
 Running Database-as-a-Service (DBaaS) in the cloud is the norm for users today. It provides a ready-to-use database instance for users in a few seconds, which can be easily scaled and usually comes with a pay-as-you-go model.
Running Database-as-a-Service (DBaaS) in the cloud is the norm for users today. It provides a ready-to-use database instance for users in a few seconds, which can be easily scaled and usually comes with a pay-as-you-go model.
We at Percona see that more and more cloud vendors or enterprises either want to or are already running their DBaaS workloads on Kubernetes (K8S). Today we are going to shed some light on how Kubernetes and Operators can be a good tool to run DBaaS and what the most common patterns are.
Users usually do not care much how it works internally, but common expectations are:
The first step for cloud providers or for big enterprises leaning towards DBaaS on Kubernetes is to choose the topology. There are various ways how it can be structured.
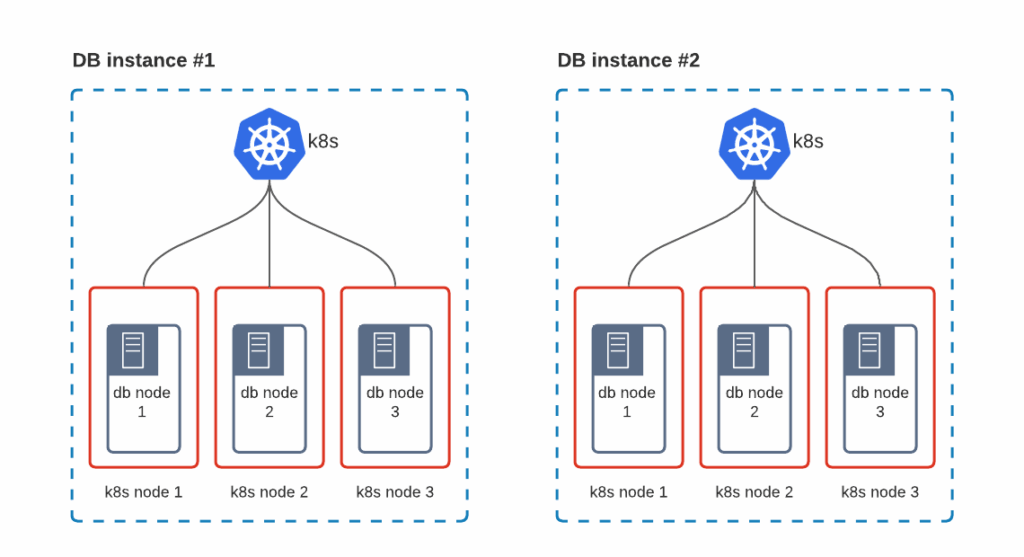
The advantage of this solution is that it is simple and provides good isolation of workloads by design.
The biggest disadvantage is that each Kubernetes cluster comes with its own masters, which run etcd and control-plane software. On a big scale, this adds a huge overhead.
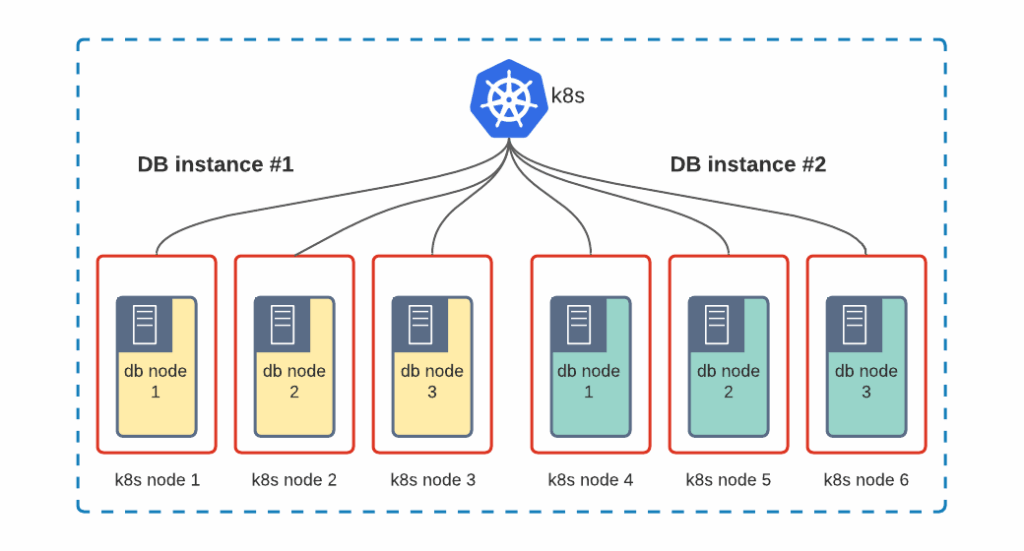
Pros: Good isolation, no overhead
Cons: It might be hard to maintain a good utilization of all the nodes in the cluster, and, as a result, lots of computational power will be wasted.
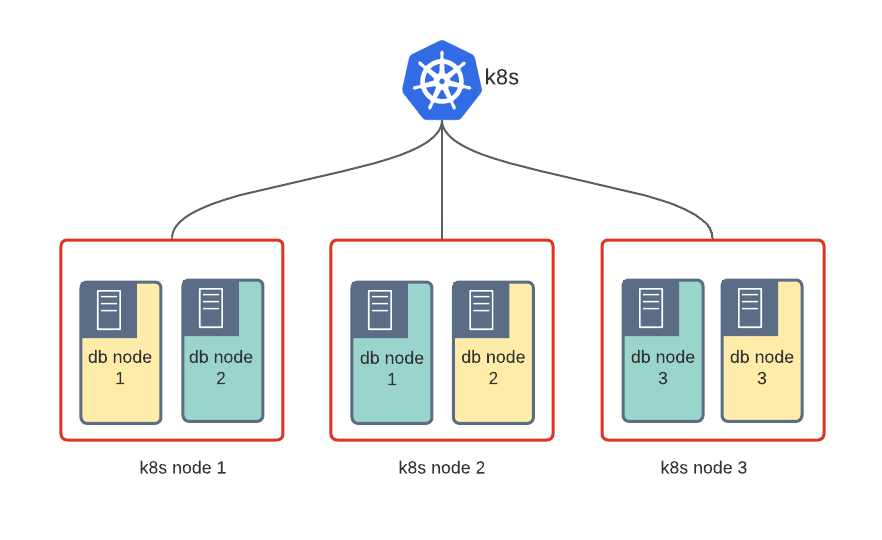
We are talking about namespace isolation. Either each customer or each database gets its own namespace.
Pros: Good use of computational resources, no waste
Cons: Resources are isolated via cgroups and it might be tricky to deal with security and “noisy tenants”.
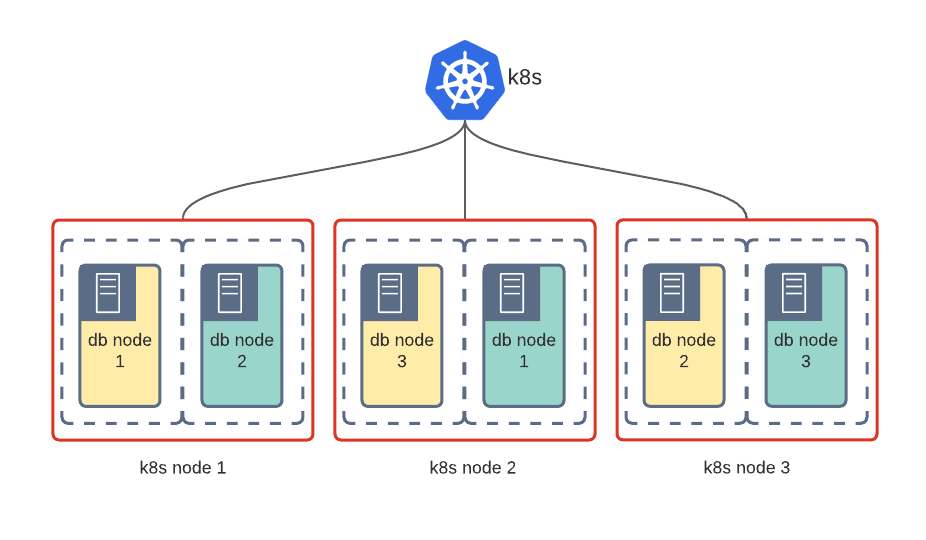
VM-like isolation is usually delivered by a special container runtime that hardens the boundary between the application and the host kernel.
It can be gVisor, Kata containers, even Firecracker. It slightly increases the resources overhead but improves security greatly.
As you can see on the diagrams above, database nodes are running on different Kubernetes nodes. Such a design guarantees zero downtime in case of a single VM or server failure. Affinity or Pod Topology Thread Constraints (promoted to stable in k8s 1.19) are used in Kubernetes to enforce Pod scheduling on separate nodes. In Percona Kubernetes Operators we have anti-affinity enabled by default to ensure a smooth experience for the end-user.
The database cannot go without data and storage. And as always, there are various ways how Operators can store data in Kubernetes.
When somebody talks storage in Kubernetes usually it starts with StatefulSets, the primitive which “manages the deployment and scaling of a set of Pods and provides guarantees about the ordering and uniqueness of these Pods”. In other words, this object ensures that Pods with data have unique names and start in a predictable order, which sometimes is crucial for the databases.
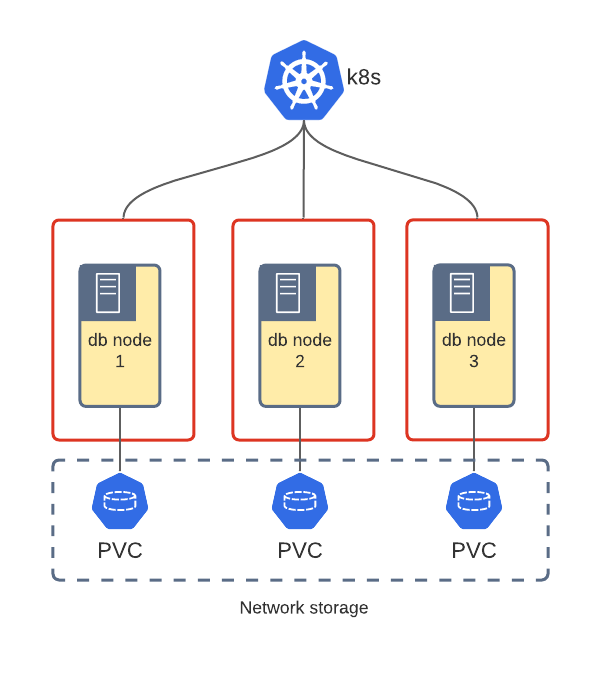
PVCs over network storage is the obvious choice in Kubernetes world, but there is no magic and network storage must be in place. Most cloud providers already have it, e.g. AWS EBS, Google Storage Engine, etc. There are solutions for private clouds as well – Ceph, Gluster, Portworx, etc. Some of them are even cloud-native – like Rook.io, which is Ceph on k8s.
The performance of PVCs heavily depends on network performance and the underlying disks used for the storage.
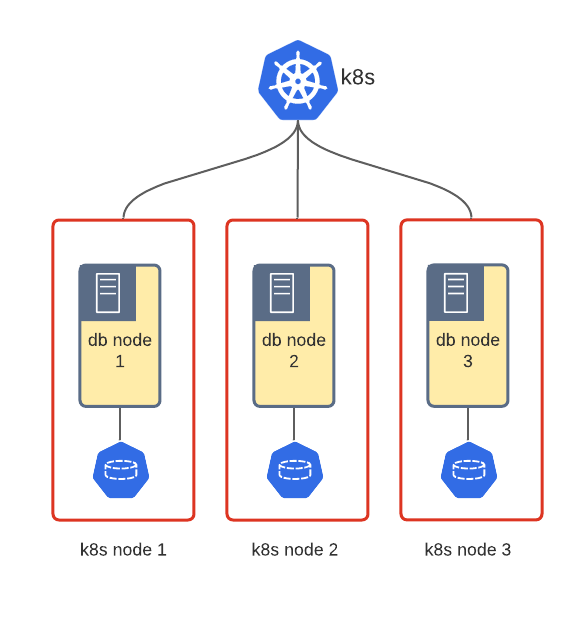
Kubernetes provides HostPath and EmptyDir primitives to use the storage of the node where the Pod runs. Local storage might be a good choice to boost performance and in cases where network storage is not available or introduces complexity (e.g. in private clouds)
It is ephemeral storage at its best – a Pod or node restart will wipe the data completely from the node. With good anti-affinity, it is possible to use EmptyDir for production workloads, but it’s not recommended. It is worth mentioning that EmptyDir can be used to store data in memory for extra performance:
|
1 2 3 |
- name: file-storage emptyDir: medium: Memory |
Pod stores data on a locally mounted disk of the Node. In this case, a Pod or Node restart does not cause data loss on the DB node. It is much easier to manage HostPath through PVCs with the OpenEBS Container Storage Interface. Read this great blog post from Percona’s CTO Vadim Tkachenko on how Percona Operators can be deployed with OpenEBS.
Using local storage is tricky because in case of a full node crash the data for one Pod will be lost completely and once the Pod starts back on a new node, it must be recovered somehow or synced from other nodes. It depends on the technology. For example, Percona XtraDB Cluster will do the State Snapshot Transfer with Galera to sync the data to an empty node.
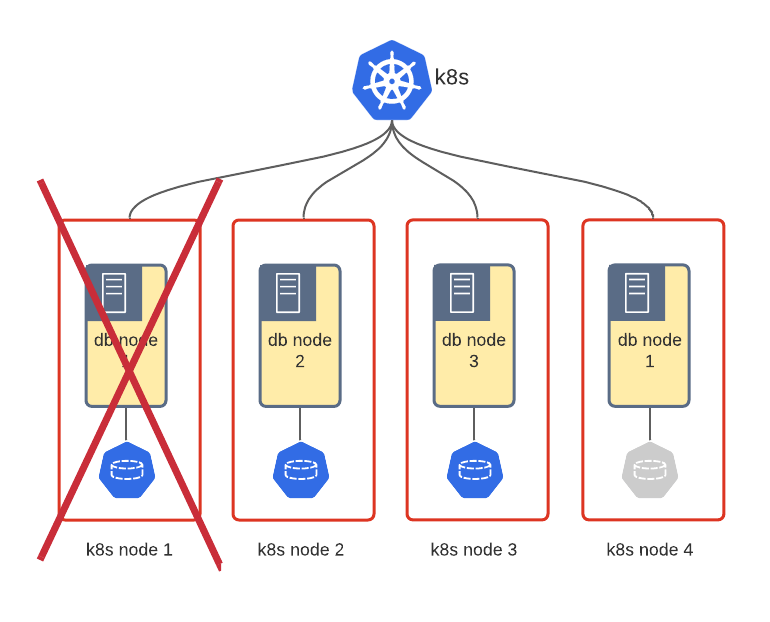
DBaaS should provide users with the database instance with limited resources, including limits on the storage. For example, 100 GBs per instance. With local storage, there is no way to limit the growth of the database. There are a couple of ways on how to address this:
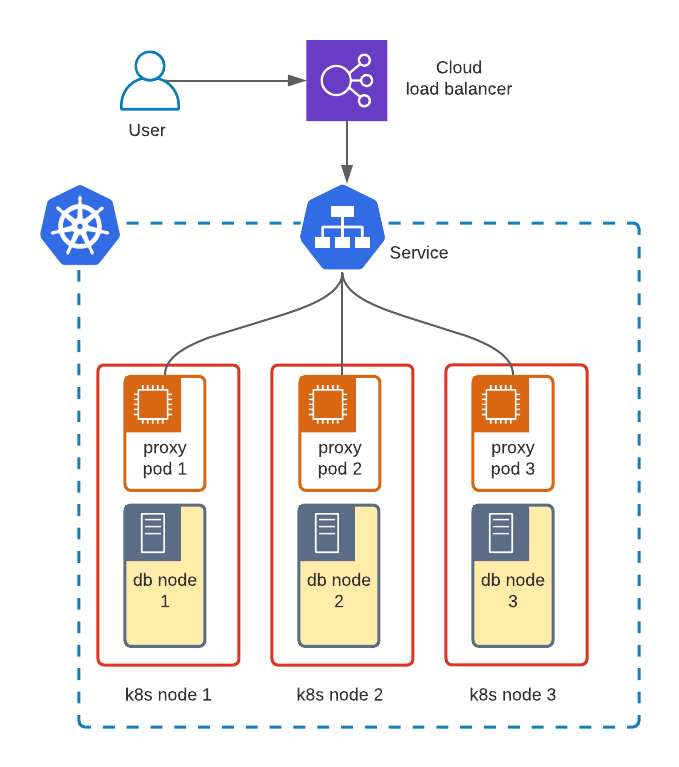
Now DBaaS needs to give the user the endpoint to connect to the database. Remember, if we want our database service to be highly available we run multiple DB nodes.
In Percona Operator for Percona XtraDB Cluster users can choose HAProxy or ProxySQL for traffic balancing across the nodes. The proxy will be deployed along with the DB nodes to balance the traffic between them and monitor the DB node’s health. Without these proxies either the application needs to figure out where to route the traffic itself or use some other external proxy.
The next step is to expose the proxy outside of Kubernetes using regular primitives: LoadBalancer, Ingress with TCP or NodePort, and return the endpoint information to the user.
Once the platform design is ready and users are happy with Day 1 operations – getting the database up and running – comes Day 2, where DBaaS automates the day-to-day routines.
Kubernetes by design provides scaling capabilities. You can read more about it in my previous blog post Kubernetes Scaling Capabilities with Percona XtraDB Cluster.
DBaaS scaling boils down to increasing the resources of the Kubernetes cluster and then the Pods. The steps may differ depending on the chosen topology, but general capacity rules still apply and Pods will not be scheduled if there is not enough capacity.
Preferably DBaaS should provide automated database upgrades at least for minor versions, otherwise, every security vulnerability or bug in the DB engine would force users to perform manual upgrades.
Percona Operators have a Smart Update feature that asks check.percona.com for the latest version of the component, fetches the latest docker image, and safely rolls it out relying on Kubernetes automation.
Every DBA at least once in their life dropped the production database. This is where backups come in handy. DBaaS must also automate backup management and lifecycle.
Usually, DB engines already come with the tools to take and restore backups (mysqldump, mongodump, XtraBackup, etc.). The goal here is to embed these tools into Kubernetes world and give users a clear interface to interact with backups.
Percona Operators provide Custom Resources for backups and rely on a Cronjob object to execute a sequence of commands on schedule. DBaaS in this case can be easily integrated and trigger backups and restores by simply pushing the manifests through the K8S control plane.
Recovering from backup which is a few hours old might not be an acceptable option for critical data. Rolling back the transaction or recovering the data to the latest possible state are the most common use cases for point-in-time recovery (PITR). Most databases have the capability to perform PITR, but they are not designed for the cloud-native world. The recently released version 1.7.0 of Percona XtraDB Cluster Operator provides PITR support out of the box. In future blog posts, we will tell you more about the challenges and technical design of the solution.
Kubernetes vigorously embraces the ephemeral nature of the containers and takes it to the next level by making nodes ephemeral as well. This complicates the regular monitoring approach, where the IP-addresses and ports of the services are well known and probed by the monitoring server. Luckily, the cloud-native landscape is full of monitoring tools that can solve this problem. Take a look at Prometheus Operator, for example.
In Percona we have our own dashing Percona Monitoring and Management (PMM) tool, which integrates with our Operators automatically. To solve the challenge of ephemeral IP-addresses and ports we switched our time-series database from Prometheus to VictoriaMetrics, which allows pushing the metrics, instead of pulling.
It is definitely fun to build DBaaS on Kubernetes and there are multiple ways on how to achieve this goal. The easiest way to do it is by leveraging Operators, as they automate out most of the manual burden. Delivering DBaaS requires rigorous planning and a deep understanding of the user requirements.
In January we kicked off the Preview of Database as a Service in Percona Monitoring and Management. It is fully open source and runs on our Operators in the background to provide the database. We are still looking for users to test and provide feedback during this year-long program, and we would be grateful for your participation and feedback!
Learn more about Percona Kubernetes Operators for Percona XtraDB Cluster or Percona Server for MongoDB
Resources
RELATED POSTS




