
I have been working with Peter in preparation for the talk comparing the optimizer enhancements in MySQL 5.6 and MariaDB 5.5. We are taking a look at and benchmarking optimizer enhancements one by one. So in the same way this blog post is aimed at a new optimizer enhancement Index Condition Pushdown (ICP). Its available in both MySQL 5.6 and MariaDB 5.5
Now let’s take a look briefly at what this enhancement actually is, and what is it aimed at.
Traditional B-Tree index lookups have some limitations in cases such as range scans, where index parts after the part on which range condition is applied cannot be used for filtering records. For example, suppose you have a key defined as:
|
1 |
KEY `i_l_partkey` (`l_partkey`,`l_quantity`,`l_shipmode`,`l_shipinstruct`) |
and the WHERE condition defined as:
|
1 2 3 4 |
l_partkey = x and l_quantity >= 1 and l_quantity <= 1+10 and l_shipmode in ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON' |
Then MySQL will use the key as if its only defined as including columns l_partkey and l_quantity and will not filter using the columns l_shipmode and l_shipinstruct. And so all rows matching condition l_partkey = x and and l_quantity >= 1 and l_quantity <= 1+10 will be fetched from the Primary Key and returned to MySQL server which will then in turn apply the remaining parts of the WHERE clause l_shipmode in (‘AIR’, ‘AIR REG’) and l_shipinstruct = ‘DELIVER IN PERSON’. So clearly if you have thousands of rows that match l_partkey and l_quantity but only a few hundred that match all the condition, then obviously you would be reading a lot of unnecessary data.
This is where ICP comes into play. With ICP, the server pushes down all conditions of the WHERE clause that match the key definition to the storage engine and then filtering is done in two steps:
You can read more about index condition pushdown as available in MySQL 5.6 here:
http://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
and as available in MariaDB 5.5 here:
http://kb.askmonty.org/en/index-condition-pushdown
Now let’s take a look at the benchmarks to see how much difference does this really make.
For the purpose of this benchmark I used TPC-H Query #19 and ran it on TPC-H dataset (InnoDB tables) with scale factors of 2 (InnoDB dataset size ~5G) and 40 (InnoDB dataset size ~95G), so that I could see the speedup in case of in-memory and IO bound workloads. For the purpose of these benchmarks query cache was disabled and the buffer pool size was set to 6G.
The query is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
select sum(l_extendedprice* (1 - l_discount)) as revenue from lineitem force index(i_l_partkey), part where ( p_partkey = l_partkey and p_brand = 'Brand#45' and p_container in ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') and l_quantity >= 1 and l_quantity <= 1+10 and p_size between 1 and 5 and l_shipmode in ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON' ) or ( p_partkey = l_partkey and p_brand = 'Brand#24' and p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') and l_quantity >= 14 and l_quantity <= 14+10 and p_size between 1 and 10 and l_shipmode in ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON' ) or ( p_partkey = l_partkey and p_brand = 'Brand#53' and p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') and l_quantity >= 28 and l_quantity <= 28+10 and p_size between 1 and 15 and l_shipmode in ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON' ) |
There are two changes that I made to the query and the TPC-H tables’ structure.
– Added a new index: KEY i_l_partkey (l_partkey,l_quantity,l_shipmode,l_shipinstruct)
– Added an index hint in the query: lineitem force index(i_l_partkey)
The size of the buffer pool used for the benchmarks is 6G and the disks are 4 5.4K disks in Software RAID5.
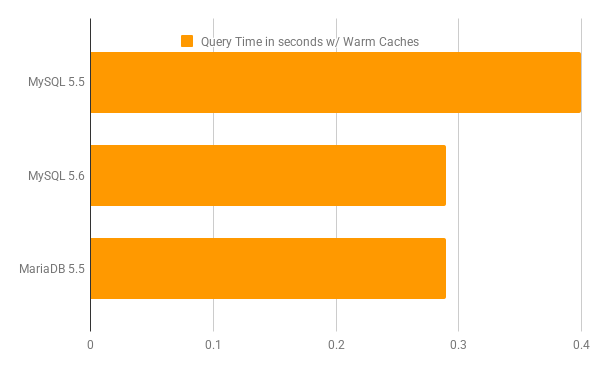
Now let’s first take a look at how effective is ICP when the workload is in memory. For the purpose of benchmarking in-memory workload, I used a Scale Factor of 2 (dataset size ~5G), and the buffer pool was warmed up so that the relevant pages were already loaded in the buffer pool:
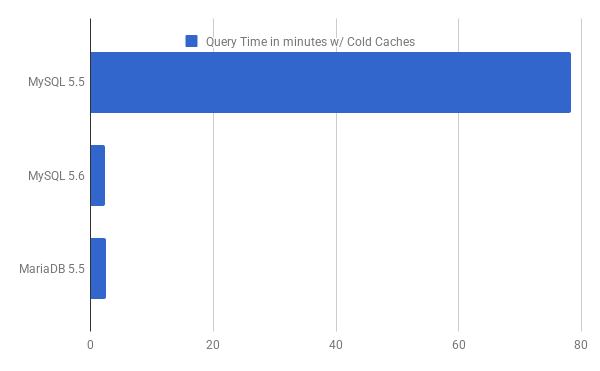
And what about IO bound workload, when the dataset does not fit into memory. For the purpose of benchmarking IO bound workload, I used a Scale Factor of 40 (dataset size ~95G) and the buffer pool was not warmed up, so that it does not have the relevant pages loaded up already:
Now let’s take a look at the status counters to see how much does this optimization make a difference.
These status counters are taken when performing the benchmark on IO bound workload, mentioned above.
| Counter Name | MySQL 5.5 | MySQL 5.6 | MariaDB 5.5 |
| Created_tmp_disk_tables | 0 | 0 | 0 |
| Created_tmp_tables | 0 | 0 | 0 |
| Handler_icp_attempts | N/A | N/A | 571312 |
| Handler_icp_match | N/A | N/A | 4541 |
| Handler_read_key | 19310 | 19192 | 18989 |
| Handler_read_next | 579426 | 4514 | 4541 |
| Handler_read_rnd_next | 8000332 | 8000349 | 8000416 |
| Innodb_buffer_pool_read_ahead | 81132 | 81067 | 81069 |
| Innodb_buffer_pool_read_requests | 4693757 | 1293628 | 1292675 |
| Innodb_buffer_pool_reads | 540805 | 28468 | 28205 |
| Innodb_data_read | 9.49G | 1.67G | 1.67G |
| Innodb_data_reads | 621939 | 109537 | 29796 |
| Innodb_pages_read | 621937 | 109535 | 109274 |
| Innodb_rows_read | 8579426 | 8004514 | 8004541 |
| Select_scan | 1 | 1 | 1 |
There are two indexes defined on the table with similar prefixes:
i_l_suppkey_partkey (l_partkey, l_suppkey)i_l_partkey (l_partkey,l_quantity,l_shipmode,l_shipinstruct)Obviously, the key i_l_partkey is much more restrictive. Although it cannot filter more rows by using traditional B-Tree index lookup used by MySQL, when compared to the key i_l_suppkey_partkey. But after the B-Tree lookup step, the second key can filter a lot more data using ICP on the remaining conditions after l_quantity. Yet MySQL 5.6 and MariaDB 5.5 optimizer does not consider this logic when selecting the index. In all the runs of the benchmark, the optimizer chose the key i_l_suppkey_partkey because the optimizer estimates that both indexes will mean same no. of rows and i_l_suppkey_partkey has a smaller key size. To get around this limitation in the optimizer I had to use index hint (FORCE INDEX). Clearly, selecting the correct index is an important part of optimizer’s job, and there is room for improvement there.
Another thing which I feel is that there is still further optimization possible, like moving ICP directly to the index lookup function so that the limitation in the optimizer which prevents other parts of the key after the first range condition are removed.
There is a huge speed up 78 minutes down to 2 minutes in case of completely IO bound workload, and upto 2x speedup in case when the workload is in-memory. There is not much difference here in terms of the performance gains on MariaDB 5.5 vs MySQL 5.6 and both are on-par. This is great for queries that suffer from the weakness of the current MySQL optimizer when it comes to doing multi-column range scans, and the ICP optimization will benefit a lot of your queries like the one I showed in my example. Not only that, because there will be a cut down in the number of data pages read into the buffer pool, it means better buffer pool utilization.
On a last note, I will be posting the benchmark scripts, table definitions, the configuration files for MySQL 5.5/5.6 and MariaDB 5.5 and the description of the hardware used.
Resources
RELATED POSTS





I think it is worth to note even though ICP improves the scan speed of the range in the index by allowing scanning index entries only and not reading the rows, it still scans complete range when partial scan is possible. In the example above “l_partkey = x
and l_quantity >= 1 and l_quantity <= 1+10" defines the range which will be scanned completely to apply "l_shipmode in ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON'" filter. Yet it would be possible instead for each value with given l_partkey and l_quantity to perform further lookup in index tree with named condition. Such optimization would be especially helpful if there are a lot of rows which have same l_partkey and l_quantity but second condition is very selective.
Did you run the queries only once, or multiple times per query?
‘@Baron Schwartz,
The queries were run multiple times with both cold buffer pool and multiple times with warmed up buffer pool.
‘@Peter,
Yes you are right, the filtering done using ICP should ideally be moved to where index lookup takes place at the B-Tree level.
How did you choose the numbers you showed in the graph? Is it an average of the several runs, or the best time, or…?
Its the best time for the same query, from among multiple runs.
I recommend you to change you secondary index to
KEY
i_l_partkey(l_partkey,’l_shipinstruct’,l_quantity,l_shipmode)I think if you use the this index,the result should be better.
jametong, the purpose of this post was to show in what conditions ICP would be helpful over MySQL 5.5, so the purpose of the query in the post and the index is to show that ICP would be helpful when the conditions after the first range condition can be applied directly to the index entries fetched, if those index entries contain columns that match the remaining conditions after the first range condition.
hi,
as you said :”Then MySQL will use the key as if its only defined as including columns l_partkey and l_quantity and will not filter using the columns l_shipmode and l_shipinstruct. And so all rows matching condition l_partkey = x and and l_quantity >= 1 and l_quantity <= 1+10 will be fetched from the Primary Key and returned to MySQL server which will then in turn apply the remaining parts of the WHERE clause l_shipmode in ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON'."
then how do you know it ? i mean, where can i found the optimization only use the prefix of index, but not the whole index ?
‘@repls,
MySQL has a limitation on range conditions whereby as soon as it encounters a range condition on one of the columns in a composite index, it stops using the remaining parts of the index. At the link below you will find a very good explanation of MySQL range access and its limitations by Jørgen:
http://jorgenloland.blogspot.com/2011/08/mysql-range-access-method-explained.html
Has this been implemented in Percona Server?
‘@Marcus,
No they have not made there way yet in Percona Server, but will in the future.