
In this two-part blog series, I wanted to cover some failover scenarios with Group Replication. In part one, I will discuss an interesting behavior and performance degradation I discovered while writing these posts. In part two, I will show several failover scenarios and demonstrate how Group Replication handles each situation.
The test environment is very basic, a three-node Group Replication (mysql1,mysql2,myslq3) on MySQL 8.0.19 with default settings. mysql2 is the Primary node.
In this scenario, I was testing a partial network failure when a node gets separated from the primary, but other nodes still can see it.
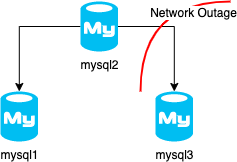
You would think mysql3 is going to lose quorum and exit the cluster, but no. Inside the cluster, all the nodes are in constant communication with each other, not just the primary talking with mysql3 but also mysql1 is talking to mysql3.
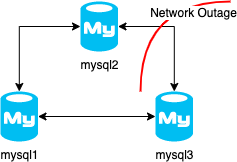
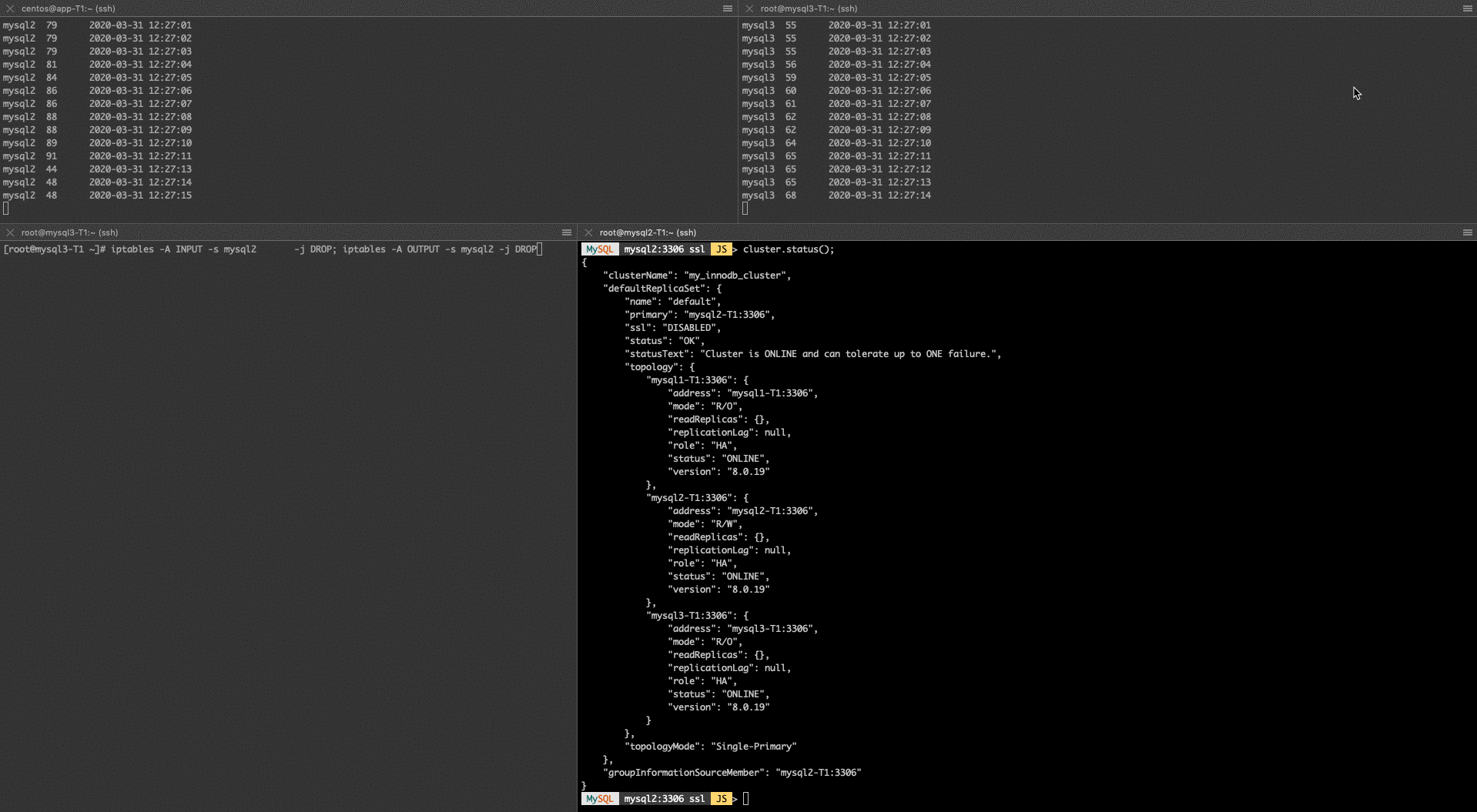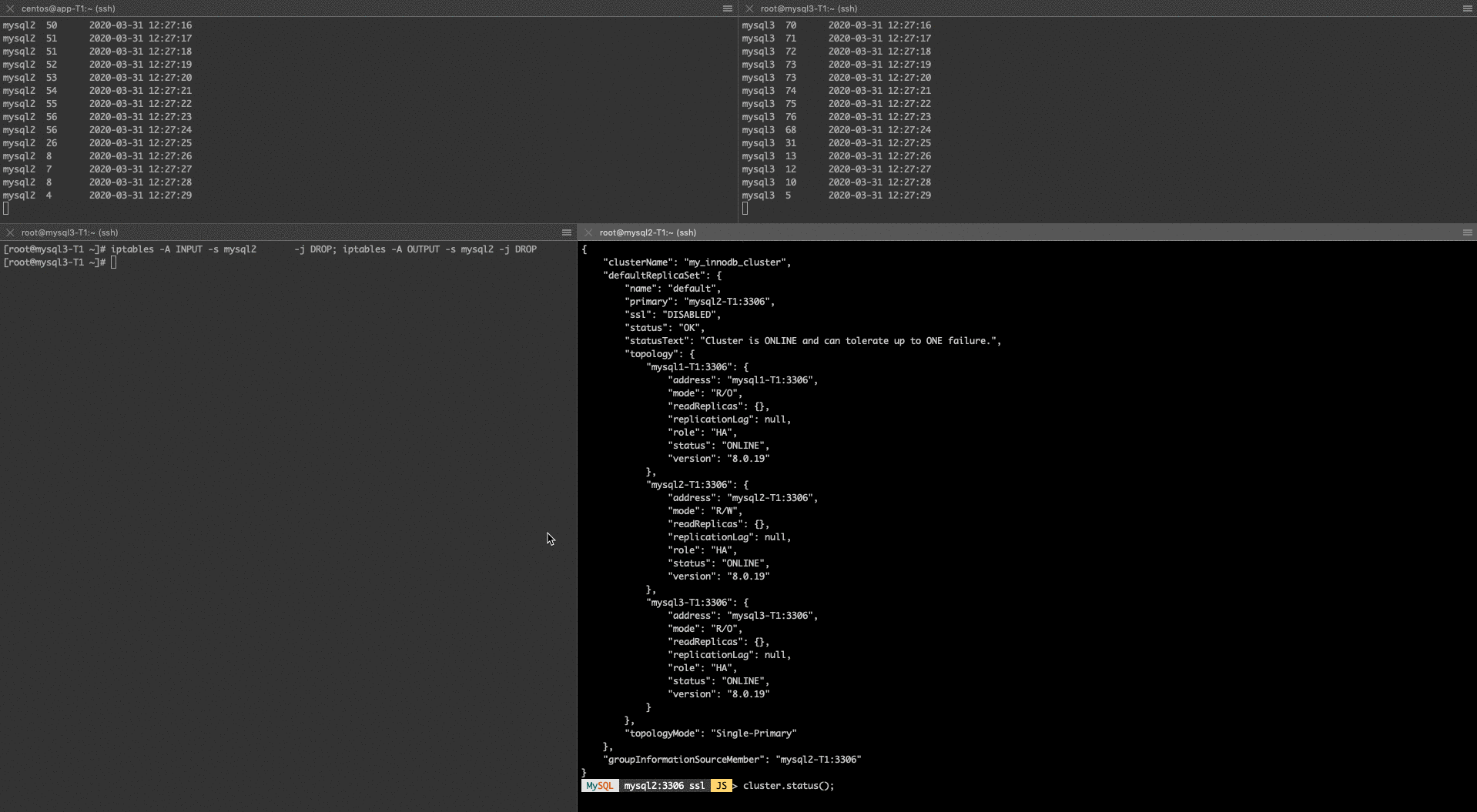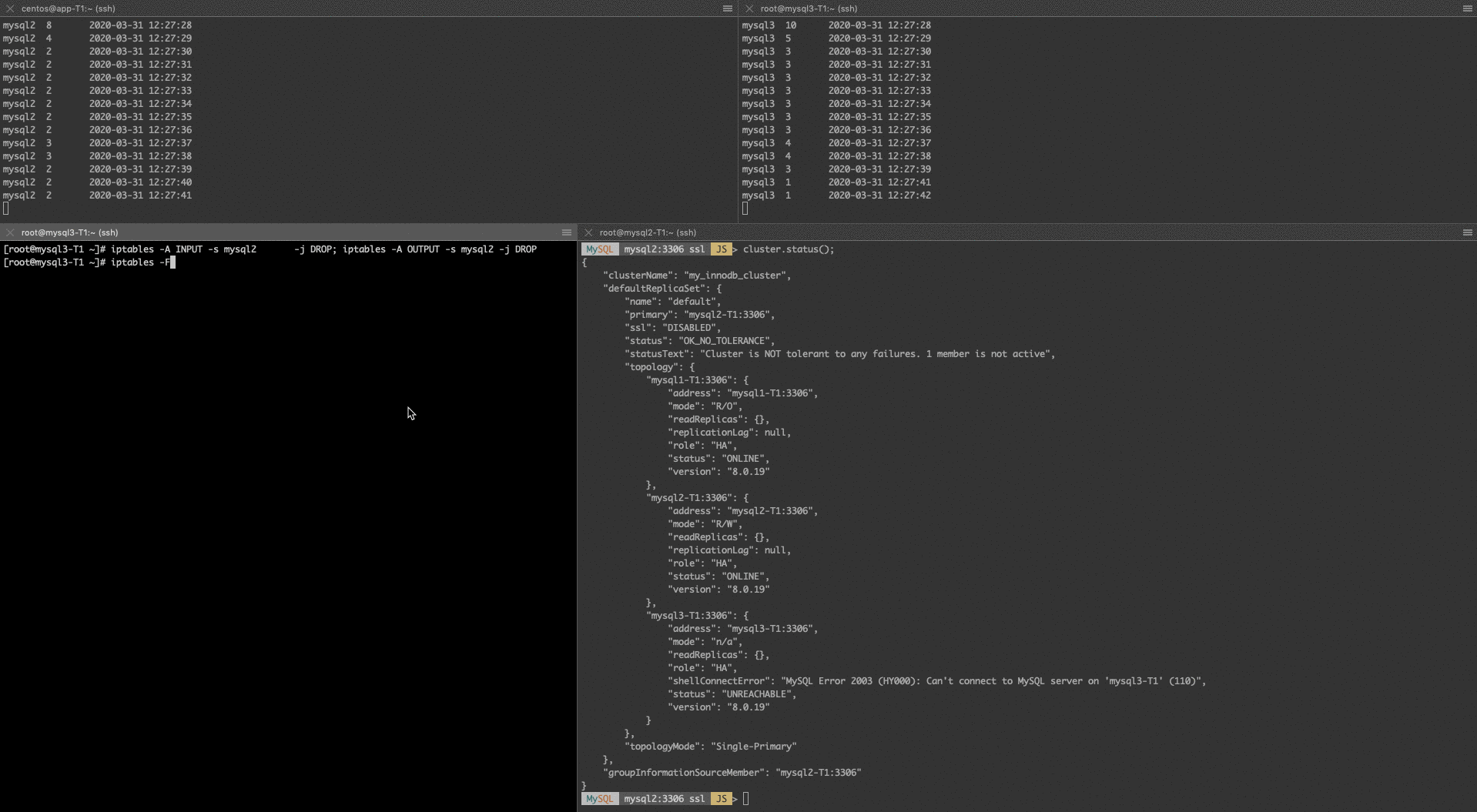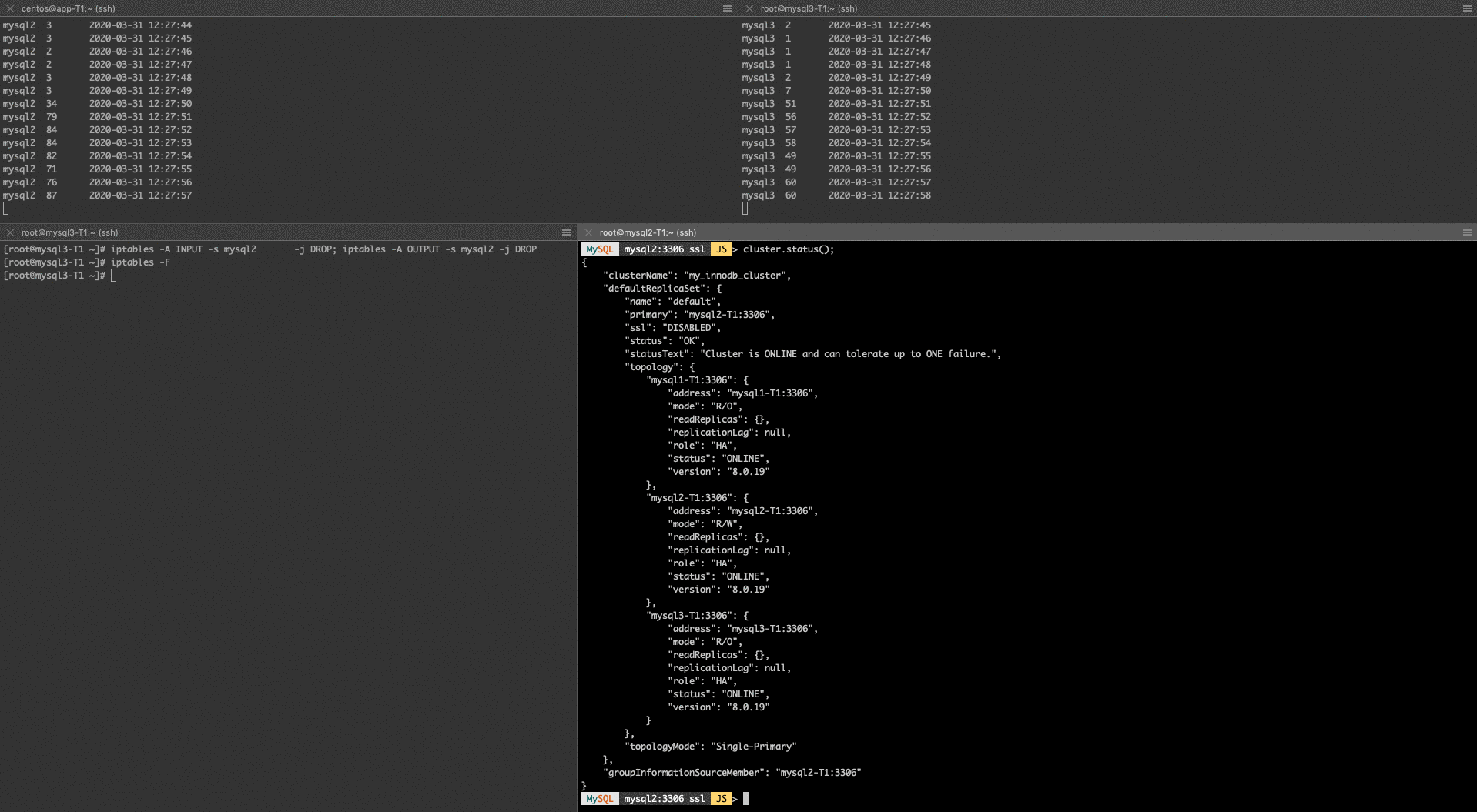
If we ask the cluster status from the primary, it will say mysql3 is unreachable.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
MySQL mysql2:3306 ssl JS > cluster.status(); { "clusterName": "my_innodb_cluster", "defaultReplicaSet": { "name": "default", "primary": "mysql2-T1:3306", "ssl": "DISABLED", "status": "OK_NO_TOLERANCE", "statusText": "Cluster is NOT tolerant to any failures. 1 member is not active", "topology": { "mysql1-T1:3306": { "address": "mysql1-T1:3306", "mode": "R/O", "readReplicas": {}, "replicationLag": null, "role": "HA", "status": "ONLINE", "version": "8.0.19" }, "mysql2-T1:3306": { "address": "mysql2-T1:3306", "mode": "R/W", "readReplicas": {}, "replicationLag": null, "role": "HA", "status": "ONLINE", "version": "8.0.19" }, "mysql3-T1:3306": { "address": "mysql3-T1:3306", "mode": "n/a", "readReplicas": {}, "role": "HA", "shellConnectError": "MySQL Error 2003 (HY000): Can't connect to MySQL server on 'mysql3-T1' (110)", "status": "UNREACHABLE", "version": "8.0.19" } }, "topologyMode": "Single-Primary" }, "groupInformationSourceMember": "mysql2-T1:3306" |
But if we ask the status from mysql1 it will say everything is fine:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
MySQL mysql1:3306 ssl JS > cluster.status(); { "clusterName": "my_innodb_cluster", "defaultReplicaSet": { "name": "default", "primary": "mysql2-T1:3306", "ssl": "DISABLED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": { "mysql1-T1:3306": { "address": "mysql1-T1:3306", "mode": "R/O", "readReplicas": {}, "replicationLag": null, "role": "HA", "status": "ONLINE", "version": "8.0.19" }, "mysql2-T1:3306": { "address": "mysql2-T1:3306", "mode": "R/W", "readReplicas": {}, "replicationLag": null, "role": "HA", "status": "ONLINE", "version": "8.0.19" }, "mysql3-T1:3306": { "address": "mysql3-T1:3306", "mode": "R/O", "readReplicas": {}, "replicationLag": null, "role": "HA", "status": "ONLINE", "version": "8.0.19" } }, "topologyMode": "Single-Primary" }, "groupInformationSourceMember": "mysql2-T1:3306" |
For me, this is a bit confusing, as I am asking two members from the same cluster and reporting different states, I would love to see the same cluster status on all the nodes.
Can I still write the cluster? Will mysql3 get new changes as well? To answer these questions, let’s do some simple tests.
I have created a simple table:
|
1 2 3 4 5 6 7 |
CREATE TABLE `lab` ( `id` int NOT NULL AUTO_INCREMENT, `hostname` varchar(20) DEFAULT NULL, `created_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `idx_created` (`created_at`) ) ENGINE=InnoDB |
Now I have started the following loop on the primary:
|
1 |
while true;do mysql -usbtest -pxxxxx -P3306 -h127.0.0.1 -e "INSERT INTO sysbench.lab (hostname) VALUES ( @@hostname)"; done 2>/dev/null |
It is going to simple insert the hostname as many times as it can. I leave this running in the background.
I opened two ssh connections, one to mysql2(primary) and one to mysql3 and ran following loop:
|
1 |
while true;do mysql -BN -usbtest -pxxxxx -P3306 -hmysql2 -e "select 'mysql2',count(*),now() from sysbench.lab where created_at BETWEEN now() - INTERVAL 1 second AND now()"; sleep 1; done 2>/dev/null |
It is going to print how many lines were inserted on mysql2 and mysql3 per every second.
I cut the network between mysql2 and mysql3 by using iptables:
|
1 |
mysql3# iptables -A INPUT -s mysql2 -j DROP; iptables -A OUTPUT -s mysql2 -j DROP |
After this, mysql3 is still getting the changes, but how? It is not able to connect to mysql2. But it is still able to connect to mysql1 which is going to act as a kind of relay node between mysql2 and mysql3. This sounds great because even in case of a partial network outage, we still could use mysql3 because it gets the changes. However, this behavior is not documented anywhere. So I do not know how it works under the hood. I opened a bug report to update the documentation.
However, I also noticed there is a serious performance degradation because of this. When all the nodes were connected, I was able to insert 60-80 rows per second. As soon I cut the network, that number went down to 2-5 inserts per second, which is 80-90% degradations. That could severely impact the performance of any application, which means with Group Replication even partial network outage, or a wrongly implemented Iptables rule, etc.. could cause production problems.
Because it is poorly documented, I can not be sure why this is happening. In Group Replication, it is enough for the majority to acknowledge the transactions, so in theory, mysql2 and mysql1 would be enough so we can not explain this degradation with network latency because of the extra hop.
I have also opened a bug report for this, which is already confirmed.
Percona XtraDB Cluster is based on Galera, which is another clustering solution for MySQL. In Galera, this behavior is well known; a node can act as a relay node even between data centers. I repeated the same tests on a three-node PXC8 cluster as well. When I cut the network between the primary node (where I write) and mysql3 there was a 3-second gap until the cluster recalculated the cluster view and re-routed the traffic, after that everything went back to normal there was no measurable performance impact, mysql3 was getting all the changes trough mysql1:
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql3 62 2020-03-31 14:13:12 mysql3 65 2020-03-31 14:13:13 mysql3 67 2020-03-31 14:13:14 mysql3 69 2020-03-31 14:13:15 mysql3 47 2020-03-31 14:13:16 mysql3 0 2020-03-31 14:13:17 mysql3 0 2020-03-31 14:13:18 mysql3 0 2020-03-31 14:13:19 mysql3 41 2020-03-31 14:13:20 mysql3 71 2020-03-31 14:13:21 mysql3 72 2020-03-31 14:13:22 |
Also, in PXC8, all the nodes reporting the same cluster status even mysql2.
Because Group Replication and Galera implementation and approach are different, you can see the impact on performance is also different. Galera has a better tolerance for network issues than Group Replication. I am going to publish a much longer blog post, which will discuss other failover/disaster scenarios as well.





‘not just the primary talking with mysql3 but also mysql2 is talking to mysql3’
mysql2 is the primary ..
It may be ‘not just the primary talking with mysql3 but also mysql1 is talking to mysql3’?
Thanks, you are correct.
hi,Tibor Korocz
I repeated the same tests on a three nodes Group Replication on MySQL Community Server 8.0.19 。When I set the iptables,
# mysql3 iptables -A INPUT -s mysql1 -j DROP; iptables -A OUTPUT -s mysql1 -j DROP
first the primary node print out
mysql1 113 2020-04-22 10:46:55
mysql1 94 2020-04-22 10:46:56
mysql1 33 2020-04-22 10:46:57
mysql1 11 2020-04-22 10:46:58
mysql1 14 2020-04-22 10:46:59
mysql1 13 2020-04-22 10:47:00
mysql1 9 2020-04-22 10:47:01
mysql1 4 2020-04-22 10:47:02
mysql1 26 2020-04-22 10:47:03
mysql1 56 2020-04-22 10:47:04
mysql1 108 2020-04-22 10:47:05
the mysql3 node print out
mysql3 67 2020-04-22 10:46:54
mysql3 69 2020-04-22 10:46:55
mysql3 68 2020-04-22 10:46:56
mysql3 28 2020-04-22 10:46:57
mysql3 7 2020-04-22 10:46:58
mysql3 9 2020-04-22 10:46:59
mysql3 10 2020-04-22 10:47:00
mysql3 5 2020-04-22 10:47:01
mysql3 2 2020-04-22 10:47:02
mysql3 1 2020-04-22 10:47:03
mysql3 0 2020-04-22 10:47:04
mysql3 0 2020-04-22 10:47:05
mysql3 0 2020-04-22 10:47:06
mysql3 0 2020-04-22 10:47:07
I got a different result ..
and in mytest ,the same cluster status on all the nodes.
MySQL kh-oms4-sit-innodbcluster-db02:3306 ssl JS > cluster.status()
{
"clusterName": "oms4",
"defaultReplicaSet": {
"name": "default",
"primary": "kh-oms4-sit-innodbcluster-db01:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"kh-oms4-sit-innodbcluster-db01:3306": {
"address": "kh-oms4-sit-innodbcluster-db01:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.19"
},
"kh-oms4-sit-innodbcluster-db02:3306": {
"address": "kh-oms4-sit-innodbcluster-db02:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.19"
},
"kh-oms4-sit-innodbcluster-db03:3306": {
"address": "kh-oms4-sit-innodbcluster-db03:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "(MISSING)"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "kh-oms4-sit-innodbcluster-db01:3306"
}
emmm…I can’t understand why i got a different result..
Hi,
Can your reader nodes see each other? In the iptables command I suppose you changed the hostnames? This behaviour is also verified from Oracle: https://bugs.mysql.com/bug.php?id=99133
Hi,the iptables on each node
mysql1
[root@kh-oms4-sit-innodbcluster-db01 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
mysql2
[root@kh-oms4-sit-innodbcluster-db02 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
mysql3
[root@kh-oms4-sit-innodbcluster-db03 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP all -- kh-oms4-sit-innodbcluster-db01 anywhere
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DROP all -- kh-oms4-sit-innodbcluster-db01 anywhere
I set the iptables use this command
iptables -A INPUT -s 10.101.190.112 -j DROP; iptables -A OUTPUT -s 10.101.190.112 -j DROP
In the iptables command I suppose you changed the hostnames .. this mean i should
iptables -A INPUT -s kh-oms4-sit-innodbcluster-db01 -j DROP; iptables -A OUTPUT -s kh-oms4-sit-innodbcluster-db01 -j DROP
?
Because the oracle confirm this is a bug , I got a different result , I am confused…