
 I wanted to start this post with the words “eBPF is the hot new thing”, but I think it’s already too late to write that. Running eBPF programs in production is becoming less of a peculiarity and more of a normal way to operate. Famously, Facebook runs about 40 BPF programs on each server. There are multiple things you can do with BPF, but as a support engineer here in Percona, I’m mostly interested in the performance observability side of things. Running tools from the bcc project and writing short bpftrace programs is a great way to get insight into some particular performance problem. However, that’s still mostly not monitoring, at least not in a continuous way. Recently, I became curious to see if it’s possible to add metrics from BPF programs to Percona Monitoring and Management (PMM), and in this blog post, I’ll show that it’s surprisingly easy.
I wanted to start this post with the words “eBPF is the hot new thing”, but I think it’s already too late to write that. Running eBPF programs in production is becoming less of a peculiarity and more of a normal way to operate. Famously, Facebook runs about 40 BPF programs on each server. There are multiple things you can do with BPF, but as a support engineer here in Percona, I’m mostly interested in the performance observability side of things. Running tools from the bcc project and writing short bpftrace programs is a great way to get insight into some particular performance problem. However, that’s still mostly not monitoring, at least not in a continuous way. Recently, I became curious to see if it’s possible to add metrics from BPF programs to Percona Monitoring and Management (PMM), and in this blog post, I’ll show that it’s surprisingly easy.
This post will not cover what’s BPF or means of writing BPF programs. You can learn more by reading “Learn eBPF Tracing: Tutorial and Examples” by Brendan Gregg to understand the basics.
PMM is built on top of Prometheus, and thus the first thing that will be required is an exporter capable of converting BPF program’s output into metrics. Luckily, there’s already ebpf_exporter from Cloudflare. Next, we’ll need a reasonably modern kernel (ebpf_exporter’s readme mentions at least 4.14). It would probably be easier to use Ubuntu 20.04, which ships with the 5.4 LTS kernel, but I habitually went for CentOS, specifically version 8. On a side note, it’s possible to use the same approach for CentOS 7, but not all example BPF programs work. Even with CentOS 8, there are some issues along the way. Finally, we’ll need a BPF program. ebpf_exporter project comes with a set of examples, mimicking the aforementioned bcc tools, and I decided to go with a biolatency equivalent based on Kernel tracepoints.
I used an extremely simple environment based on two CentOS 8 VMs run with Vagrant. The Vagrantfile used includes installation of the PMM2 server and setting up a monitored node with pmm-admin. Once the VMs are up, the other steps are manual to better show the process.
There’s just one pre-requisite for ebpf_exporter, and that’s the bcc package with its own dependencies. Unfortunately, at the time of writing this blog, CentOS 8.1 has only the 0.8.0 version of bcc, a rather old one, even though CentOS 7 provides version 0.10.0. Fortunately, in the “Stream” version of the OS, you can get the 0.11.0 version. I hope that the non-rolling versions of the OS will get updated packages soon, but for now, that’s how things are.
To change the version of CentOS 8 to Stream, a single command should be run:
|
1 |
# dnf install centos-release-stream |
With the OS side of things sorted out, we can proceed to more interesting stuff.
1. We’ll need to actually install the bcc package and its dependencies.
|
1 2 3 |
# dnf install bcc # dnf info bcc | grep Version Version : 0.11.0 |
2. Once that’s done, we can test that the tools actually work. We should see PMM’s node_exporter monitoring the system.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# /usr/share/bcc/tools/opensnoop PID COMM FD ERR PATH /var/run/utmp 1474 vminfo 5 0 /usr/local/share/dbus-1/system-services 885 dbus-daemon -1 2 /usr/share/dbus-1/system-services 885 dbus-daemon 6 0 /lib/dbus-1/system-services 885 dbus-daemon -1 2 /proc/stat 6030 node_exporter 8 0 /usr/local/percona/pmm2/collectors/textfile-collector/medium-resolution 6030 node_exporter 8 0 /usr/local/percona/pmm2/collectors/textfile-collector/medium-resolution/example.prom 6030 node_exporter 8 0 /sys/class/hwmon 6030 node_exporter 8 0 /proc/stat 6030 node_exporter 8 0 /proc/loadavg |
A common issue with tools is a kernel and kernel-devel package version mismatch. Just make sure that you have a kernel-devel of the same version as your running kernel.
3. Install the ebpf_exporter. You can build it, but it’s easier to get the release version.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# wget https://github.com/cloudflare/ebpf_exporter/releases/download/v1.2.2/ebpf_exporter-1.2.2.tar.gz # tar xf ebpf_exporter-1.2.2.tar.gz # cp -ip ebpf_exporter-1.2.2/ebpf_exporter /usr/local/bin/ebpf_exporter # /usr/local/bin/ebpf_exporter --help usage: ebpf_exporter [<flag>] Flags: -h, --help Show context-sensitive help (also try --help-long and --help-man). --web.listen-address=":9435" The address to listen on for HTTP requests --config.file=config.yaml Config file path --debug Enable debug --version Show application version. |
4. We’ll also need the bio-tracepoints.yaml file from the examples. You can get it alone, but I recommend cloning the whole repo so that you can explore the other examples as well.
|
1 |
# git clone https://github.com/cloudflare/ebpf_exporter |
5. Run the exporter and test its output.
|
1 2 3 4 5 6 7 8 |
# /usr/local/bin/ebpf_exporter --config.file=ebpf_exporter/examples/bio-tracepoints.yaml 2020/06/02 12:35:42 Starting with 1 programs found in the config 2020/06/02 12:35:42 Listening on :9435 # curl -s localhost:9435/metrics | grep enabled_programs # HELP ebpf_exporter_enabled_programs The set of enabled programs # TYPE ebpf_exporter_enabled_programs gauge ebpf_exporter_enabled_programs{name="bio"} 1 |
It’s pretty easy to set up ebpf_exporter as a systemd service by modifying example files provided with node_exporter. Note that you’ll either need to run the program from root, or set up capabilities, as ebpf_exporter will need CAP_SYS_ADMIN capability.
6. Register newly-added exporter with a local pmm agent.
|
1 2 3 4 |
# pmm-admin add external --listen-port=9435 External Service added. Service ID : /service_id/28c36115-a07c-4520-aca2-9cf0586fa588 Service name: node1-external |
7. We don’t have any dashboards for the data yet, but we can check raw metrics in Prometheus. Navigate to http://pmm-url/prometheus/ to access its UI.
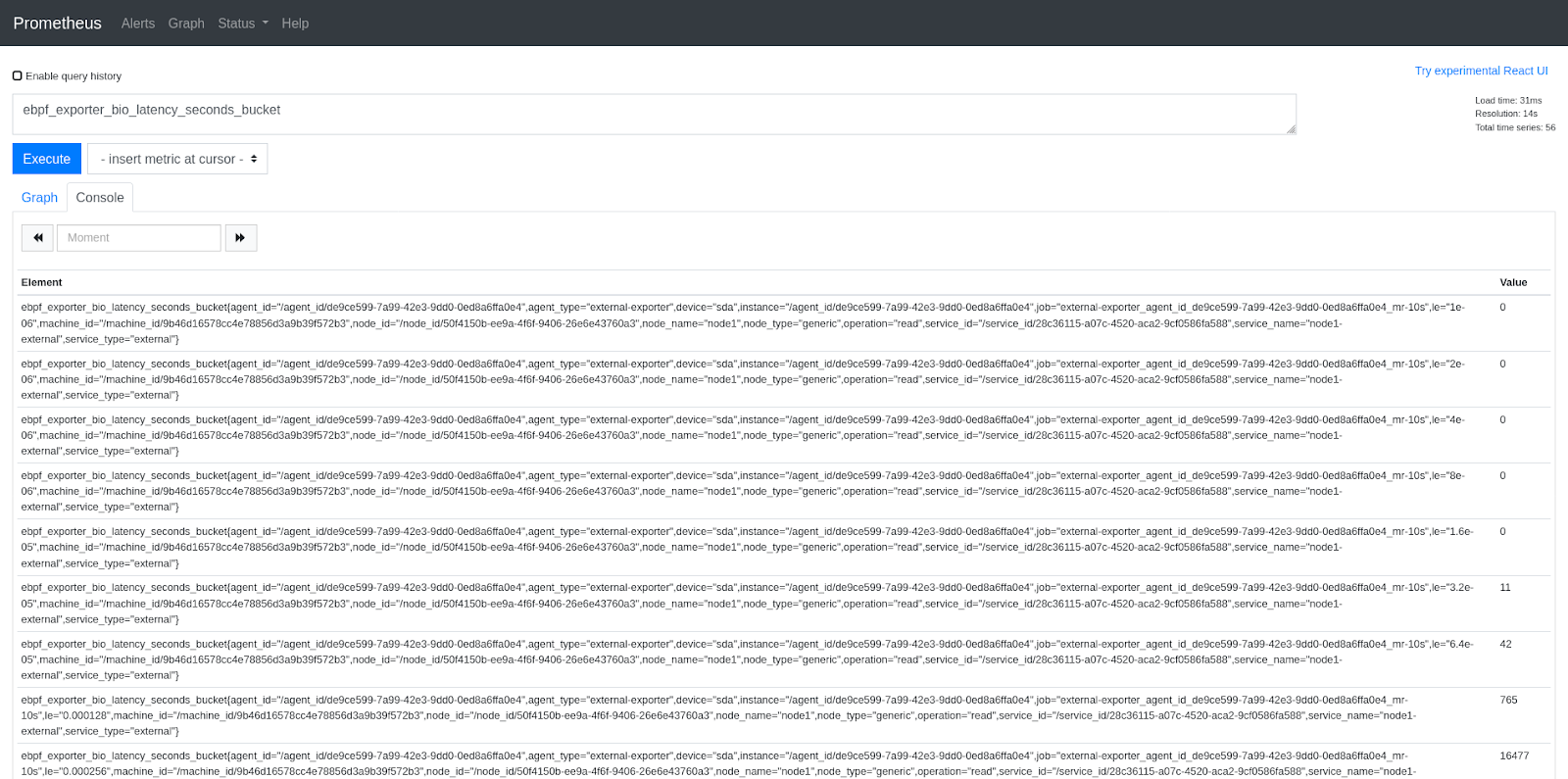
Now that we have the data, we need to represent it in a clear and convenient way. PMM’s Grafana allows you to set up custom dashboards, so that’s what we’ll need to do. I’ve prepared a very simple dashboard that has panels for BPF-based metrics alongside panels taken from the existing PMM dashboards, based on node_exporter. Dashboard’s JSON source is available alongside the Vagrantfile.
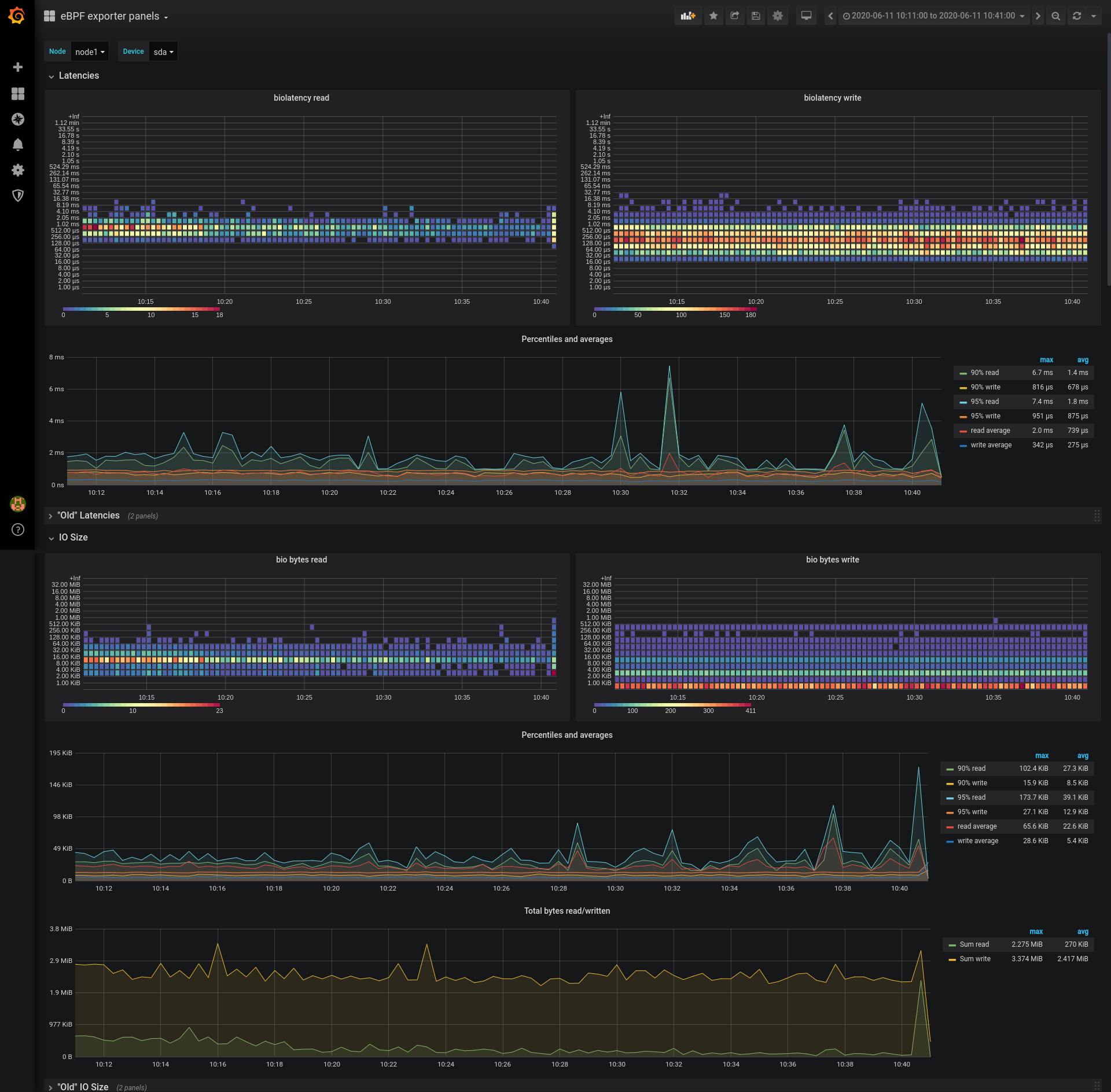
Metrics are provided by ebpf_exporter when running a bio program in the form of a histogram, which data can be used to calculate percentiles and averages, or used raw. Grafana has built-in support for histograms and heatmaps, and in this case, we’re going to be using heatmap panels. Heatmaps allow us to view the distribution over time, unlike the histogram that shows an instant representation of distribution. Looking at distribution changes over time can add more detail into otherwise “flat” data (like 95th percentile), and potentially show some otherwise hidden discontinuities. For example, on the next screenshot, you can see steady streams of 512KiB, 8kb, and 4kb write requests, on the “bio bytes write” panel. Percentile and average values are based on the same prometheus histogram data.
The screenshot below shows IO characteristics with sysbench running a very basic rw load.
No monitoring can be considered valid until it has been checked for correctness. As I’ve mentioned, the dashboard includes existing metrics, which we can treat as a source of truth. Thus, we need to test if the new metrics are showing the same load profile without skew. Inherently there will be some misalignment, because of different scraping intervals, but it shouldn’t be significant.
We can use a Flexible I/O tester program (fio for short) to generate an IO load profile, and then compare performance observations made by fio itself, node_exporter, and ebpf_exporter. This is not a benchmark, just a way to generate some load with actual performance metrics.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# fio --name=randrw --rw=randrw -direct=1 --ioengine=libaio --bs=16k --numjobs=4 --rwmixread=30 --size=1G --runtime=1200 --group_reporting --time_based randrw: (g=0): rw=randrw, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=1 ... fio-3.19 Starting 4 processes Jobs: 4 (f=4): [m(4)][100.0%][r=60.0MiB/s,w=140MiB/s][r=3842,w=8960 IOPS][eta 00m:00s] randrw: (groupid=0, jobs=4): err= 0: pid=4501: Thu Jun 25 12:35:54 2020 read: IOPS=3508, BW=54.8MiB/s (57.5MB/s)(64.2GiB/1200001msec) slat (usec): min=4, max=15528, avg=35.06, stdev=37.44 clat (nsec): min=1079, max=38747k, avg=726766.24, stdev=988979.33 lat (usec): min=38, max=38781, avg=762.07, stdev=990.54 clat percentiles (usec): | 1.00th=[ 200], 5.00th=[ 241], 10.00th=[ 273], 20.00th=[ 322], | 30.00th=[ 363], 40.00th=[ 404], 50.00th=[ 445], 60.00th=[ 498], | 70.00th=[ 578], 80.00th=[ 742], 90.00th=[ 1319], 95.00th=[ 2212], | 99.00th=[ 5538], 99.50th=[ 6849], 99.90th=[10028], 99.95th=[11207], | 99.99th=[15401] bw ( KiB/s): min=15744, max=89248, per=100.00%, avg=56193.09, stdev=2343.37, samples=9572 iops : min= 984, max= 5578, avg=3511.18, stdev=146.52, samples=9572 write: IOPS=8182, BW=128MiB/s (134MB/s)(150GiB/1200001msec); 0 zone resets slat (usec): min=4, max=24021, avg=36.07, stdev=41.72 clat (nsec): min=1493, max=26888k, avg=119918.94, stdev=200327.65 lat (usec): min=30, max=30857, avg=156.24, stdev=212.02 clat percentiles (usec): | 1.00th=[ 9], 5.00th=[ 33], 10.00th=[ 41], 20.00th=[ 48], | 30.00th=[ 53], 40.00th=[ 61], 50.00th=[ 73], 60.00th=[ 88], | 70.00th=[ 111], 80.00th=[ 147], 90.00th=[ 235], 95.00th=[ 347], | 99.00th=[ 734], 99.50th=[ 1004], 99.90th=[ 2114], 99.95th=[ 2868], | 99.99th=[ 6652] bw ( KiB/s): min=36640, max=204800, per=100.00%, avg=131068.14, stdev=5343.27, samples=9572 iops : min= 2290, max=12800, avg=8190.75, stdev=334.01, samples=9572 lat (usec) : 2=0.01%, 4=0.07%, 10=0.69%, 20=0.05%, 50=16.74% lat (usec) : 100=28.54%, 250=19.59%, 500=20.76%, 750=6.96%, 1000=2.05% lat (msec) : 2=2.75%, 4=1.15%, 10=0.62%, 20=0.03%, 50=0.01% cpu : usr=0.92%, sys=8.04%, ctx=14104000, majf=2, minf=77 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=4209757,9818981,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1 Run status group 0 (all jobs): READ: bw=54.8MiB/s (57.5MB/s), 54.8MiB/s-54.8MiB/s (57.5MB/s-57.5MB/s), io=64.2GiB (68.0GB), run=1200001-1200001msec WRITE: bw=128MiB/s (134MB/s), 128MiB/s-128MiB/s (134MB/s-134MB/s), io=150GiB (161GB), run=1200001-1200001msec Disk stats (read/write): dm-0: ios=4212124/9818871, merge=0/0, ticks=3530914/824074, in_queue=4354988, util=84.77%, aggrios=4215345/9819613, aggrmerge=2291/44598, aggrticks=2897415/758011, aggrin_queue=1170573, aggrutil=84.78% sda: ios=4215345/9819613, merge=2291/44598, ticks=2897415/758011, in_queue=1170573, util=84.78% |
Looking at what FIO showed, we should see on our panels IO load with around 134MB/s write, 57.5MB/s read. Read latency 95% of 2.2ms and write latency 95% of 0.347ms. Let’s inspect the dashboard.
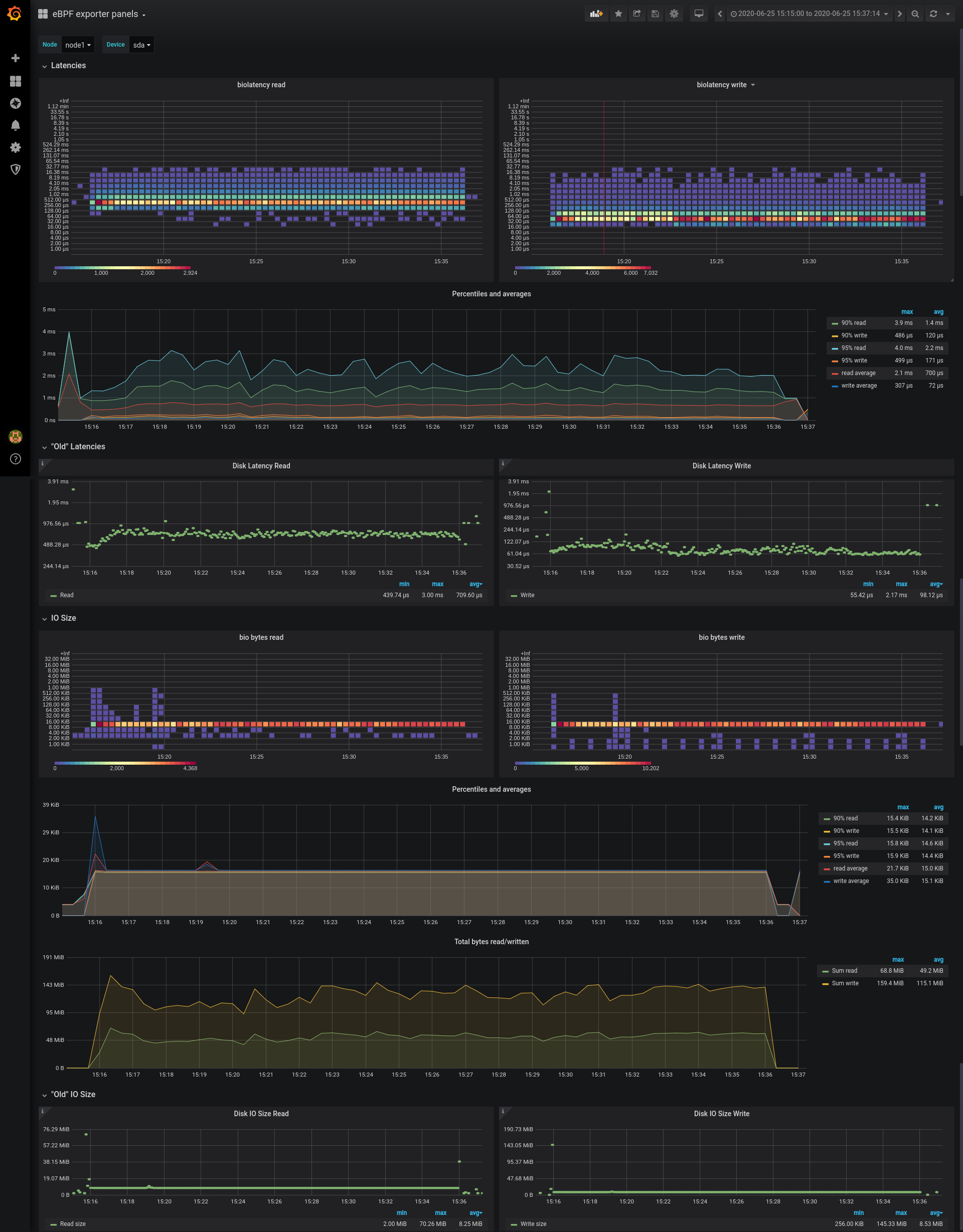
We can see that the measurements match across the board. While the tail latency of IO can be seen on the non-heatmap panel, as 95% is quite much higher than the average latency, I think that the heatmap panel gives a useful insight into the actual distribution.
This test doesn’t really show anything about IO size distribution since FIO generates a steady stream of 16kb-sized requests. However, it does show that accounting matches between eBPF-based data, and regular node_exporter data. Note that the “Disk IO Size” panel in PMM has a bug currently, so 16kb requests turned into 8mb ones. The bug for this issue is here: https://jira.percona.com/browse/PMM-6189. Even with FIO pushing the same 16kb requests, you can see there are fluctuations on the average and percentile graphs, which can be easily cross-checked with heatmap-based panels to see what kind of IO load changed the profile.
This is not an in-depth blog about writing BPF programs or making sense of their output. However, I believe that it’s now simpler than ever to get more insight into your system’s performance using “advanced tools”, and I tried to show that simplicity with off-the-shelf tools. For now, the main barrier seems to be a prevalence of legacy kernels and possible difficulties obtaining fresher packages. Performance overhead is also a concern, but in most situations, the added value of more insight outweighs the performance hit. In the future, I hope, we’ll see more BPF programs used routinely for constant monitoring.
Correctly understanding the true cause of database performance problems allows for a quick and efficient resolution – yet enterprises often lack this crucial information. Without it, your solution could require more time and resources than necessary, or inefficiently address the issue. And contrary to popular belief, the problem is not always the database itself!




