
Statement-based or row-based, or mixed? We’ve all seen this discussed at length so I’m not trying to rehash tired arguments. At a high level, the difference is simple:
Recently, I worked with a client to optimize their use of pt-online-schema-change and keep replication delay to a minimum. We found that using RBR in conjunction with a smaller chunk-time was the best result in their environment due to reduced IO on the slave, but I wanted to recreate the test locally as well to see how it looked in the generic sense (sysbench for data/load).
Here was my local setup:
And here is the base test that I ran:
Visually, the most telling difference between the two baselines comes from comparing the slave IOPs when using SBR vs RBR:
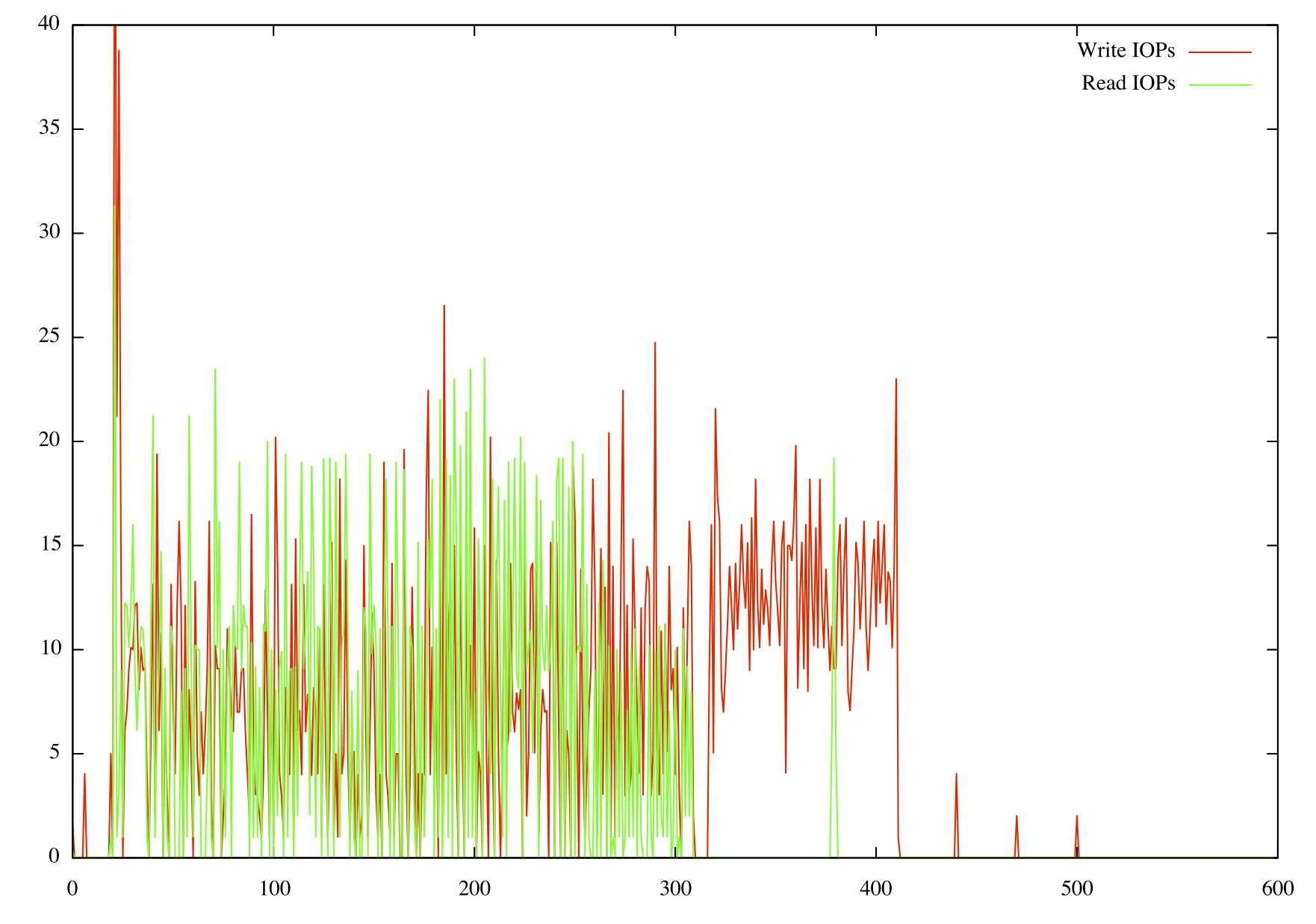

While the write operations look similar in both, you can see the dramatic difference in the read operations in that they are almost negligible when using row based. I had assumed there would be high read IOPs as the buffer pool was empty, so I also verified that the Innodb_buffer_pool_reads (reads that missed the buffer pool and went to disk) on both:
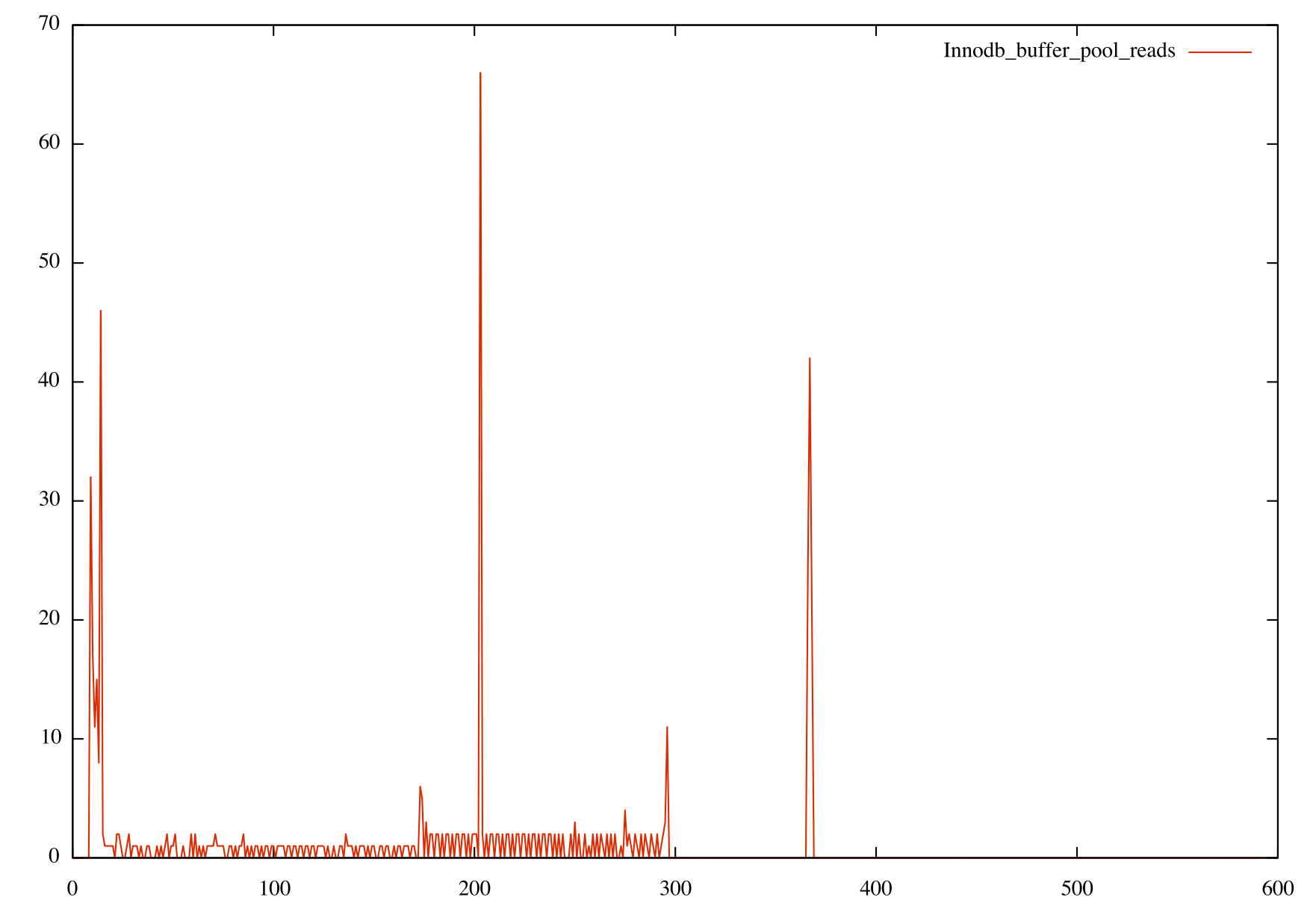
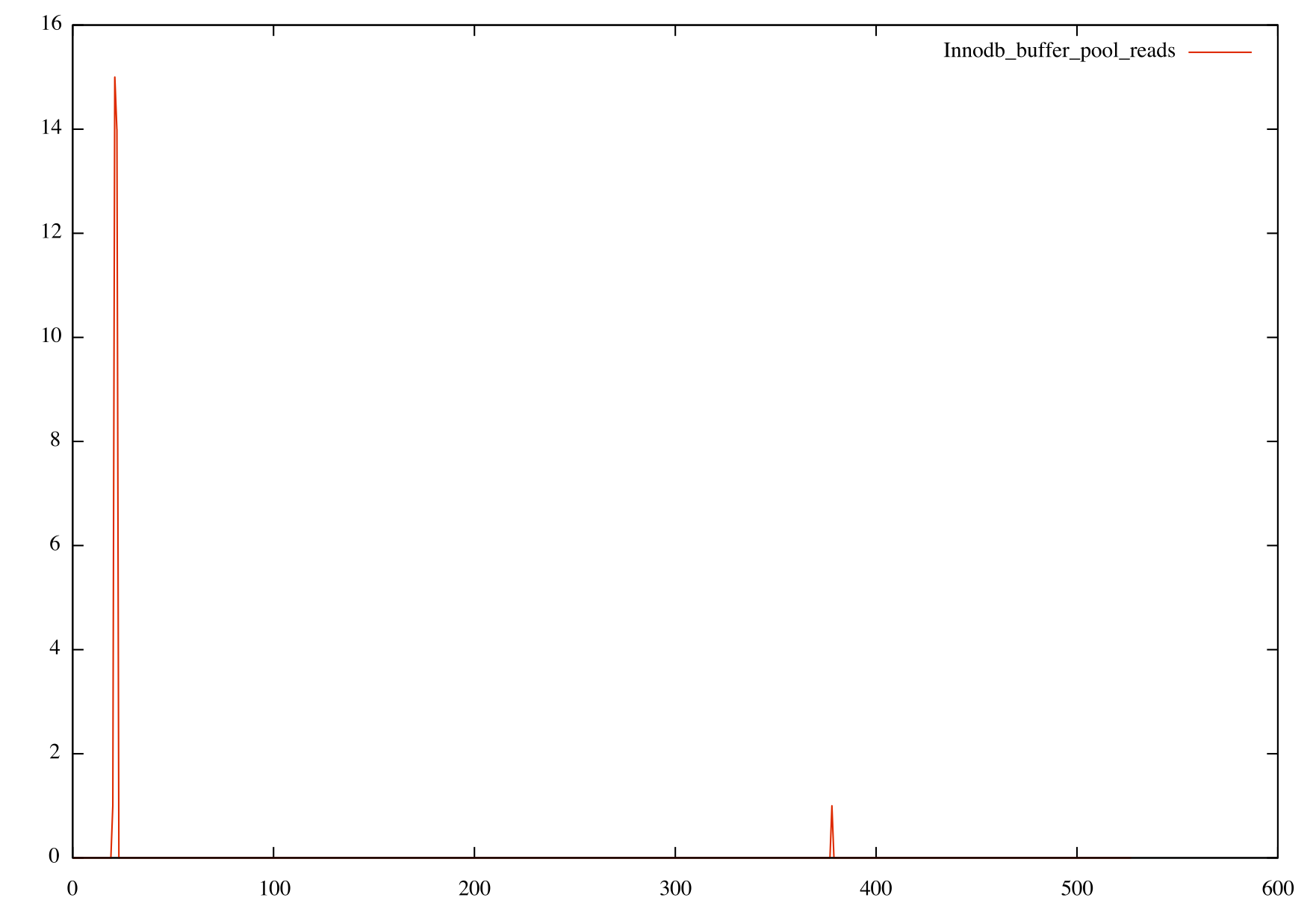
Looking at how pt-osc and the buffer pool operate, these results make sense for this workload. Here is the basic process for pt-osc:
In the case of SBR, the actual INSERT … SELECT CHUNK is replayed on the slave verbatim, meaning that the chunk will need to be read from disk if not in the BP in order to insert it into the new table. However, when using RBR, you simply send the rows to the slave. As this is a new table, there is nothing to read from disk so InnoDB simply writes the new page and it eventually gets flushed to disk.
This is where the –set-vars switch can come in handy with pt-online-schema-change. Picture this scenario:
In this case, adding extra read IOPs to the slave could be a performance killer. So assuming you have binlog_format=mixed on the slave, you can use the –set-vars like this to run the alter using RBR to save on IOPs:
pt-online-schema-change –alter=”ENGINE=InnoDB” –set-vars=”binlog_format=row” –execute h=master,D=db,t=tbl
Keep in mind, RBR isn’t going to give you the same results in the course of normal replication. When replicating changes to the slave, the page is requested from the buffer pool and read from disk if not present so that the changes can be applied to it. This can still be a win (think of a query that is very complicated that returns only a few rows), but you won’t see the dramatic difference as you do when using this approach with pt-osc.





binlog produced by RBR would be very large.
Indeed, that is one of the downsides to using RBR, especially in this context (altering a large table). In the case where disk space for the binlogs is a major concern, then this approach may not be the best or even feasible.
Like most options, there is usually a tradeoff when changing a setting like this.
Aside from the disk space, if write IO is already approaching it’s limits on the master, this may not be a good approach. Unfortunately, as is true with most things, this solution is workload dependent.
‘@nettedfish The use of RBR can be an increase in Binary Log size depending on the types of queries you execute. It some well structured applications it’s not a problem (i.e. not updating thousands of rows in one query).
MySQL 5.6 also introduces binlog_row_image (http://dev.mysql.com/doc/refman/5.6/en/replication-options-binary-log.html#sysvar_binlog_row_image) which can reduce the footprint.
binlog_format is also dynamic, so technically you could switch to RBR for the duration of OSC if the impact offset is of benefit. As always testing and verification is necessar.y
‘@Ronald – Thanks for clarifying! I wasn’t suggesting to switch to RBR exclusively, but rather to just use the session level (via –set-vars in pt-osc) if the slave was already IO bound on due to read queries and a small buffer pool.
And yes, the comment on testing and verification is extremely important as this approach is very workload dependent.