
 Our recent survey showed that many organizations saw unexpected growth around cloud and data. Unexpected bills can become a big problem, especially in such uncertain times. This blog post talks about how Kubernetes scaling capabilities work with Percona Kubernetes Operator for Percona XtraDB Cluster (PXC Operator) and can help you to control the bill.
Our recent survey showed that many organizations saw unexpected growth around cloud and data. Unexpected bills can become a big problem, especially in such uncertain times. This blog post talks about how Kubernetes scaling capabilities work with Percona Kubernetes Operator for Percona XtraDB Cluster (PXC Operator) and can help you to control the bill.
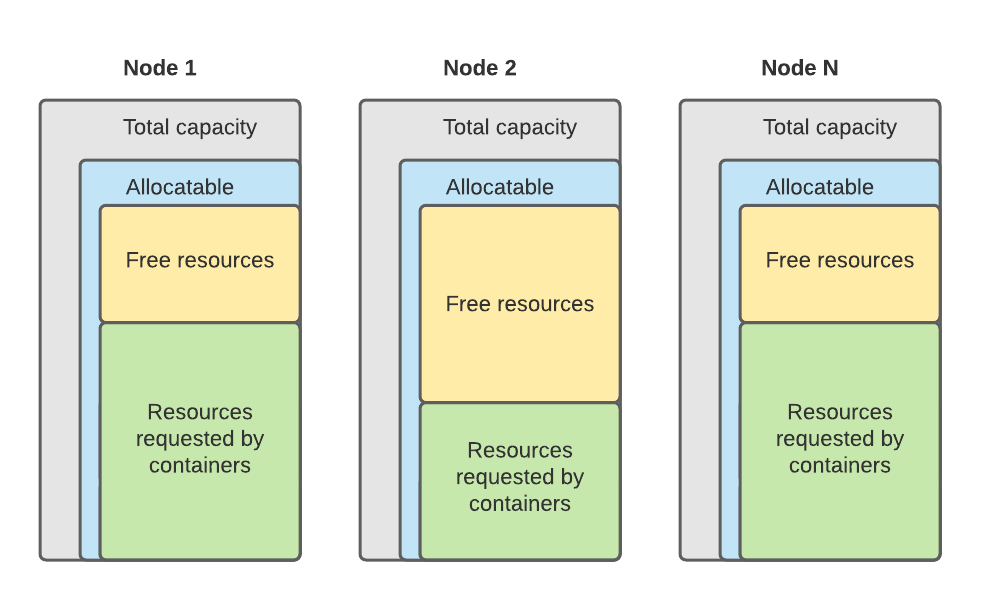
Kubernetes is a container orchestrator and on top of it, it has great scaling capabilities. Scaling can help you to utilize your cluster better and do not waste money on excessive capacity. But before scaling we need to understand what capacity is and how Kubernetes manages CPU and memory resources.
There are two resource concepts that you should be aware of: requests and limits. Requests is the amount of CPU or memory that a container is guaranteed to get on the node. Kubernetes uses requests during scheduling decisions, and it will not schedule a container to a node that does not have enough capacity. Limits is the maximum amount of resources that a container can get on the node. There is no guarantee though. In Linux, world limits are just cgroup maximums for processes.
Each node in a cluster has its own capacity. Part of this capacity is reserved for the operating system and kubelet, and what is left can be utilized by containers (allocatable).
Okay, now we know a thing or two about resource allocation in Kubernetes. Let’s dive into the problem space.
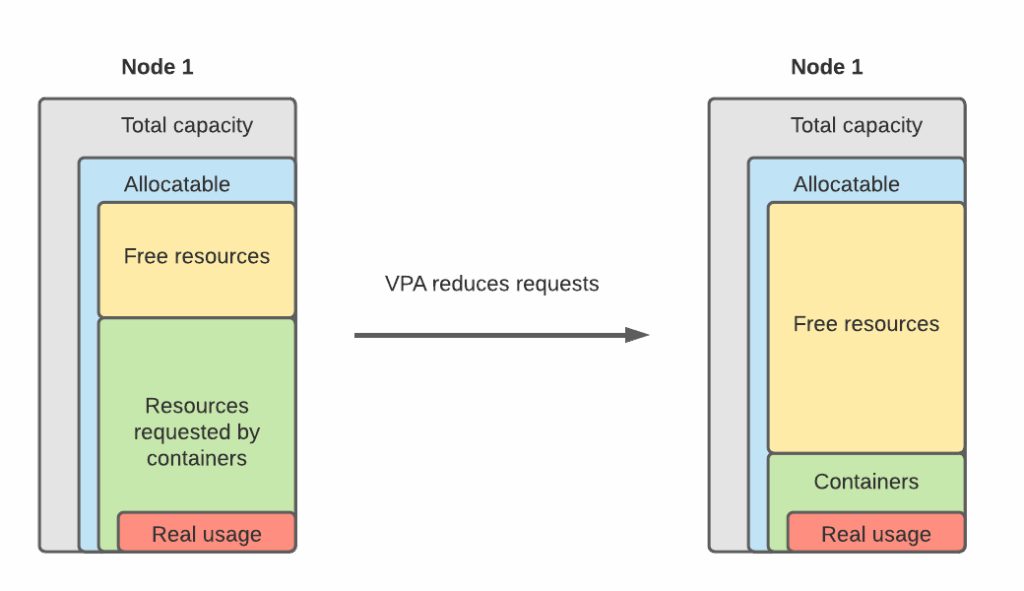
If you request resources for containers but do not utilize them well enough, you end up wasting resources. This is where Vertical Pod Autoscaler (VPA) comes in handy. It can automatically scale up or down container requests based on its historical real usage.
VPA has 3 modes:
As a starting point, deploy Percona Kubernetes Operator for Percona XtraDB Cluster and the database by following the guide. VPA is deployed via a single command (see the guide here). VPA requires a metrics-server to get real usage for containers.
We need to create a VPA resource that will monitor our PXC cluster and provide recommendations for requests tuning. For recommender mode set UpdateMode to “Off”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ cat vpa.yaml apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: pxc-vpa spec: targetRef: apiVersion: "apps/v1" kind: StatefulSet name: <name of the STS> namespace: <your namespace> updatePolicy: updateMode: "Off" |
Run the following command to get the name of the StatefulSet:
|
1 2 3 4 |
$ kubectl get sts NAME READY AGE ... cluster1-pxc 3/3 3h47m |
The one with -pxc has the PXC cluster. Apply the VPA object:
|
1 |
$ kubectl apply -f vpa.yaml |
After a few minutes you should be able to fetch recommendations from the VPA object:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ kubectl get vpa pxc-vpa -o yaml ... recommendation: containerRecommendations: - containerName: pxc lowerBound: cpu: 25m memory: "503457402" target: cpu: 25m memory: "548861636" uncappedTarget: cpu: 25m memory: "548861636" upperBound: cpu: 212m memory: "5063059194" |
Resources in the target section are the ones that VPA recommends and applies if Auto or Initial modes are configured. Read more here to understand other recommendation sections.
VPA will apply the recommendations once it is running in Auto mode and will persist the recommended configuration even after the pod being restarted. To enable Auto mode patch the VPA object:
|
1 |
$ kubectl patch vpa pxc-vpa --type='json' -p '[{"op": "replace", "path": "/spec/updatePolicy/updateMode", "value": "Auto"}]' |
After a few minutes, VPA will restart PXC pods and apply recommended requests.
|
1 2 3 4 5 |
$ kubectl describe pod cluster1-pxc-0 ... Requests: cpu: "25m" memory: "548861636" |
Delete VPA object to stop autoscaling:
|
1 |
$ kubectl delete vpa pxc-vpa |
Please remember few things about VPA and Auto mode:
|
1 2 |
podDisruptionBudget: maxUnavailable: 1 |
The utilization of the application might change over time. It can happen gradually, but what if it is daily spikes of usage or completely unpredictable patterns? Constantly running additional containers is an option, but it leads to resource waste and increases in infrastructure costs. This is where Horizontal Pod Autoscaler (HPA) can help. It monitors container resources or even application metrics to automatically increase or decrease the number of containers serving the application.
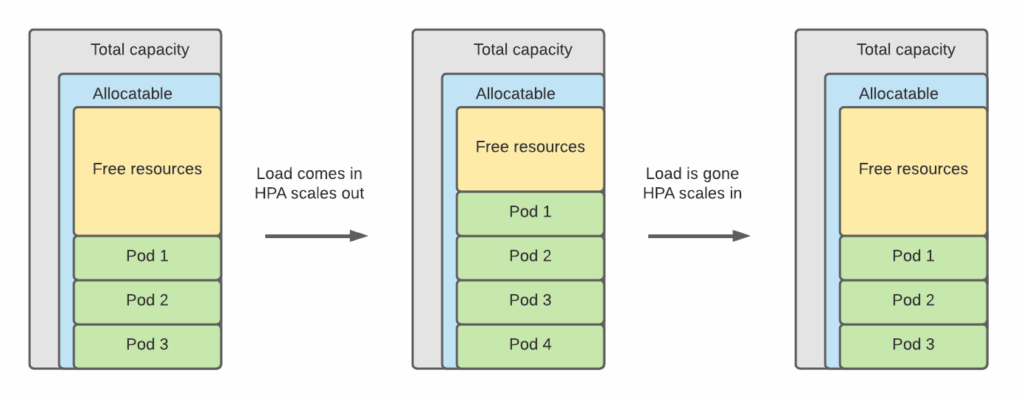
Looks nice, but unfortunately, the current version of the PXC Operator will not work with HPA. HPA tries to scale the StatefulSet, which in our case is strictly controlled by the operator. It will overwrite any scaling attempts from the horizontal scaler. We are researching the opportunities to enable this support for PXC Operator.
You have tuned resources requests and they are close to real usage, but the cloud bill is still not going down. It might be that your Kubernetes cluster is overprovisioned and should be scaled with Cluster Autoscaler. CA adds and removes nodes to your Kubernetes cluster based on their requests usage. When nodes are removed pods are rescheduled to other nodes automatically.
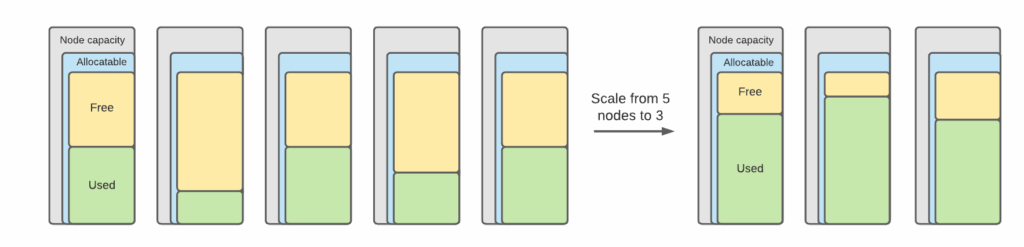
On Google, Kubernetes Engine Cluster Autoscaler can be enabled through gcloud utility. On AWS you need to install autoscaler manually and add corresponding autoscaling groups into the configuration.
In general, CA monitors if there are any pods that are in Pending status (waiting to be scheduled, read more on pod statuses here) and adds more nodes to the cluster to meet the demand. It removes nodes if it sees the possibility to pack pods densely on other nodes. To add and remove nodes it relies on the cloud primitives: node groups in GCP, auto-scaling groups in AWS, virtual machine scale set on Azure, and so on. The installation of CA differs from cloud to cloud, but here are some interesting tricks.
If your workloads are scaling up CA needs to provision new nodes. Sometimes it might take a few minutes. If there is a requirement to scale faster it is possible to overprovision the cluster. Detailed instruction is here. The idea is to always run pause pods with low priority, real workloads with higher priority push them out from nodes when needed.
Expanders control how to scale up the cluster; which nodes to add. Configure expanders and multiple node groups to fine-tune the scaling. My preference is to use priority expander as it allows us to cherry-pick the nodes by customizable priorities, it is especially useful for a rapidly changing spot market.
Pay extremely close attention to scaling down. First of all, you can disable it completely by setting scale-down-enabled to false (not recommended). For clusters with big nodes with lots of pods be careful with scale-down-utilization-threshold – do not set it to more than 50%, it might impact other nodes and overutilize them. For clusters with a dynamic workload and lots of nodes do not set scale-down-delay-after-delete and scale-down-unneeded-time too low, it will lead to non-stop cluster scaling with absolutely no value.
Cluster Autoscaler also respects podDistruptionBudget . When you run it along with PXC Operator please make sure PDBs are correctly configured, so that the PXC cluster does not crash in the event of scaling down the Kubernetes.
In cloud environments, day two operations must include cost management. Overprovisioning Kubernetes clusters is a common theme that can quickly become visible in the bills. When running Percona XtraDB Cluster on Kubernetes you can leverage Vertical Pod Autoscaler to tune requests and apply Cluster Autoscaler to reduce the number of instances to minimize your cloud spend. It will be possible to use Horizontal Pod Autoscaler in future releases as well to dynamically adjust your cluster to demand.
Resources
RELATED POSTS




