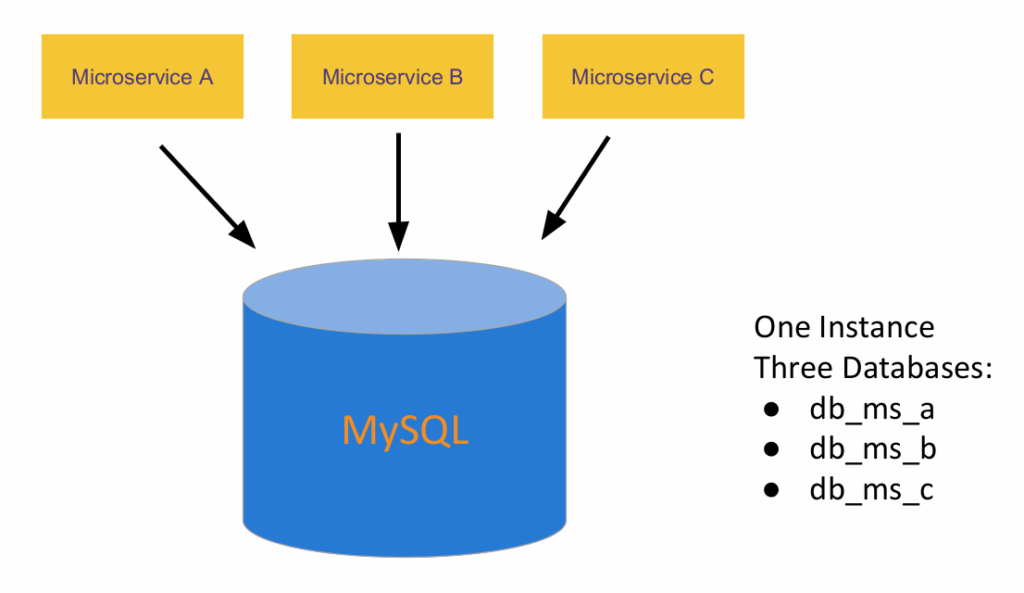
Actually before trying multi-tenant, one can use a tables-per-service model where each service owns a set of tables that must only be accessed by that service, but by having that “soft” division, the temptation to skip the API and access directly other services’ tables is huge.
Schema-per-service, where each service has a database schema that is private to that service is appealing since it makes ownership clearer. It is easy to create a user per database, with specific grants to limit database access.
This pattern of “shared database” however comes with some drawbacks like:
The alternative is to go “Database per service”
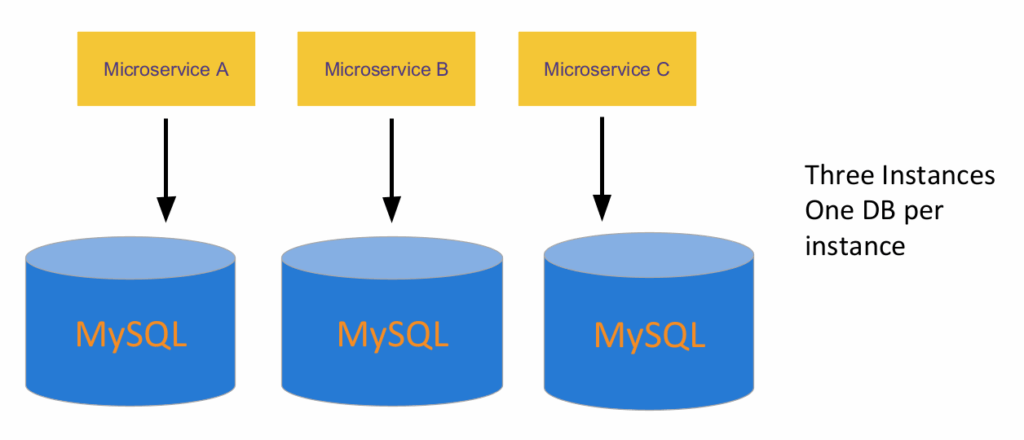
Share nothing. Cleaner logical separation. Isolated issues. Services are loosely coupled. In fact, this opens the door for microservices to use a database that best suits their needs, like a graph db, a document-oriented database, etc. But as with everything, this also comes with drawbacks:
The simplistic approach is to use a two-phase commit implementation. But that solution is just an open invitation to a huge amount of locking issues. It just doesn’t scale. So what are the alternatives?
A saga is a sequence of local transactions. Each local transaction updates the database and publishes messages or events that trigger the next local transaction in the saga. If a local transaction fails for whatever reason, then the saga executes a series of compensating transactions that undo the changes made by the previous transactions. More on Saga here: https://microservices.io/patterns/data/saga.html
An API composition is just a composer that invokes queries on each microservice and then performs an in-memory join of the results:
https://microservices.io/patterns/data/api-composition.html
CQRS is keeping one or more materialized views that contain data from multiple services. This avoids the need to do joins on the query size: https://microservices.io/patterns/data/cqrs.html
What do all these alternatives have in common? That is taken care of at the API level: it becomes the responsibility of the developer to implement and maintain it. The data layer keep continues to be data, not information.
There are means for your MySQL to be cloud-native: Easy to scale up and down fast; running on containers, a lot of containers; orchestrated with Kubernetes; with all the pros of Kubernetes (health checks, I’m looking at you).
A Kubernetes Operator is a special type of controller introduced to simplify complex deployments. Operators provide full application lifecycle automation and make use of the Kubernetes primitives above to build and manage your application.

In our blog post “Introduction to Percona Operator for MySQL Based on Percona XtraDB Cluster” an overview of the operator and its benefits are covered. However, it’s worth mentioning what does it make it cloud native:
Under the hood is a Percona XtraDB Cluster running on PODs. Easy to scale out (increase the number of nodes: https://docs.percona.com/percona-operator-for-mysql/pxc/scaling.html) and can be scaled up by giving more resources to the POD definition (without downtime)
Give it a try https://docs.percona.com/percona-operator-for-mysql/pxc/index.html and unleash the power of the cloud on MySQL.
Resources
RELATED POSTS




