
 A couple of weeks ago, one of our customers reached us asking about the WARNING messages in their MySQL error log. After a while, there were a few more requests from some other customers asking whether to worry about these messages or not. In this post, I am going to write about the condition at which this WARNING message is written into the log and will explain some of the fundamentals behind the scene.
A couple of weeks ago, one of our customers reached us asking about the WARNING messages in their MySQL error log. After a while, there were a few more requests from some other customers asking whether to worry about these messages or not. In this post, I am going to write about the condition at which this WARNING message is written into the log and will explain some of the fundamentals behind the scene.
Look at the warningmber message which appears in the MySQL error log. It says it’s difficult to find a free block in the buffer pool and searched through the pool in a loop for 336 times. This is something weird to imagine; why would it have to go in a loop so many times? Let’s try to understand this.
[Warning] InnoDB: Difficult to find free blocks in the buffer pool (336 search iterations)! 0 failed attempts to flush a page! Consider increasing the buffer pool size. It is also possible that in your Unix version fsync is very slow, or completely frozen inside the OS kernel. Then upgrading to a newer version of your operating system may help. Look at the number of fsyncs in diagnostic info below. Pending flushes (fsync) log: 0; buffer pool: 0. 1621989850 OS file reads, 1914021664 OS file writes, 110701569 OS fsyncs. Starting InnoDB Monitor to print further diagnostics to the standard output.
2019-10-26T15:02:03.962059Z 4520929 [Warning] InnoDB: Difficult to find free blocks in the buffer pool (337 search iterations)! 0 failed attempts to flush a page! Consider increasing the buffer pool size. It is also possible that in your Unix version fsync is very slow, or completely frozen inside the OS kernel. Then upgrading to a newer version of your operating system may help. Look at the number of fsyncs in diagnostic info below. Pending flushes (fsync) log: 0; buffer pool: 0. 1621989850 OS file reads, 1914021664 OS file writes, 110701569 OS fsyncs. Starting InnoDB Monitor to print further diagnostics to the standard output.
In simple terms, these messages appear when a thread inside InnoDB continuously looks out for a free block but cannot grab one from the buffer pool. In reality, it’s not that simple, and there were some things that happened before it, as knowing about the building blocks of the buffer pool would make it easy to understand this story. The buffer pool is mainly comprised of three lists:
As you know, every query is handled by a thread inside InnoDB. If the required page is not available in the buffer pool, it has to be fetched from the disk and placed inside it, for which it needs a free block allocated from the Free list. Remember that a free block can only be allocated from the free list. So a thread that needs a free block goes through below iterations:
I have simplified the above steps a bit more than it is, to make it easy to understand, and that’s not the exact way it happens – but something similar, for sure. At any point, if the block is moved to a free list, it can be consumed by any other thread, which can make the current thread fail to grab the free block. Then it continues to go through the loop of actions with 10 ms sleep every time.
When a thread exceeds more than 20 iterations, it writes this WARNING message to the log. Below is the code block from the latest release that points to the exact situation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
if (n_iterations > 20 && srv_buf_pool_old_size == srv_buf_pool_size) { <strong><======= Here it is</strong> ib::warn(ER_IB_MSG_134) << "Difficult to find free blocks in the buffer pool" " (" << n_iterations << " search iterations)! " << flush_failures << " failed attempts to" " flush a page! Consider increasing the buffer pool" " size. It is also possible that in your Unix version" " fsync is very slow, or completely frozen inside" " the OS kernel. Then upgrading to a newer version" " of your operating system may help. Look at the" " number of fsyncs in diagnostic info below." " Pending flushes (fsync) log: " |
This situation can be a consequence of different backgrounds, and the below list can be validated to find the exact reason. Though it has saturated the IO subsystem many times, it cannot be the same with every instance and workload.
Monitoring tools like Percona Monitoring and Management (PMM) would be very useful to inspect the above aspects. In the below example screenshot captured from my local PMM GUI, you can see that the free pages inside the buffer pool are almost empty at different points in time which is one of the causes behind this situation as explained above. This data is available from the InnoDB Buffer Pool Pages panel of MySQL InnoDB Metrics dashboards.
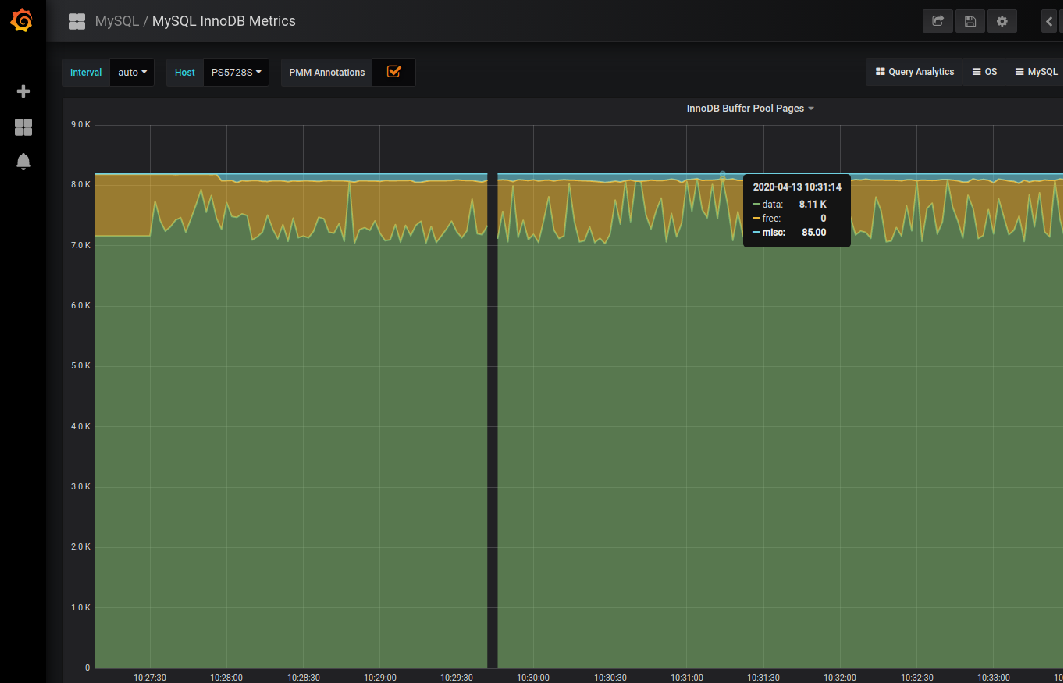
Similarly, there are other panels like InnoDB Buffer Pool Requests to see the disk reads which is another metric to say if the current buffer pool is sufficient or not. One can also see the IO wait pattern by looking at the CPU Usage panel of OS/System Overview dashboards. Below are some of the most common action plans to avoid this situation in an instance.
Hope this post helps review these cases faster and produces more accurate recommendations according to the cause of the problem.




