
This blog was originally published in June 2020 and was updated in March 2025.
One of the most common support tickets we get at Percona is the infamous “database is running slower” ticket. While this can be caused by a multitude of factors, it is more often than not caused by a bad or slow MySQL query. While everyone always hopes to recover through some quick config tuning, the real fix is to identify and fix the problem query. Sure, we can generally alleviate some pain by throwing more resources at the server. But this is almost always a short-term band-aid and not the proper fix.
So how do we find the queries causing problems and fix them? If you have Percona Monitoring and Management (PMM) installed, the identification process is swift. With the Query Analytics enabled (QAN) in PMM, you can simply look at the table to identify the top query:
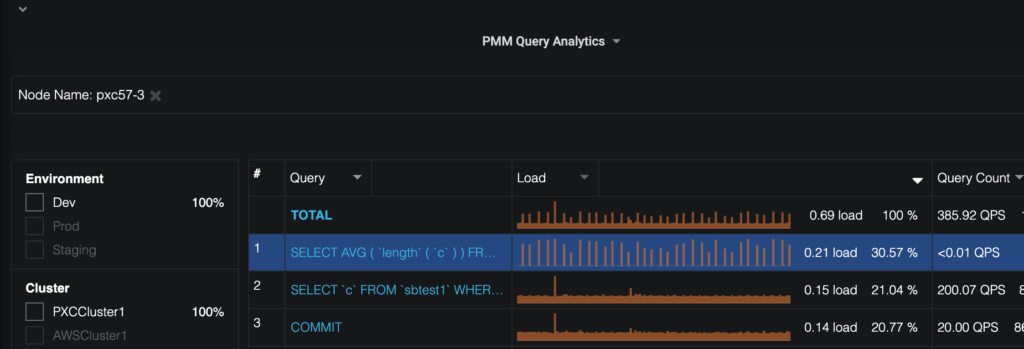
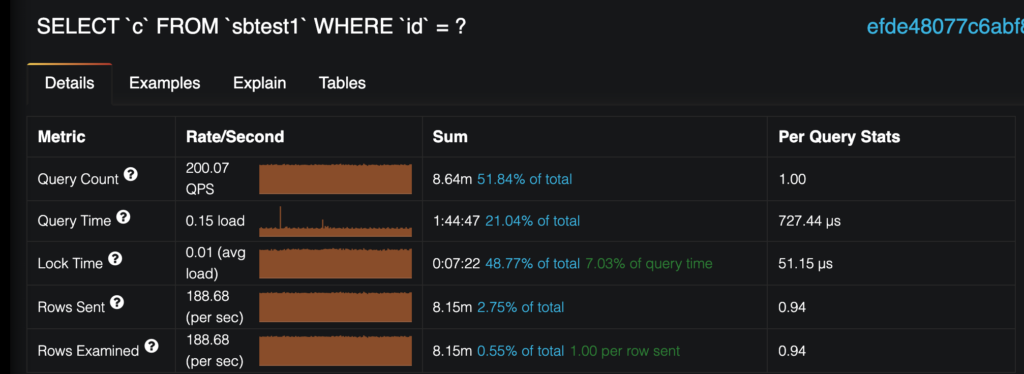
When you click on the query in the table, you should see some statistics about that query and also (in most cases), an example:
View a Demo of Percona Monitoring and Management
Now, let’s assume that you don’t have PMM installed yet (I’m sure that is being worked on as you read this). To find the problem queries, you’ll need to do some manual collection and processing that PMM does for you. The following is the best process for collecting and aggregating the top queries:
Note – you can also use the performance schema to identify queries, but setting that up is outside the scope of this post. Here is a good reference on how to use P_S to find suboptimal queries.
When looking for bad queries, one of the top indicators is a large discrepancy between rows_examined and rows_sent. In cases of suboptimal queries, the rows examined will be very large compared with a small number of rows sent.
Once you have identified your query, it is time to start the optimization process. The odds are that the queries at the top of your list (either in PMM or the digest report) lack indices. Indexes allow the optimizer to target the rows you need rather than scanning everything and discarding non-matching values. Let’s take the following sample query as an example:
|
1 2 3 4 |
SELECT * FROM user WHERE username = "admin1" ORDER BY last_login DESC; |
This looks like a straightforward query that should be pretty simple. However, it is showing up as a resource hog and is bogging down the server. Here is how it showed up in the pt-query-digest output:
|
1 2 3 4 5 |
# Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ============= ===== ====== ===== =========== # 1 0xA873BB85EEF9B3B9 0.4011 98.7% 2 0.2005 0.40 SELECT user # MISC 0xMISC 0.0053 1.3% 7 0.0008 0.0 <7 ITEMS> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# Query 1: 0.18 QPS, 0.04x concurrency, ID 0xA873BB85EEF9B3B9 at byte 3391 # This item is included in the report because it matches --limit. # Scores: V/M = 0.40 # Time range: 2018-08-30T21:38:38 to 2018-08-30T21:38:49 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 22 2 # Exec time 98 401ms 54us 401ms 201ms 401ms 284ms 201ms # Lock time 21 305us 0 305us 152us 305us 215us 152us # Rows sent 6 1 0 1 0.50 1 0.71 0.50 # Rows examine 99 624.94k 0 624.94k 312.47k 624.94k 441.90k 312.47k # Rows affecte 0 0 0 0 0 0 0 0 # Bytes sent 37 449 33 416 224.50 416 270.82 224.50 # Query size 47 142 71 71 71 71 0 71 # String: # Databases plive_2017 # Hosts localhost # Last errno 0 # Users root # Query_time distribution # 1us # 10us ################################################################ # 100us # 1ms # 10ms # 100ms ################################################################ # 1s # 10s+ # Tables # SHOW TABLE STATUS FROM `plive_2017` LIKE 'user'G # SHOW CREATE TABLE `plive_2017`.`user`G # EXPLAIN /*!50100 PARTITIONS*/ SELECT * FROM user WHERE username = "admin1" ORDER BY last_login DESCG |
We can see right away the high number of rows examined vs. the rows sent, as highlighted above. So now that we’ve identified the problem query let’s start optimizing it. Step 1 in optimizing the query would be to run an EXPLAIN plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> EXPLAIN SELECT * FROM user WHERE username = "admin1" ORDER BY last_login DESCG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 635310 filtered: 10.00 Extra: Using where; Using filesort 1 row in set, 1 warning (0.00 sec) |
The EXPLAIN output is the first clue that this query is not properly indexed. The type: ALL indicates that the entire table is being scanned to find a single record. In many cases, this will lead to I/O pressure on the system if your dataset exceeds memory. The Using filesort indicates that once it goes through the entire table to find your rows, it has to then sort them (a common symptom of CPU spikes).

One thing that is critical to understand is that query tuning is an iterative process. You won’t always get it right the first time and data access patterns may change over time. In terms of optimization, the first thing we want to do is get this query using an index and not using a full scan. For this, we want to look at the WHERE clause: where username = “admin1”.
With this column theoretically being selective, an index on username would be a good start. Let’s add the index and re-run the query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> ALTER TABLE user ADD INDEX idx_name (username); Query OK, 0 rows affected (6.94 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> EXPLAIN SELECT * FROM user WHERE username = "admin1" ORDER BY last_login DESCG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user partitions: NULL type: ref possible_keys: idx_name key: idx_name key_len: 131 ref: const rows: 1 filtered: 100.00 Extra: Using index condition; Using filesort 1 row in set, 1 warning (0.01 sec) |
So we are halfway there! The type: ref indicates we are now using an index, and you can see the rows dropped from 635k down to 1. This example isn’t the best as this finds one row, but the next thing we want to address is the filesort. For this, we’ll need to change our username index to be a composite index (multiple columns). The rule of thumb for a composite index is to work your way from the most selective to the least selective columns, and then if you need sorting, keep that as the last field. Given that premise, let’s modify the index we just added to include the last_login field:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> ALTER TABLE user DROP INDEX idx_name, ADD INDEX idx_name_login (username, last_login); Query OK, 0 rows affected (7.88 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> EXPLAIN SELECT * FROM user WHERE username = "admin1" ORDER BY last_login DESCG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user partitions: NULL type: ref possible_keys: idx_name_login key: idx_name_login key_len: 131 ref: const rows: 1 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) |
And there we have it! Even if this query scanned more than one row, it would read them in sorted order, so the extra CPU needed for the sorting is eliminated. To show this, let’s do this same index on a non-unique column (I left email as non-unique for this demo):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
+----------+ | count(1) | +----------+ | 64 | +----------+ 1 row in set (0.23 sec) mysql> ALTER TABLE user ADD INDEX idx_email (email, last_login); Query OK, 0 rows affected (8.08 sec) Records: 0 Duplicates: 0 Warnings: 0 *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user partitions: NULL type: ref possible_keys: idx_email key: idx_email key_len: 131 ref: const rows: 64 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) |
Ensure your databases are performing their best — today and tomorrow — with proactive database optimization and query tuning. Book a database assessment
While query optimization can seem daunting, using a process can make it much easier to achieve. Naturally, optimizing complex queries isn’t trivial like the above example, but is definitely possible when broken down. If you’re struggling to find and tune slow queries in your database, Percona Monitoring and Management (PMM) can help! PMM is an open source database observability, monitoring, and management tool for use with MySQL, PostgreSQL, MongoDB, and the servers on which they run. PMM’s Query Analytics tool helps you quickly locate costly and slow-running queries so you can quickly address bottlenecks impacting performance. And remember that Percona engineers are always available to help you when you get stuck! Happy optimizing!
View a Demo of Percona Monitoring and Management
Performance Tuning eBook for MySQL
In MySQL, a query is considered “slow” if it takes longer than the configured “long_query_time” threshold to execute. This threshold can vary depending on the application’s requirements and the database environment. MySQL’s slow query log is a feature that helps identify these queries by logging any query that exceeds this execution time limit, allowing for further analysis and optimization.
To improve query speed in MySQL, you can employ various techniques such as indexing your tables properly, optimizing your queries with appropriate JOINs and WHERE clauses, denormalizing data when necessary, and ensuring your hardware resources (CPU, RAM, and disk I/O) are sufficient for your workload. Additionally, monitoring and tuning MySQL configuration parameters can often yield performance gains.
Several factors can contribute to slow query performance in MySQL, including lack of proper indexing, inefficient query patterns (such as full table scans), resource contention (CPU, memory, or disk I/O bottlenecks), poorly designed schemas, locking issues, and suboptimal MySQL configuration settings. Additionally, high concurrency and high volumes of data can also impact query performance if not properly managed.
Resources
RELATED POSTS




