
 This post has been written in collaboration with Nicolas Modalvsky of e-planning. Nicolas and I recently worked together on a tuning engagement involving MyRocks on MariaDB. While it is easy to find online articles and posts about InnoDB performance, finding information about MyRocks tuning is more difficult. Both storage engines are well documented but what is really missing are tuning road stories on MyRocks. Those stories are important to help understand the underlying behavior of MyRocks and to help address potential issues.
This post has been written in collaboration with Nicolas Modalvsky of e-planning. Nicolas and I recently worked together on a tuning engagement involving MyRocks on MariaDB. While it is easy to find online articles and posts about InnoDB performance, finding information about MyRocks tuning is more difficult. Both storage engines are well documented but what is really missing are tuning road stories on MyRocks. Those stories are important to help understand the underlying behavior of MyRocks and to help address potential issues.
In this post, we’ll present you one such road story that allowed MyRocks to really shine. We’ll start by providing some context explaining why MyRocks was considered and then, you’ll be invited to follow our tuning iterations.
Nicolas’s company, e-planning, is an online advertising company participating both as seller and buyer in real-time auctions of online ads through the OpenRTB protocol. For data that is used in the auction process, e-planning has servers in eight data centers across the world and uses a mesh-like replication topology with MariaDB GTIDs. Servers are split into three regions: the US, Europe, and Asia. Within each region, a full mesh is implemented between all servers in the region. For instance, in the US region, each database server has 11 replicas and is the replica of 11 other servers. The workload is upsert heavy and almost all queries are idempotent. There are tens of millions of inserts every day and the captured data is valid only for two months. Older data must be pruned. Replicas run on bare metal servers, usually Dual Xeon E5 v3 or v4, with 192 GB to 384 GB of RAM.
Until recently, InnoDB was used and the tables had the MariaDB option page_compressed=1 using zlib. Although the servers were able to process the workload, there were a number of drawbacks:
In order to give some real numbers, here are the metadata of three active tables:
|
1 2 3 4 5 6 7 |
+---------------+---------+--------+---------+-------+---------+--------+ | schema_table | nrows | Data | DataRow | idx | totSize | Engine | +---------------+---------+--------+---------+-------+---------+--------+ | asum.dsp_2 | 599.66M | 49.52G | 89 | 0.00G | 49.52G | InnoDB | | asum.dsp_18 | 672.12M | 45.84G | 73 | 0.00G | 45.84G | InnoDB | | asum.dsp_7 | 650.77M | 30.83G | 51 | 0.00G | 30.83G | InnoDB | +---------------+---------+--------+---------+-------+---------+--------+ |
The combined size of these three tables is approximately 126GB.
Prior to the engagement with Percona, one of the servers was converted to MyRocks and configured with respect to the Facebook MyRocks wiki and other sources on the web. With MariaDB, RocksDB does not support LZ4 and Zstd, and Snappy is used by default. The resulting sizes of the three sample tables were:
|
1 2 3 4 5 6 7 |
+--------------+----------+--------+---------+-------+--------+---------+---------+---------+ | schema_table | nrows | Data | DataRow | idx | IdxRow | totSize | idxfrac | Engine | +--------------+----------+--------+---------+-------+--------+---------+---------+---------+ | asum.dsp_2 | 695.47M | 39.91G | 62 | 0.00G | 0 | 39.91G | 0.00 | ROCKSDB | | asum.dsp_18 | 831.67M | 39.73G | 51 | 0.00G | 0 | 39.73G | 0.00 | ROCKSDB | | asum.dsp_7 | 762.65M | 18.28G | 26 | 0.00G | 0 | 18.28G | 0.00 | ROCKSDB | +--------------+----------+--------+---------+-------+--------+---------+---------+---------+ |
The combined size of the three tables is now about 98GB, a 22% reduction compared to InnoDB. That’s a modest improvement, though a bit disappointing, and we’ll have to work on that front too. However, replication started to lag on nearly all the channels. A number of configuration tweaks were attempted, essentially to various buffers but nothing worked. At this point, Percona was called to the rescue.
A rapid survey of the MyRocks server found a low CPU usage but the storage was quite busy. The database was generating a rather modest rate of small write operations, around 400/s, averaging in size between 2 and 3 KB. Such a write pattern, especially for an LSM engine like RocksDB which essentially just writes sequentially, is a signature of fsync calls. SSDs are awesome for reads, good for writes but only ok for fsyncs.
There are only a few MySQL variables affecting fsyncs, and in the my.cnf, I found the following:
|
1 2 |
sync_binlog=1500 innodb_flush_log_at_trx_commit = 0 |
The binary log is fsynced only once per 1500 transactions and InnoDB was flushing its redo log files only once per second. But what about MyRocks? The variable rocksdb_flush_log_at_trx_commit was missing in the my.cnf and it has a default value of 1, which means one fsync of the RocksDB log file per transaction. Setting rocksdb_flush_log_at_trx_commit to 2 (once per second) allowed replication to immediately start recovering. A great start but the tuning effort was far from over.
Change #1: rocksdb_flush_log_at_trx_commit = 2
The next day, I was expecting the MyRocks server to be in sync with the others but it wasn’t the case. The replication speed slowed down during the night and the most active replication channels were again unable to cope with the incoming write load. The read load was also much higher. What was going on? Raising rocksdb_block_cache_size to 75% of the Ram helped but only a little bit. What did help, for a few hours, was a full manual compaction using:
|
1 |
set global rocksdb_compact_cf = default; |
Unfortunately, a few hours later, the issue was back. What was going on this time? We’ll come back to the read load issue a bit later because a parallel effort was in progress to improve data compression.
For an unknown reason, MariaDB doesn’t support Zstd, the best compressor in my book. The default compression algorithm for RPM-based distro is Snappy. Snappy is quite fast but it is not as efficient. Our goal was to see how LZ4 for the upper LSM level and Zstd for the lowest level would compare. In order to do that, we either need to migrate to Percona Server for MySQL (which includes LZ4 and Zstd compression) or recompile MariaDB. The complex replication topology and the use of the MariaDB GTID implementation led us to favor the second solution so we recompiled MariaDB with the Zstd and LZ4 development libraries installed. The compilation went smoothly and then we updated the column family with:
|
1 |
rocksdb_override_cf_options="default={write_buffer_size=256m;target_file_size_base=32m;max_bytes_for_level_base=512m;max_write_buffer_number=4;level0_file_num_compaction_trigger=4;level0_slowdown_writes_trigger=20;level0_stop_writes_trigger=30;max_write_buffer_number=4;block_based_table_factory={cache_index_and_filter_blocks=1;filter_policy=bloomfilter:10:false;whole_key_filtering=1};level_compaction_dynamic_level_bytes=true;optimize_filters_for_hits=true;memtable_prefix_bloom_size_ratio=0.05;compaction_pri=kMinOverlappingRatio;compression=kLZ4Compression;bottommost_compression=kZSTD;compression_opts=-14:1:0}" |
and we forced a full compaction:
|
1 |
set global rocksdb_compact_cf = default; |
Once done, the results were much better:
|
1 2 3 4 5 6 7 |
+---------------+---------+--------+---------+-------+--------+---------+---------+---------+ | schema_table | nrows | Data | DataRow | idx | IdxRow | totSize | idxfrac | Engine | +---------------+---------+--------+---------+-------+--------+---------+---------+---------+ | asum.dsp_2 | 626.38M | 21.49G | 37 | 0.00G | 0 | 21.49G | 0.00 | ROCKSDB | | asum.dsp_18 | 707.95M | 21.17G | 32 | 0.00G | 0 | 21.17G | 0.00 | ROCKSDB | | asum.dsp_7 | 668.26M | 11.52G | 19 | 0.00G | 0 | 11.52G | 0.00 | ROCKSDB | +---------------+---------+--------+---------+-------+--------+---------+---------+---------+ |
This time the total size of the three tables is down to 54GB; that’s a reduction of 57%. For now, the results are good enough but we could have tried a few more things. For example, the Zstd compression level was only set to ‘1’, the lowest. This is the middle number in compression_opts of the column family definition.
Change #2: LZ4 and Zstd
The impacts on the increasing read load issue were marginal but we were done for the day.
The next morning, we noticed MariaDB had been killed during the night, an OOM kill. It appears to be a known issue with the way RockDB manages its block cache and the glibc malloc. We switched the memory allocator to jemalloc, essentially adding the following section to the my.cnf file:
|
1 2 |
[mysqld_safe] malloc-lib=/usr/lib64/libjemalloc.so.2 |
and the issue was gone.
Change #3: jemalloc
So we were back at the increasing read load issue. After some research and analysis, the issue became obvious. The RocksDB block cache (similar to InnoDB buffer pool) is there to lower the number of reads but its content is uncompressed. Making the block cache bigger consumes memory that would normally be used by the OS file cache to cache the compressed files. But, we noticed the file cache was not fully used, there was quite a lot of unallocated memory. The culprit was the variable rocksdb_use_direct_reads which… as its name indicates, uses O_DIRECT for reads. O_DIRECT operations bypass the OS file cache. Setting this variable to OFF and lowering the block cache to about 25% of the memory made a big difference.
The read load was still rising a bit but at a much smaller pace. Instead of hours, it was days. That’s kind of expected given the workload and we were already planning for periodic manual compactions.
Change #4: rocksdb_use_direct_reads = OFF and rocksdb_block_cache_size = 48G (~25% of RAM)
Like mentioned earlier, the recorded data is short-lived, it needs to be deleted after 60 days. MyRocks has an outstanding TTL feature: you can specify how long to keep a record in MyRocks. This appears to be an extraordinarily good fit for the purpose. In order to use the TTL feature, you first need to enable it with the variable:
|
1 |
rocksdb_enable_ttl=1 |
and then, add comments to the tables you want to limit the lifespan of the records like here:
|
1 2 3 4 5 |
CREATE TABLE `pun` ( `pu` bigint(20) unsigned NOT NULL, `total` smallint(5) unsigned NOT NULL DEFAULT 0, PRIMARY KEY (`pu`) ) ENGINE=ROCKSDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT "ttl_duration=5184000;" |
The records are not actually deleted, they are just filtered out the next time there is a compaction operation. In our case, we decided to just force a manual compaction every few days using cron. This manual compaction will also help in keeping the read load low.
Change #5: rocksdb_enable_ttl = 1 and ttl_duration comments
Now that we have a well-behaving MyRocks server, how does it compare with one of its InnoDB siblings? First, let’s look at the total size of the datasets:
With MyRocks and the LZ4/Zstd column family configuration, the dataset size is less than half (44%) of the InnoDB size using page compression. Although the dataset size reduction is great, where MyRocks is really stellar is with the write bandwidth.
On two replicas, one using InnoDB and one using MyRocks, we recorded some system metrics using vmstat over a period of two hours. The recordings are about synchronous and the replicas were handling the same write and read loads. To reduce the noise, running averages over five samples have been used.
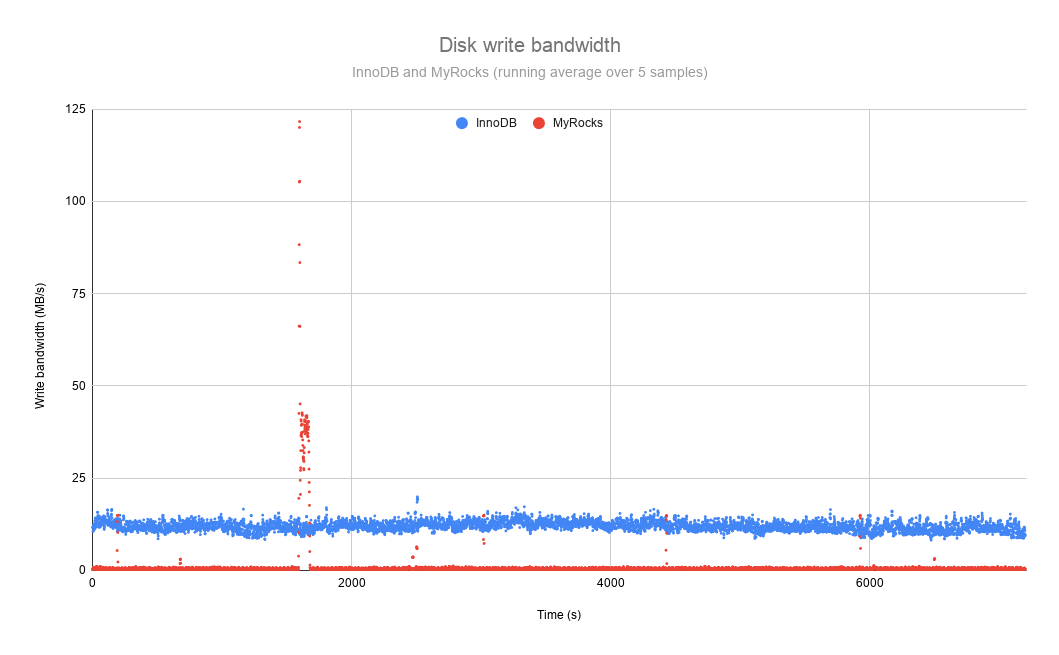
The write bandwidth of the servers is presented in the figure below. On average, MyRocks wrote to disk at a rate of less than 1 MB/s (917 KB/s to be exact) while InnoDB wrote at an average rate of almost 12 MB/s. That’s a huge difference and it explains why Facebook has invested so much in MyRocks. The lower write bandwidth increases the lifespan of the SSDs by an order of magnitude. In general, the write load is rather flat but MyRocks has a few peaks caused by compaction events, the most important one occurred around 1800s and reached nearly 125 MB/s for a short while. Unless the MyRocks server is close to saturation, those peaks are barely noticeable.
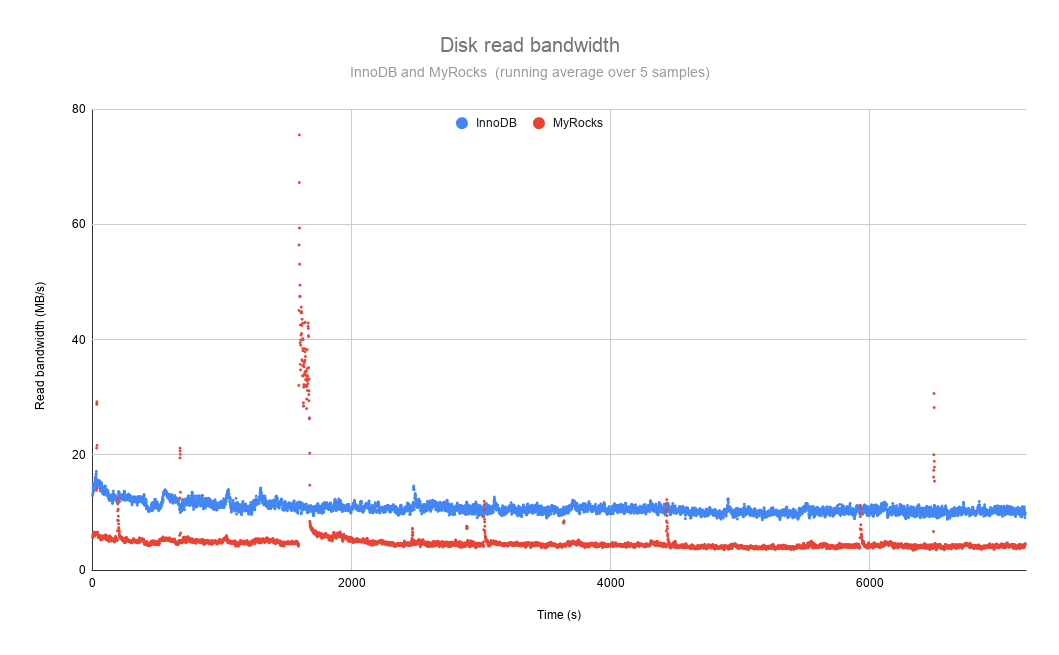
The read bandwidth, presented below, is also favorable to MyRocks, mainly because of the OS file cache and the favorable compression ratio. Also, we recorded the metrics shortly after a manual compaction, the comparison would be less favorable a day or two later. Anyhow, the average read rate of MyRocks was a little above 5 MB/s for MyRocks and 11 MB/s for InnoDB.
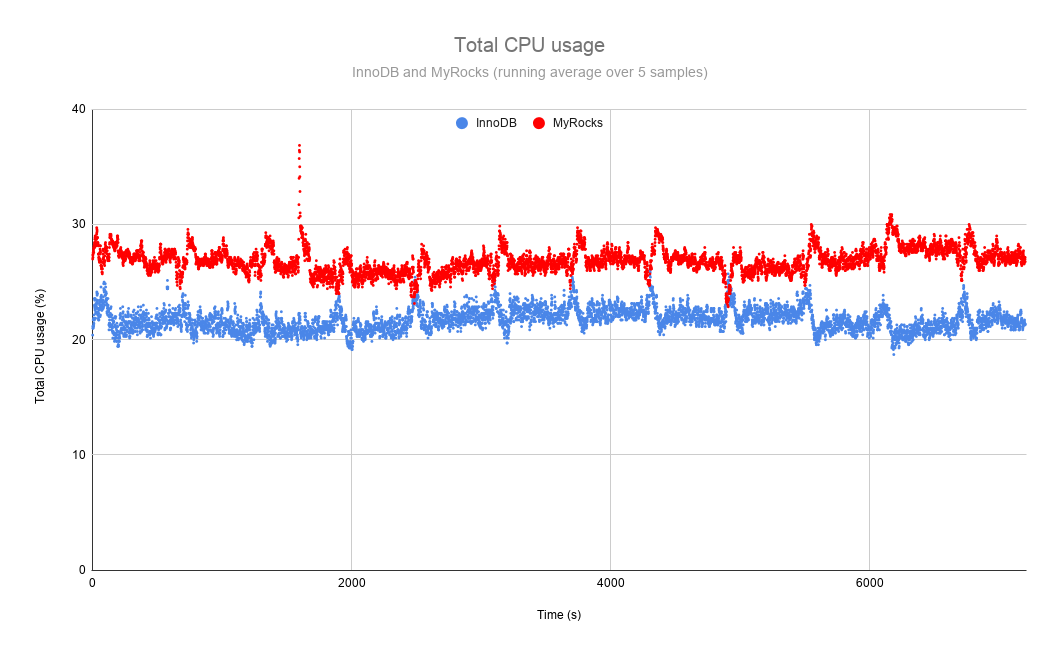
On the downside, the heavy use of data compression and the nature of LSM data processing bears a CPU cost. The CPU usage of MyRocks and InnoDB is shown in the figure below. On average, over the interval the metrics were recorded, MyRocks used almost 28% of all the CPU resources while InnoDB used only a little less than 22%. Around 6% of additional CPU usage (an increase of 27% in relative terms) appears to be a small price to pay for the benefits MyRocks provides.
In heavily loaded replicas with InnoDB, MariaDB would take several minutes to shut down, in some cases up to 20 minutes. RocksDB is much faster in this area too. In a light loaded data center, these are the startup and shutdown times for both engines:
InnoDB
RocksDB
Startup
14.248s
3.088s (4.61x faster)
Shutdown
42.585s
12.699s (3.35x faster)
After migrating the first of the production replicas, we migrated the remaining 13 over a period of three weeks. When migrating the first replica in a datacenter, ALTER TABLE commands were used to change the table engine. RocksDB bulk load mode was enabled prior to executing the ALTER commands:
|
1 2 3 |
set session rocksdb_bulk_load=1; set session rocksdb_bulk_load_size=1000000; alter table db.table engine=rocksdb COMMENT="ttl_duration=5184000"; |
After all the data tables were converted to RocksDB, so were all the InnoDB tables in the information_schema, performance_schema, and mysql databases. After that, InnoDB was disabled in my.cnf and the service restarted.
To migrate the second replica in a data center, the #rocksdb and database dirs were copied from the first replica using rsync. As data is stored in write-once .sst files, almost everything can be copied while the source server is live and processing queries. It must only be shut down for less than a minute to copy the last .sst files written.
RocksDB has now been running in production for more than two months. So far, we have encountered no issues, except for one which was our mistake. The CPU load of one of the replicas once spiked to almost 90% for many hours. After some troubleshooting, we noticed that the manual compaction job had never run on that server because of a configuration error. Most of the load was spent in reading rows from a table where 600 million were present in the .sst files but most of them (588 million) had expired. Once the compaction job ran, load returned to normal and disk space usage dropped significantly.
We have also in the meantime installed four more replicas in two new data centers, by simply copying the .sst and .frm files from the closest data center. We did an initial rsync at night with the source server running, then another one to copy the new files, and then we shut down the source server for less than a minute to do a last fast rsync.
In this post, we shared the story of migration to MyRocks along with its issues and the steps we took to resolve them. Overall, MyRocks performs much better than InnoDB for this use case. With the same hardware, e-planning can now process at least double the number of queries it was processing with InnoDB. Also, the reduction in storage space means no more SSDs will need to be bought for quite some time. The limiting factor has now become the CPU.
The TTL feature is great for e-planning, as data expiration is handled automatically by RocksDB and all cron scripts which deleted old data have been eliminated. Lastly, the ease of copying write-once SST files from one replica to another one makes installing new replicas a fast task.
We wish MariaDB would ship binaries with Zstd and LZ4, which clearly perform much better than the included algorithm Snappy.





Thank you for an interesting migration story
When I send
ALTER TABLE
mytableADD PARTITION (PARTITIONp8VALUES LESS THAN (8000000))’;from InnoDB master to MyRocks replica, I get:
[ERROR] [MY-010584] [Repl] Slave SQL for channel ”: Error ‘Got error 10 ‘Operation aborted: Failed to acquire lock due to rocksdb_max_row_locks limit’ from ROCKSDB’ on query. Default database: ‘xyz’. Query: ‘ALTER TABLE
xyz.mytableADD PARTITION (PARTITIONp8VALUES LESS THAN (8000000))’, Error_code: MY-001296[Warning] [MY-010584] [Repl] Slave: Inplace partition altering is not supported Error_code: MY-000138
1.) is there any chance to execute ALTER TABLE through replication?
2.) is there any plan to support ADD/DROP PARTITION without rebuilding the whole table?
For us, this is a show stopper. I really wanted to use MyRocks, but I can’t 🙁
Thank you, Vojtech
That’s one of the MyRocks limitation. Do you absolutely need partitions? Can you alter the partitions on all servers in bulk mode?
We’ve developed our own partition management system. Some partitions are dropped daily, some once per month etc. It works very well with InnoDB/MyISAM.
Rewriting that system to use MyRocks (without partitions) is not an option, it would not be cost effective. It’s much cheaper to buy bigger SSDs now.
I’ve already spent many hours migrating the data, learning all the settings, and have run into this problem now, when I turned the replication on. What a shame 🙂
Yves, do you think it’s possible to sponsor development of online DDL and better partition support in MyRocks?
If I understand the problem correctly, Facebook does not need online DDL, because they are using OnlineSchemaChange for all schema changes, right?
Take a look at data blocks format_version too since this can improve performance too.