
 Recently I posted about checkpointing in MySQL, where MySQL showed interesting “wave” behavior.
Recently I posted about checkpointing in MySQL, where MySQL showed interesting “wave” behavior.
Soon after Dimitri posted a solution with how to fix “waves,” and I would like to dig a little more into proposed suggestions, as there are some materials to process.
This post will be very heavy on InnoDB configuration, so let’s start with the basic configuration for MySQL, but before that some initial environment.
I use MySQL version 8.0.21 on the hardware as described here.
As for the storage, I am not using some “old dusty SSD”, but production available Enterprise-Grade Intel SATA SSD D3-S4510. This SSD is able to handle the throughput of 468MiB/sec of random writes or 30000 IOPS of random writes of 16KiB blocks.
So initial configuration for my test was:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
[mysqld] datadir= /data/mysql8-8.0.21 user=mysql bind_address = 0.0.0.0 socket=/tmp/mysql.sock log-error=error.log ssl=0 performance_schema=OFF skip_log_bin server_id = 7 # general table_open_cache = 200000 table_open_cache_instances=64 back_log=3500 max_connections=4000 join_buffer_size=256K sort_buffer_size=256K # files innodb_file_per_table innodb_log_file_size=10G innodb_log_files_in_group=2 innodb_open_files=4000 # buffers innodb_buffer_pool_size= 140G innodb_buffer_pool_instances=8 innodb_page_cleaners=8 innodb_purge_threads=4 innodb_lru_scan_depth=512 innodb_log_buffer_size=64M default_storage_engine=InnoDB innodb_flush_log_at_trx_commit = 1 innodb_doublewrite= 1 innodb_flush_method = O_DIRECT innodb_file_per_table = 1 innodb_io_capacity=2000 innodb_io_capacity_max=4000 innodb_flush_neighbors=0 #innodb_monitor_enable=all max_prepared_stmt_count=1000000 innodb_adaptive_hash_index=1 innodb_monitor_enable='%' innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF |
There is a lot of parameters, so let’s highlight the most relevant for this test:
|
1 |
innodb_buffer_pool_size= 140G |
Buffer pool size is enough to fit all data, which is about 100GB in size
|
1 |
innodb_adaptive_hash_index=1 |
Adaptive hash index is enabled (as it comes in default InnoDB config)
|
1 |
innodb_buffer_pool_instances=8 |
This is what defaults provide, but I will increase it, following my previous post.
|
1 2 3 |
innodb_log_file_size=10G innodb_log_files_in_group=2 |
These parameters define the limit of 20GB for our redo logs, and this is important, as our workload will be “redo-log” bounded, as we will see from the results
|
1 2 3 |
innodb_io_capacity=2000 innodb_io_capacity_max=4000 |
You may ask, why do I use 2000 and 4000, while the storage can handle 30000 IOPS.
This is a valid point, and as we can see later, these parameters are not high enough for this workload, but also it does not mean we should use them all the way up to 30000, as we will see from the results.
MySQL Manual says the following about innodb_io_capacity:
“The innodb_io_capacity variable defines the overall I/O capacity available to InnoDB. It should be set to approximately the number of I/O operations that the system can perform per second (IOPS). When innodb_io_capacity is set, InnoDB estimates the I/O bandwidth available for background tasks based on the set value.”
From this, you may get the impression that if you set innodb_io_capacity to I/O bandwidth of your storage, you should be fine. Though this part does not say what you should take as I/O operations. For example, if your storage can perform 500MB/sec, then if you do 4KB block IO operations it will be 125000 IO per second, and if you do 16KB IO, then it will be 33000 IO per second.
MySQL manual leaves it up to your imagination, but as InnoDB typical page size is 16KB, let’s assume we do 16KB blocks IO.
However later on that page, we can read:
“Ideally, keep the setting as low as practical, but not so low that background activities fall behind. If the value is too high, data is removed from the buffer pool and change buffer too quickly for caching to provide a significant benefit. For busy systems capable of higher I/O rates, you can set a higher value to help the server handle the background maintenance work associated with a high rate of row changes”
and
“Consider write workload when tuning innodb_io_capacity. Systems with large write workloads are likely to benefit from a higher setting. A lower setting may be sufficient for systems with a small write workload.”
I do not see that the manual provides much guidance about what value I should use, so we will test it.
So if we benchmark with initial parameters, we can see the “wave” pattern.
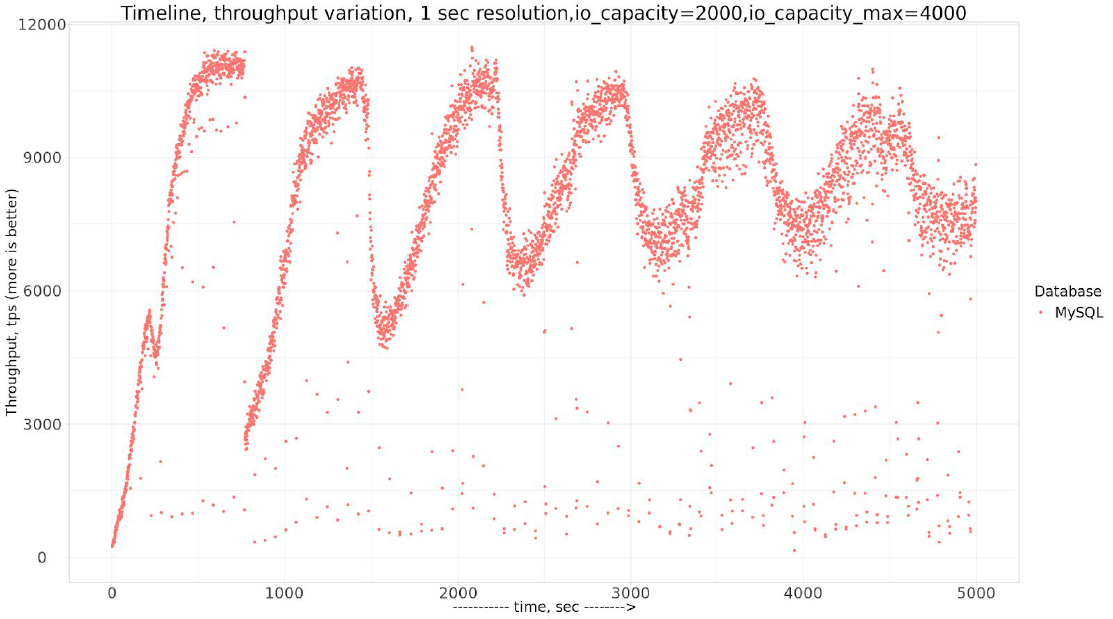
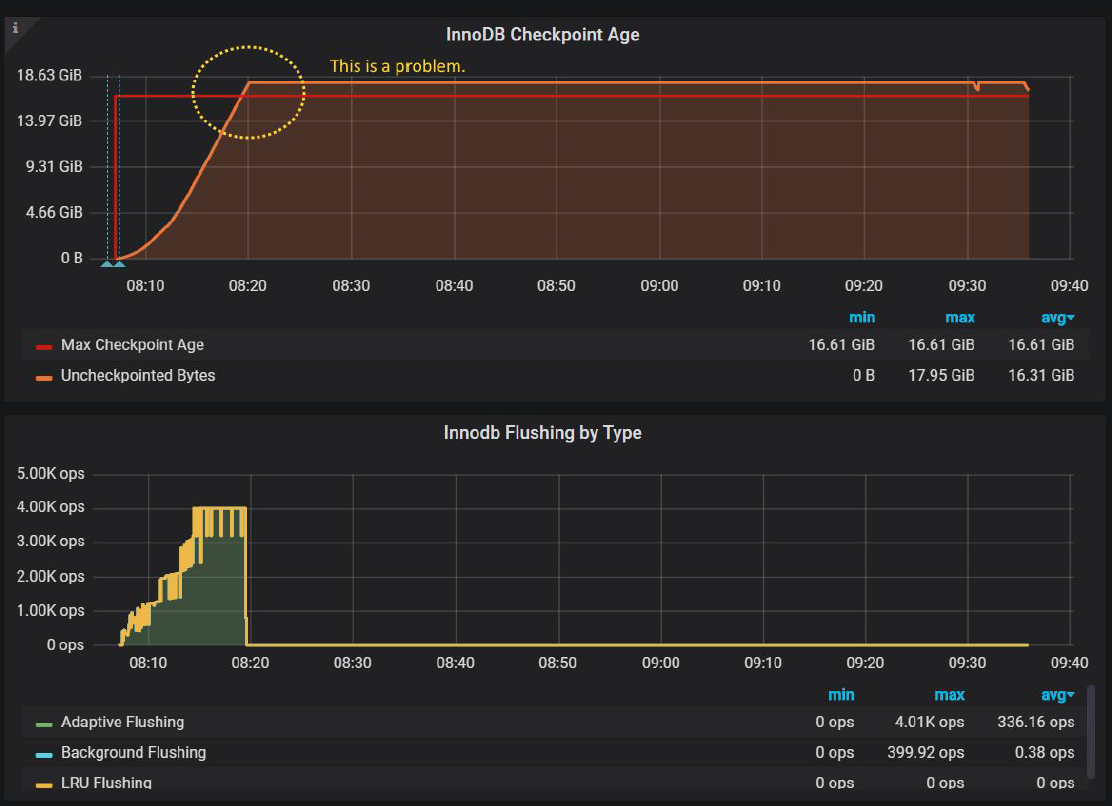
As for why this is happening, let’s check Percona Monitoring and Management “InnoDB Checkpoint Age” chart:
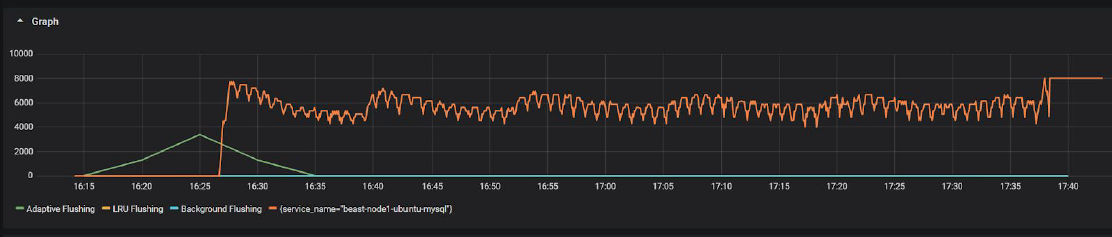
Actually InnoDB Flushing by Type in PMM does not show sync flushing yet, so I had to modify chart a little to show “sync flushing” in orange line:
And we immediately see that Uncheckpointed Bytes exceed Max Checkpoint Age in 16.61GiB, which is defined by 20GiB of innodb log files. 16.61GiB is less than 20GB, because InnoDB reserves some cushion for the cases exactly like this, so even if we exceed 16.61GiB, InnoDB still has an opportunity to flush data.
Also, we see that before Uncheckpointed Bytes exceed Max Checkpoint Age, InnoDB flushes pages with the rate 4000 IOPS, just as defined by innodb_io_capacity_max.
We should try to avoid the case when Uncheckpointed Bytes exceed Max Checkpoint Age, because when it happens, InnoDB gets into “emergency” flushing mode, and in fact, this is what causes the waves we see. I should have detected this in my previous post, mea culpa.
So the first conclusion we can make – if InnoDB does not flush fast enough, what if we increase innodb_io_capacity_max ? Sure, let’s see. And for the simplification, for the next experiments, I will use
Innodb_io_capacity = innodb_io_capacity_max, unless specified otherwise.
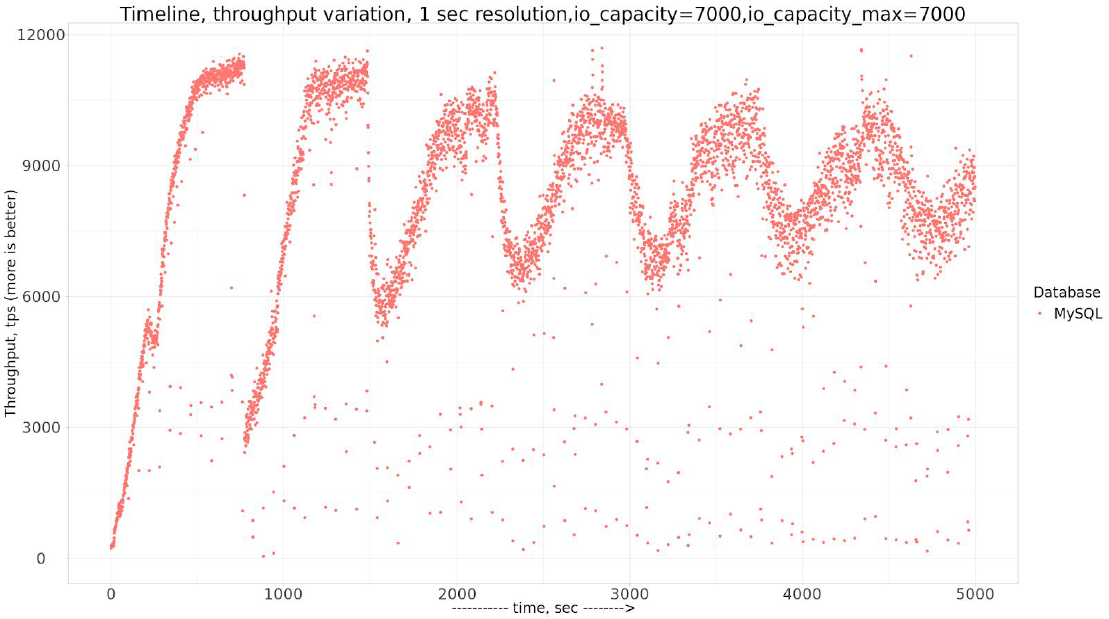
Not much improvement and this also confirmed by InnoDB Checkpoint ge chart
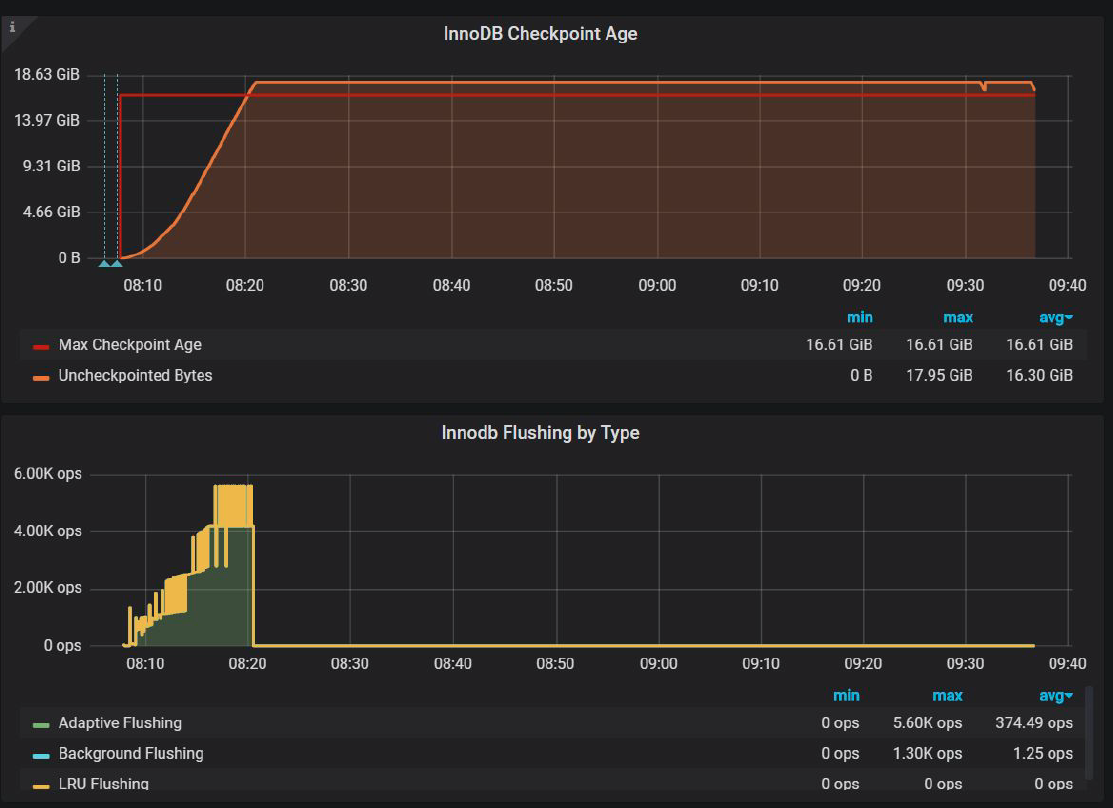
InnoDB tries to flush more pages per second up to 5600 pages/sec, but it is not enough to avoid exceeding Max Checkpoint Age.
Why is this the case? The answer is a double write buffer.
Even though MySQL improved the doublewrite buffer in MySQL 8.0.20, it does not perform well enough with proposed defaults.
Well, at least the problem was solved because previous Oracle ran benchmarks with disabled doublewrite, just to hide and totally ignore the issue with doublewrite. For the example check this.
But let’s get back to our 8.0.21 and fixed doublewrite.
Dimiti mentions:
“the main config options for DBLWR in MySQL 8.0 are:
|
1 2 |
innodb_doublewrite_files = N innodb_doublewrite_pages = M" |
Let’s check the manual again:
“The innodb_doublewrite_files variable is intended for advanced performance tuning. The default setting should be suitable for most users.“
The innodb_doublewrite_pages variable (introduced in MySQL 8.0.20) controls the number of maximum number of doublewrite pages per thread. If no value is specified, innodb_doublewrite_pages is set to the innodb_write_io_threads value. This variable is intended for advanced performance tuning. The default value should be suitable for most users.“
Was it wrong to assume that innodb_doublewrite_files and innodb_doublewrite_pages provides the value suitable for our use case?
But let’s try with the values Dmitri recommended to look into, I will use
|
1 |
innodb_doublewrite_files=2 and innodb_doublewrite_pages=128 |
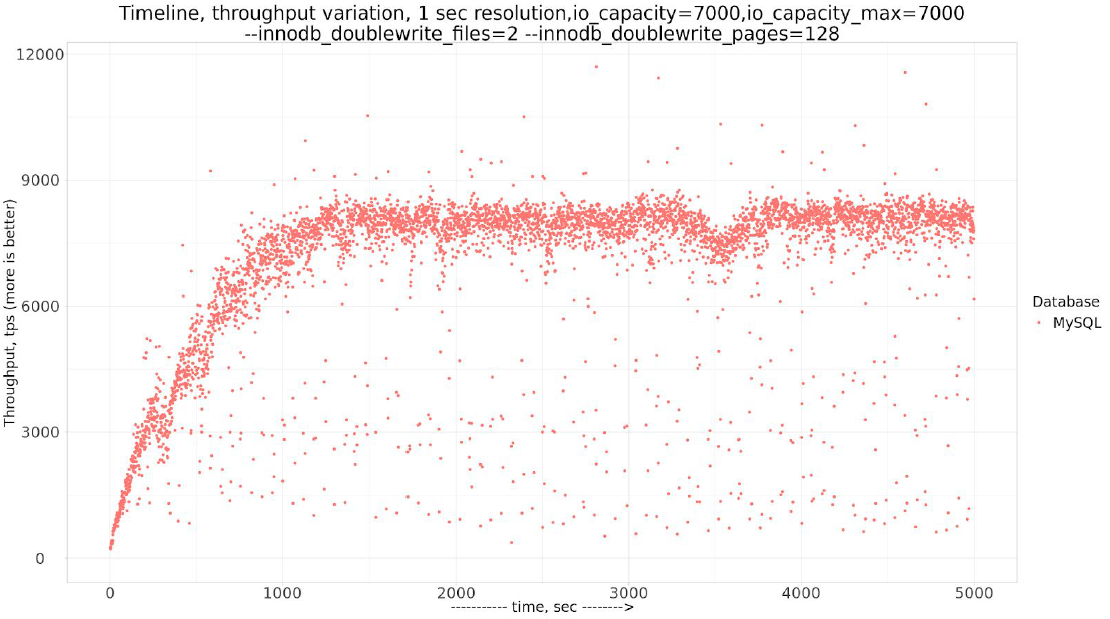
The problem with waves is fixed!
And InnoDB Checkpoint Age chart:
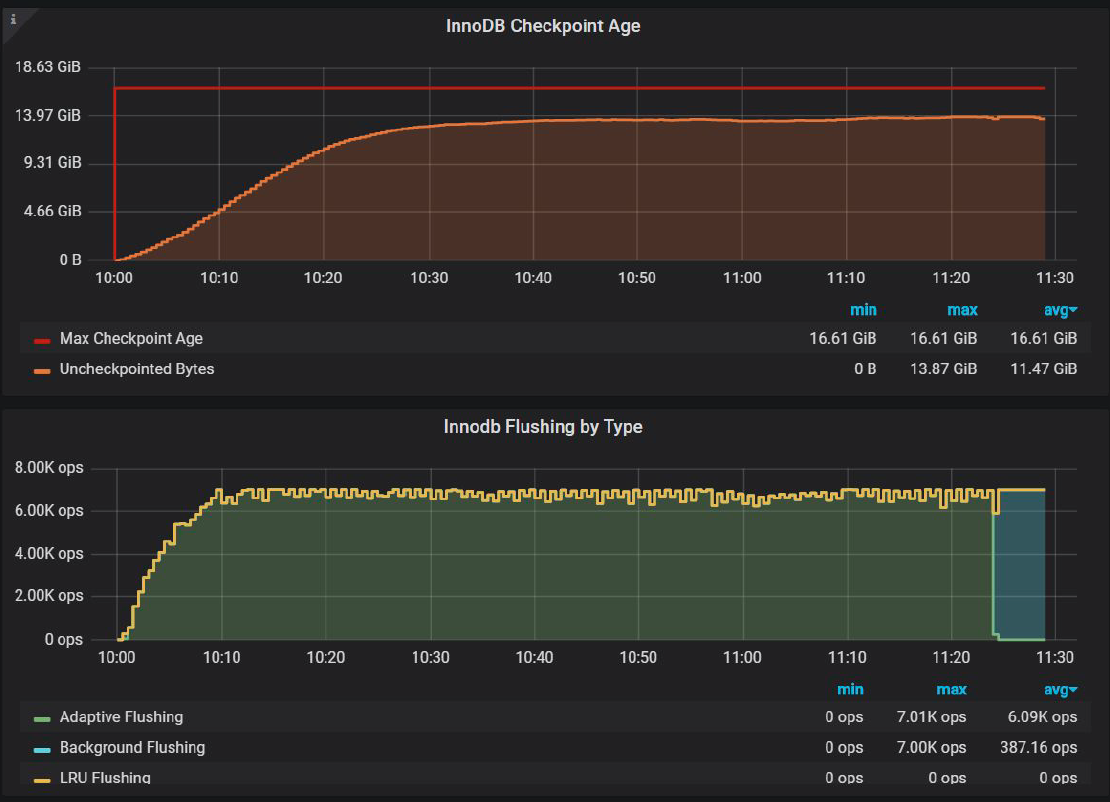
Now we are able to keep Uncheckpointed Bytes under Max Checkpoint Age, and this is what fixed “waves” pattern.
We can say that parallel doublewrite is a new welcomed improvement, but the fact that one has to change innodb_doublewrite_pages in order to get improved performance is the design flaw in my opinion.
But there are still a lot of variations in 1 sec resolution and small drops. Before we get to them, let’s take a look at another suggestion: use –innodb_adaptive_hash_index=0 ( that is to disable Adaptive Hash Index). I will use AHI=0 on the charts to mark this setting.
Let’s take a look at the results with improved settings and with –innodb_adaptive_hash_index=0
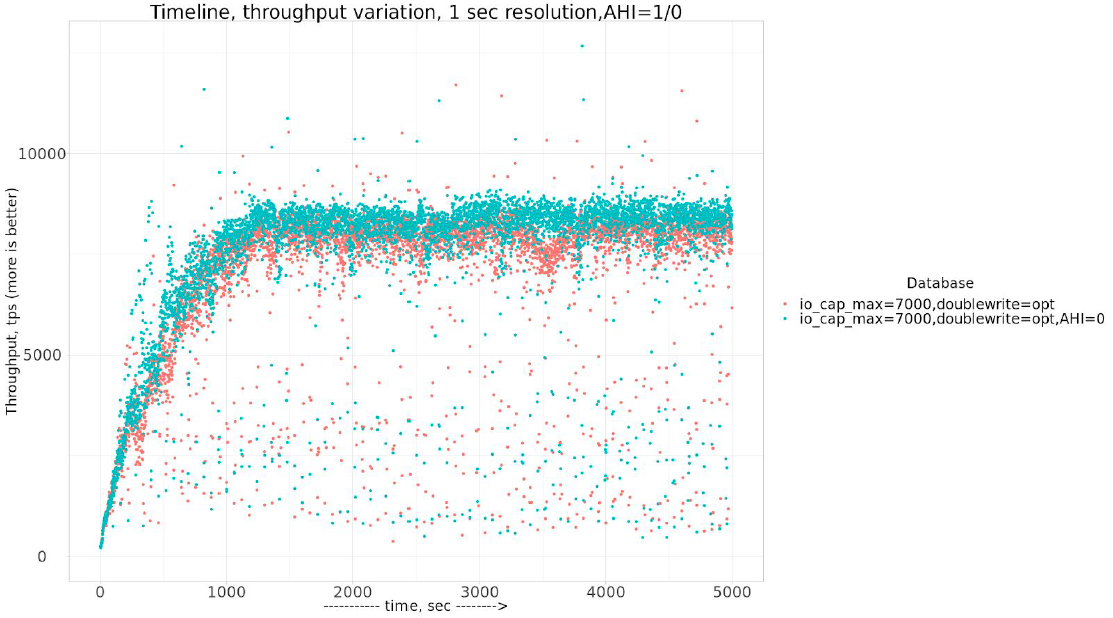
To see what is the real improvement with –innodb_adaptive_hash_index=0 , let’s compare barcharts:
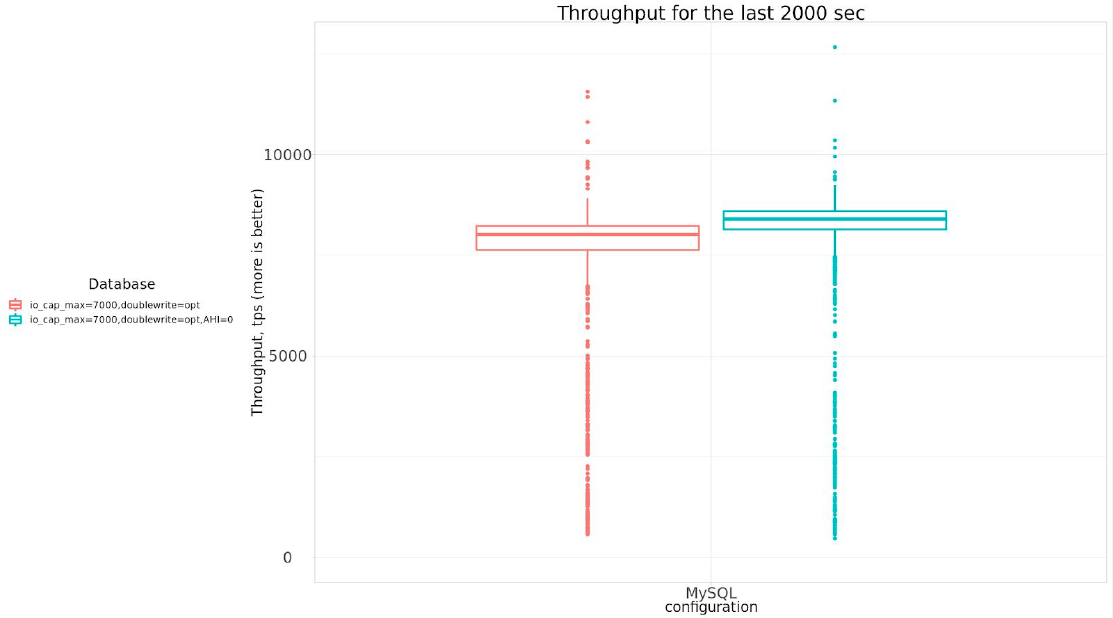
Or in numeric form:
| settings | Avg tps, last 2000 sec |
| io_cap_max=7000,doublewrite=opt | 7578.69 |
| io_cap_max=7000,doublewrite=opt,AHI=0 | 7996.33 |
So –innodb_adaptive_hash_index=0 really brings some improvements, about 5.5%, so I will use –innodb_adaptive_hash_index=0 for further experiments.
Let’s see if increased innodb_buffer_pool_instances=32 will help to smooth periodical variance.
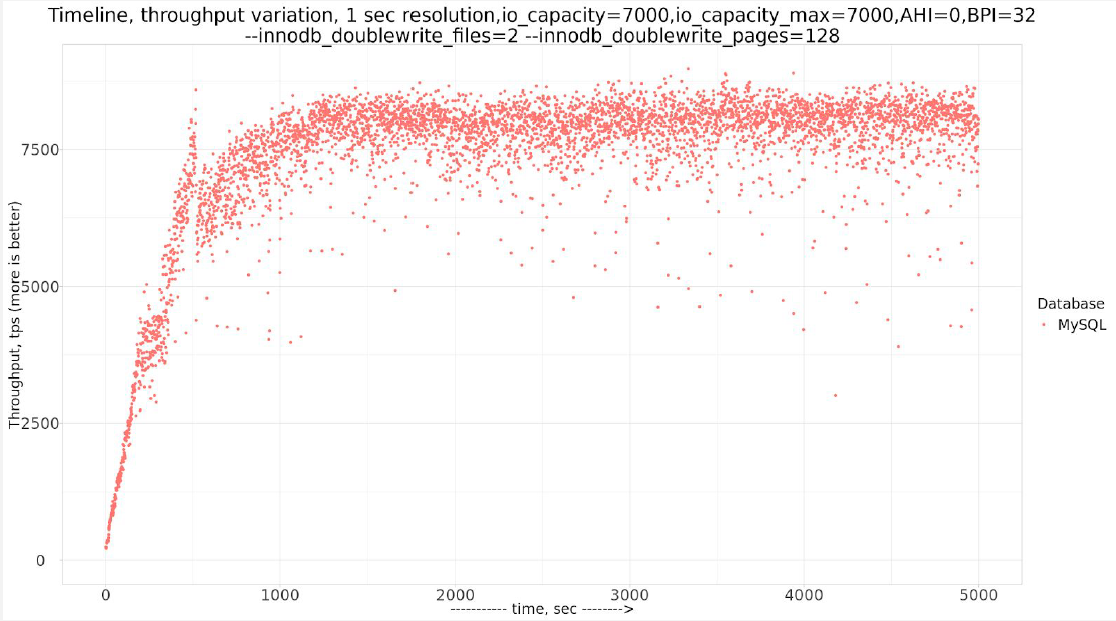
So indeed using innodb_buffer_pool_instances=32 gets us less variations, keeping overall throughput about the same. It is 7936.28 tps for this case.
Now let’s review the parameter innodb_change_buffering=none, which Dmitri also suggests.
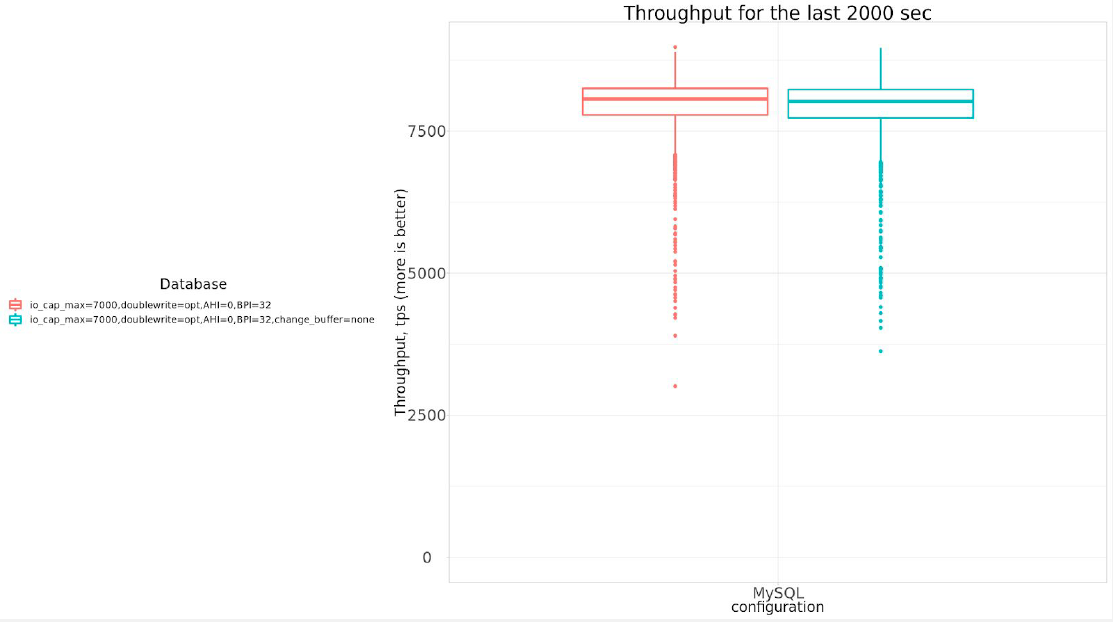
There is NO practical difference if we disable innodb_change_buffer.
And if we take a look at PMM change buffer chart:
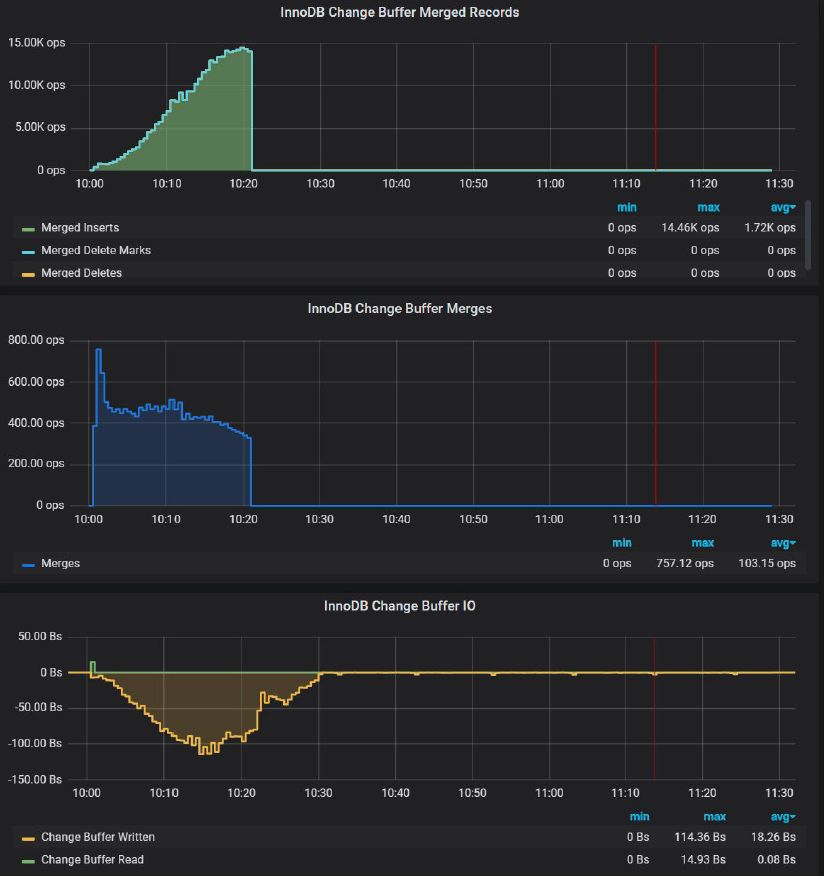
We can see there is NO Change Buffer activity outside of the initial 20 mins. I am not sure why Dimitri suggested disabling it. In fact, Change Buffer can be quite useful, and I will show it in my benchmark for the different workloads.
Now let’s take a look at suggested settings with Innodb_io_capacity = innodb_io_capacity_max = 8000. That will INCREASE innodb_io_capacity_max , and compare to results with innodb_io_capacity_max = 7000.
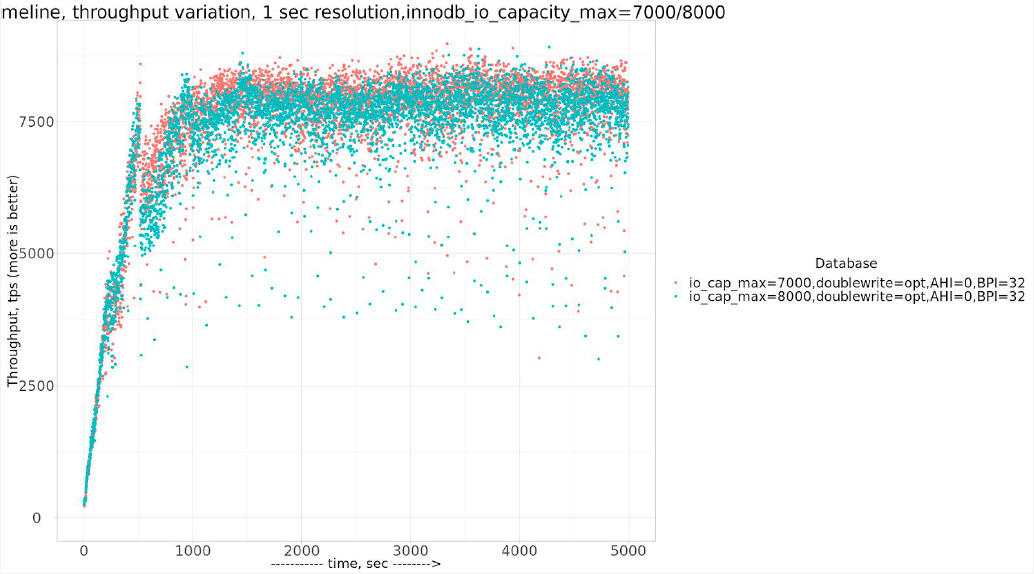
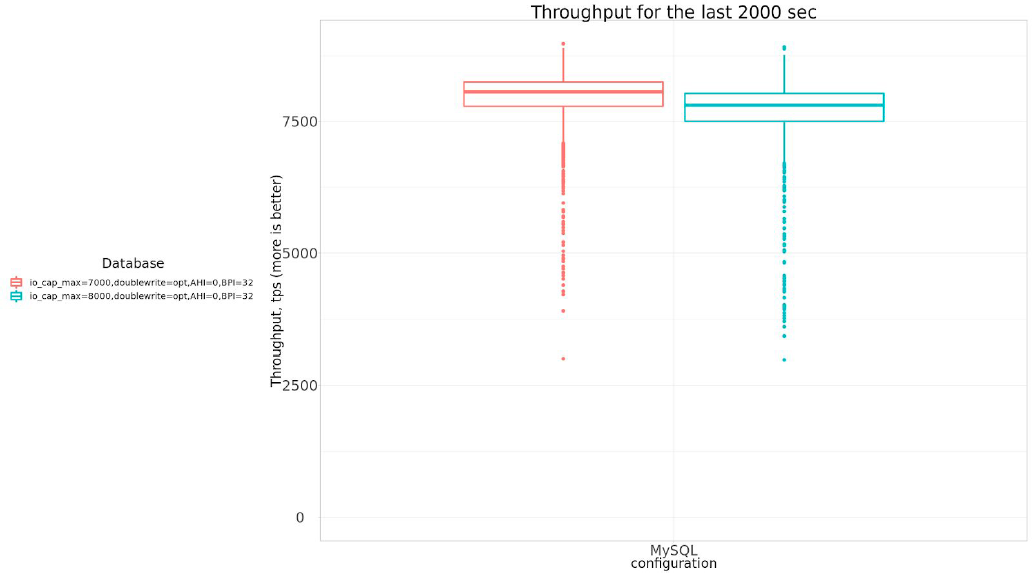
Or in tabular form:
| settings | Avg tps, last 2000 sec |
| io_cap_max=7000,doublewrite=opt,AHI=0,BPI=32 | 7936.28 |
| io_cap_max=8000,doublewrite=opt,AHI=0,BPI=32 | 7693.08 |
Actually with innodb_io_capacity_max=8000 the throughput is LESS than with innodb_io_capacity_max=7000
Can you guess why?
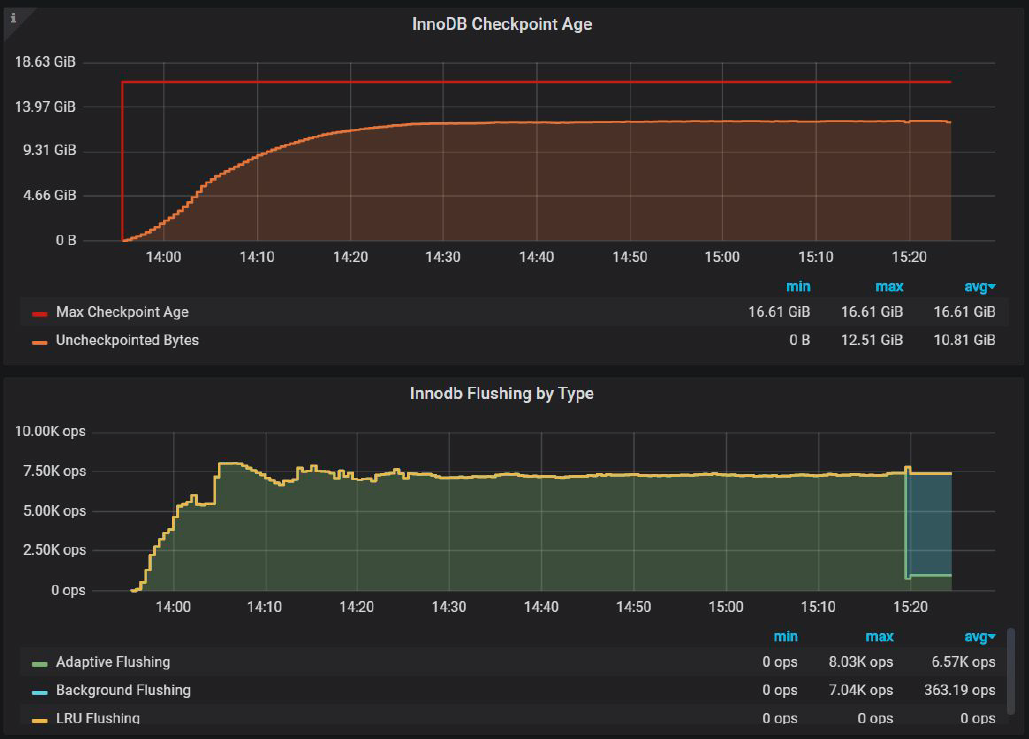
Let’s compare InnoDB Checkpoint Age.
This is for innodb_io_capacity_max=8000 :
And this is for innodb_io_capacity_max=7000
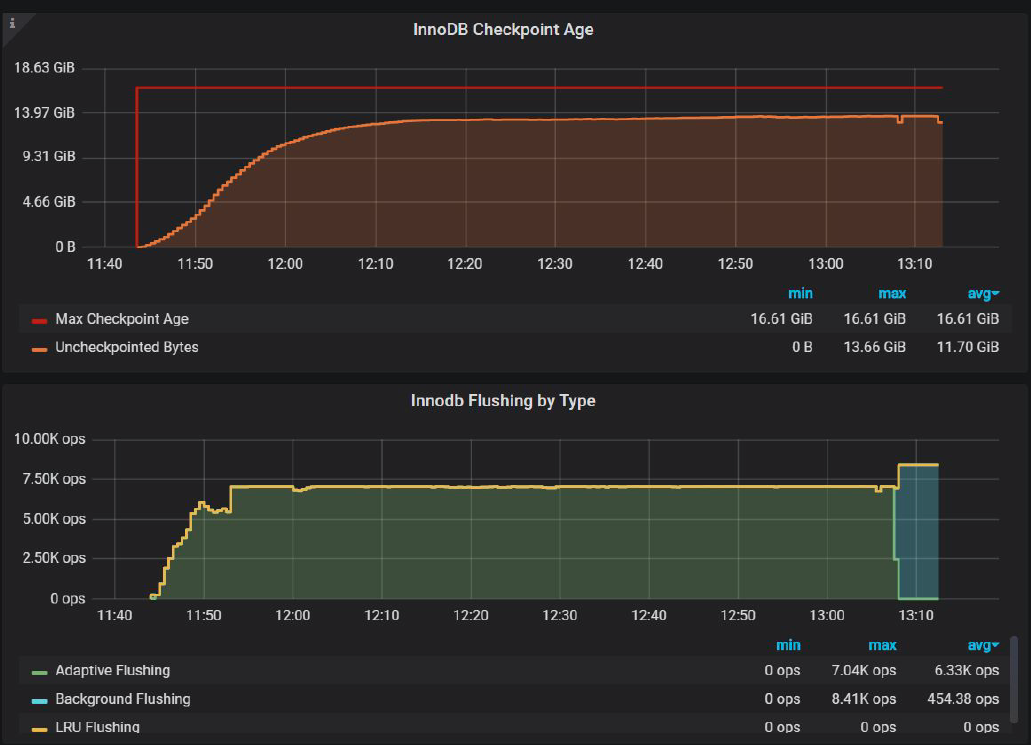
This is like a child’s game: Find the difference.
The difference is that with innodb_io_capacity_max=7000
Uncheckpointed Bytes is 13.66 GiB,
and with innodb_io_capacity_max=8000
Uncheckpointed Bytes is 12.51 GiB
What does it mean? It means that with innodb_io_capacity_max=7000 HAS to flush LESS pages and still keep within Max Checkpoint Age.
In fact, if we try to push even further, and use innodb_io_capacity_max=innodb_io_capacity=6500 we will get InnoDB Checkpoint Age chart as:
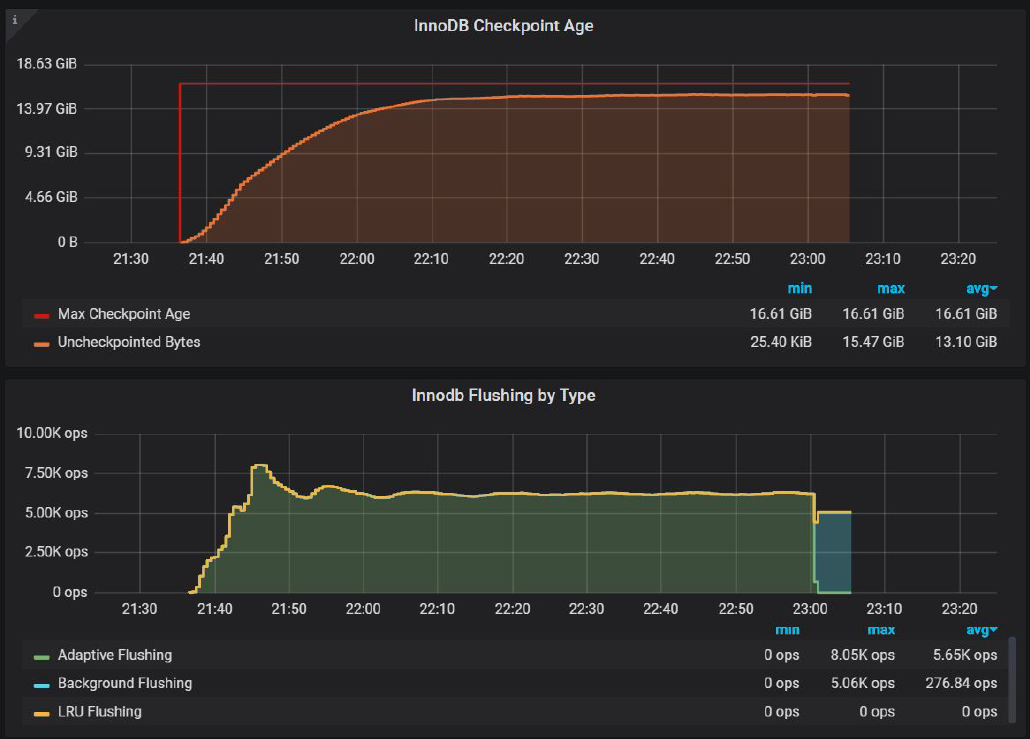
Where Uncheckpointed Bytes are 15.47 GiB. Does it improve throughput? Absolutely!
| settings | Avg tps, last 2000 sec |
| io_cap_max=6500,doublewrite=opt,AHI=0,BPI=32 | 8233.628 |
| io_cap_max=7000,doublewrite=opt,AHI=0,BPI=32 | 7936.283 |
| io_cap_max=8000,io_cap_max=8000,doublewrite=opt,AHI=0,BPI=32 | 7693.084 |
The difference between innodb_io_capacity_max=6500 and innodb_io_capacity_max=8000 is 7%
This now becomes clear what Manual means in the part where it says:
“Ideally, keep the setting as low as practical, but not so low that background activities fall behind”
So we really need to increase innodb_io_capacity_max to the level that Uncheckpointed Bytes stays under Max Checkpoint Age, but not by much, otherwise InnoDB will do more work then it is needed and it will affect the throughput.
In my opinion, this is a serious design flaw in InnoDB Adaptive Flushing, that you actually need to wiggle innodb_io_capacity_max to achieve appropriate results.
To show an even more complicated relation between innodb_io_capacity_max and innodb_log_file_size, let consider the following experiment.
We will increase innodb_log_file_size from 10GB to 20GB, effectively doubling our redo-log capacity.
And now let’s check InnoDB Checkpoint Age with innodb_io_capacity_max=7000:
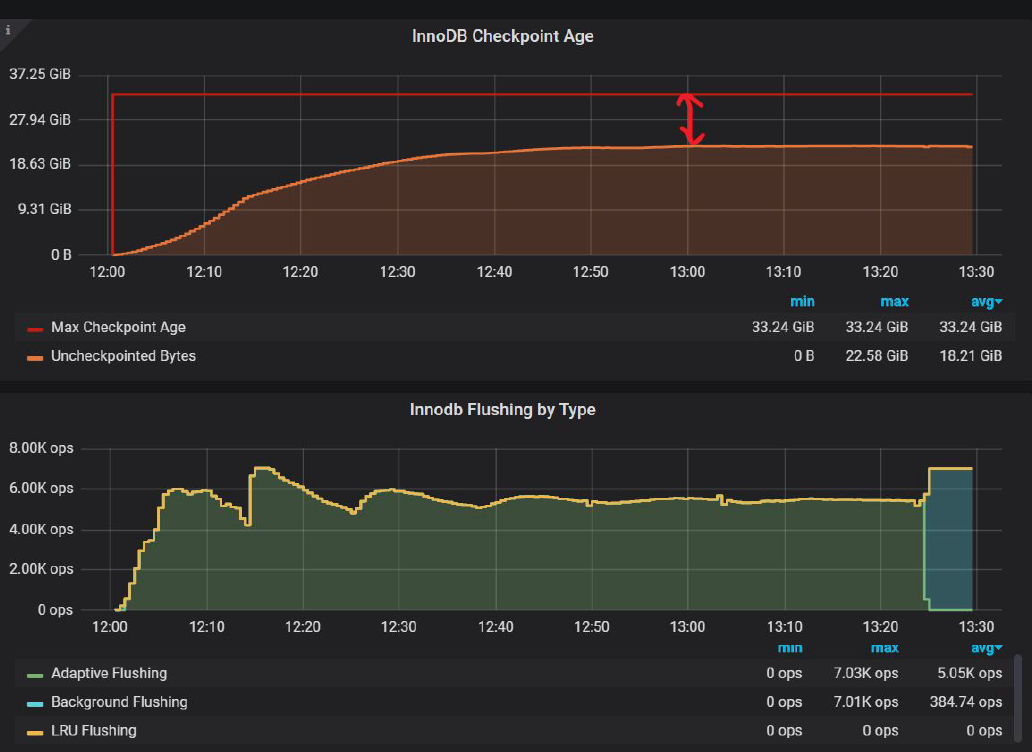
We can see there is a lot of space in InnoDB logs which InnoDB does not use. There is only 22.58GiB of Uncheckpointed Bytes, while 33.24 GiB are available.
So what happens if we increase innodb_io_capacity_max to 4500
InnoDB Checkpoint Age with innodb_io_capacity_max=4500:
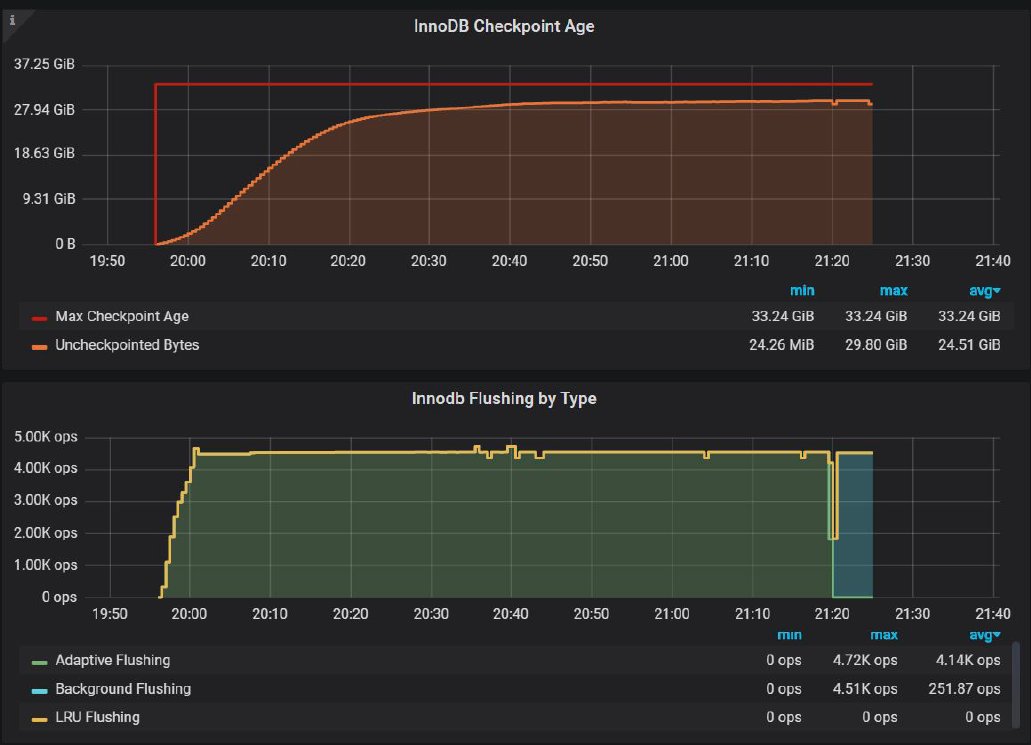
In this setup, We can push Uncheckpointed Bytes to 29.80 GiB, and it has a positive effect on the throughput.
Let’s compare throughput :
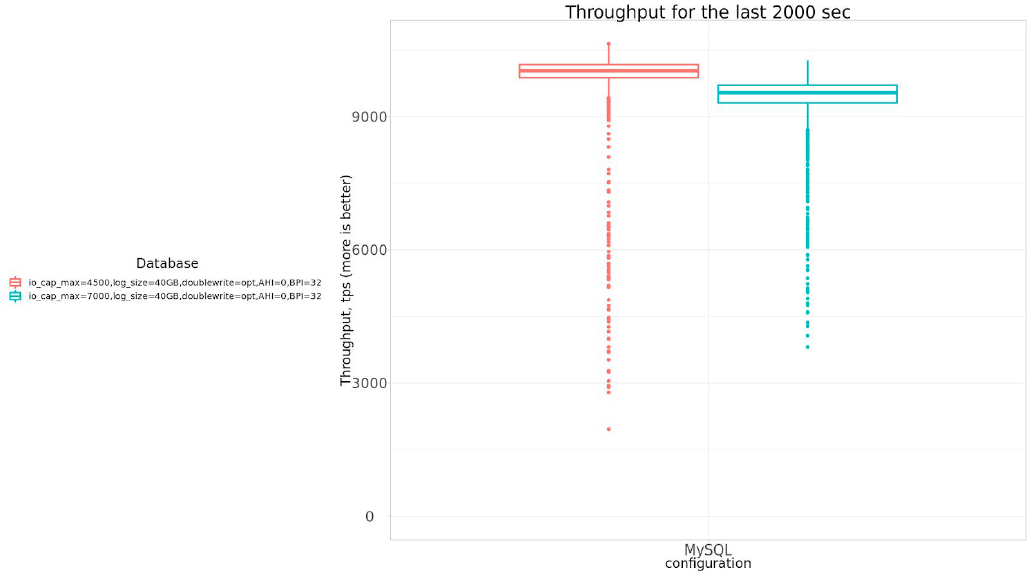
| settings | Avg tps, last 2000 sec |
| io_cap_max=4500,log_size=40GB,doublewrite=opt,AHI=0,BPI=32 | 9865.308 |
| io_cap_max=7000,log_size=40GB,doublewrite=opt,AHI=0,BPI=32 | 9374.121 |
So by decreasing innodb_io_capacity_max from 7000 to 4500 we can gain 5.2% in the throughput.
Please note that we can’t continue to decrease innodb_io_capacity_max, because in this case Uncheckpointed Bytes risks to exceed Max Checkpoint Age, and this will lead to the negative effect of emergency flushing.
So again, in order to improve throughput, we should be DECREASING innodb_io_capacity_max, but only to a certain threshold. We should not be setting innodb_io_capacity_max to 30000, to what really SATA SSD can provide.
Again, for me, this is a major design flaw in the current InnoDB Adaptive Flushing. Please note this was a static workload. If your workload changes during the day, it is practically impossible to come up with optimal value.
Trying to summarize all of the above, I want to highlight:





I’m a little confused – “Oracle implemented (broken by default) parallel doublewrite in MySQL 8.0.20” — Did you mean to say “double write default settings are not optimal for some use cases”. If it’s the former, can you please point to the design flaw.
Sunny,
I meant that defaults are not optimal and it is hard to see what are optimal settings should be.
Back to Dimitri post:
“The default config is generally doing well on fast enough storage”
“To make it short, after few probes, I’ve found that 2 files and 64 pages for DBLWR config will be less or more “good enough” for this SATA SSD.”
To MySQL Manual:
innodb_doublewrite_pages
Defines the maximum number of doublewrite pages per thread for a batch write. If no value is specified, innodb_doublewrite_pages is set to the innodb_write_io_threads value.
innodb_write_io_threads
Default Value 4
I imagine that in your world “fast enough storage” like NVMe devices from Dimitri’s server represents most of use cases, but in my world it is really NVMe devices represent some use case.
So really your statement and manual should say “doublewrite default settings are optimal in some rare use case, otherwise do your guesswork to figure them out”.
Vadim, thanks for the clarification. Can you please amend the conclusion then? The current wording seems to imply a design flaw in the doublewrite buffer.
Regarding improving the doublewrite defaults, there is work underway to improve the doublewrite defaults. The objective is to determine the defaults that will work optimally for all types of storage devices.
Thank you for an educational post. The graphs are awesome. I wish I had the time to do graphs like that on my posts. I also appreciate how detailed recent posts have been in explaining performance problems. And finally I like that reading these posts refreshes my understanding of InnoDB.
I realize it would defeat the purpose of this post, but for a workload where you can afford X GB of RAM then I expect that you can also afford to get as close as possible to X GB of storage for redo. Here there was a 140G buffer pool vs a 20G redo log. That is great for increasing stress on write-back, but I expect a larger redo to avoid some of these problems. Alas, large redo can also mean too long recovery times so my advice isn’t without risk.
Mark,
I agree increase redo-log size will decrease write-back pressure and that’s why I also show results with 40GB of redo space.
We quite regularly see systems with 512GB+ of RAM, so matching redo log space for memory size is not practical on these size, and the crash recovery will take forever (and the recovery is still single-threaded in MySQL). For such systems NVMe of course will be more practical, but also more expensive to allocate 100GB+ for redo space.
Vadim,
I think it would be interesting to separately do the test of Performance and IO volume with different Redo Logs size. so we can get some feel about how large redo log may be optimal. I think right now the advice we have is super general something like “it can be as much as buffer pool size or even higher” but when do we get to diminishing returns ?