
 In a high concurrency world, where more and more users->connections->threads are used, contention is a given. But how do we identify the contention point easily?
In a high concurrency world, where more and more users->connections->threads are used, contention is a given. But how do we identify the contention point easily?
Different approaches had been discussed previously, like the one using Perf and Flame graphs to track down the function taking way more time than expected. That method is great but how can we do it with what one normally has, like the MySQL Client? Enter: the SEMAPHORES section from the SHOW ENGINE INNODB STATUS command output.
The SEMAPHORES section displays all the metrics related to InnoDB mechanics on waits. This section is your best friend if you have a high concurrency workload. In short, it contains 2 kinds of data: Event counters and a list of current waits.
That is a section that should be empty unless your MySQL has a high concurrency that causes InnoDB to start using the waiting mechanism. If you don’t see lines with the form “”– Thread <num> was waited…” then you are good. No contention.
Now, what does it look like? It could be like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
---------- SEMAPHORES ---------- OS WAIT ARRAY INFO: reservation count 1744351 --Thread 139964395677440 has waited at btr0cur.cc line 5889 for 0 seconds the semaphore: S-lock on RW-latch at 0x7f4c3d73c150 created in file buf0buf.cc line 1433 a writer (thread id 139964175062784) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0sea.cc line 1121 Last time write locked in file /mnt/workspace/percona-server-5.7-redhat-binary-rocks-new/label_exp/min-centos-7-x64/test/rpmbuild/BUILD/percona-server-5.7.28-31/percona-server-5.7.28-31/storage/innobase/btr/btr0sea.cc line 1121 OS WAIT ARRAY INFO: signal count 1483499 RW-shared spins 0, rounds 314940, OS waits 77827 RW-excl spins 0, rounds 205078, OS waits 7540 RW-sx spins 4357, rounds 47820, OS waits 949 Spin rounds per wait: 314940.00 RW-shared, 205078.00 RW-excl, 10.98 RW-sx |
or like
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
---------- SEMAPHORES ---------- OS WAIT ARRAY INFO: reservation count 1744302 --Thread 139964401002240 has waited at row0ins.cc line 2520 for 0 seconds the semaphore: X-lock (wait_ex) on RW-latch at 0x7f4c3d956890 created in file buf0buf.cc line 1433 a writer (thread id 139964401002240) has reserved it in mode wait exclusive number of readers 1, waiters flag 0, lock_word: ffffffffffffffff Last time read locked in file row0sel.cc line 3869 Last time write locked in file /mnt/workspace/percona-server-5.7-redhat-binary-rocks-new/label_exp/min-centos-7-x64/test/rpmbuild/BUILD/percona-server-5.7.28-31/percona-server-5.7.28-31/storage/innobase/row/row0upd.cc line 2881 OS WAIT ARRAY INFO: signal count 1483459 RW-shared spins 0, rounds 314905, OS waits 77813 RW-excl spins 0, rounds 204982, OS waits 7532 RW-sx spins 4357, rounds 47820, OS waits 949 Spin rounds per wait: 314905.00 RW-shared, 204982.00 RW-excl, 10.98 RW-sx |
Or incredibly long (not showing here).
The way that particular section was monitored is through the execution of an infinite loop:
|
1 |
while true; do mysql -N -e"show engine innodb statusG" | sed -n '/SEMAPHORES/,/TRANSACTIONS/p'; sleep 1; done |
But what should you do with that info?
From the current waits, what we need is the following:
Let’s use the first example, which is a server that experienced high concurrency for a while as seen in Percona Monitoring and Management:
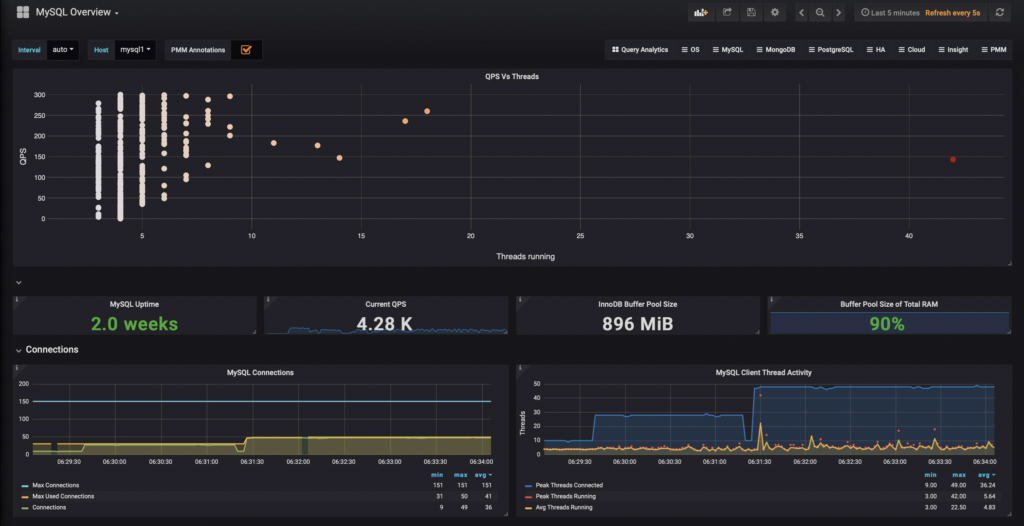
One can say: “but there’s only a peak of 42 threads and the majority of the throughput distribution is on the low concurrency side!” This is a 2 core VM with small physical memory and thus a pretty small buffer pool. An average of 22 for threads running is high concurrency.
Now, from the SEMAPHORES output of the first example we have:
|
1 |
--Thread 139964395677440 has waited at btr0cur.cc line 5889 for 0 seconds the semaphore: S-lock on RW-latch at 0x7f4c3d73c150 created in file buf0buf.cc line 1433 a writer (thread id 139964175062784) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0sea.cc line 1121 Last time write locked in file /mnt/workspace/percona-server-5.7-redhat-binary-rocks-new/label_exp/min-centos-7-x64/test/rpmbuild/BUILD/percona-server-5.7.28-31/percona-server-5.7.28-31/storage/innobase/btr/btr0sea.cc line 1121 |
What’s the MySQL version? The last line tells us: Percona Server 5.7.28-31
What’s the file and line? btr0cur.cc line 5889 has waited for an S-Lock on an RW-latch created in buf0buf.cc line 1433 but another thread has reserver in mode exclusive in file btr0sea.cc line 1121.
Ok, we have directions. Now let’s see what’s inside.
Do I need to download the source code for inspection? No, you don’t! What you need is to navigate to the code repository, which in this case is a GitHub repo.
And here is where the exact version comes handy. In order to guarantee that we are reading the exact line code, we better make sure we are reading the exact version.
GitHub is pretty easy to navigate and in this case, what we are looking for is Release. 5.7.28-31 to be precise. The Percona Server repo URL is: https://github.com/percona/percona-server/.
Once you are there, we need to find the release.
The release can be found in the link showed in the below graph:
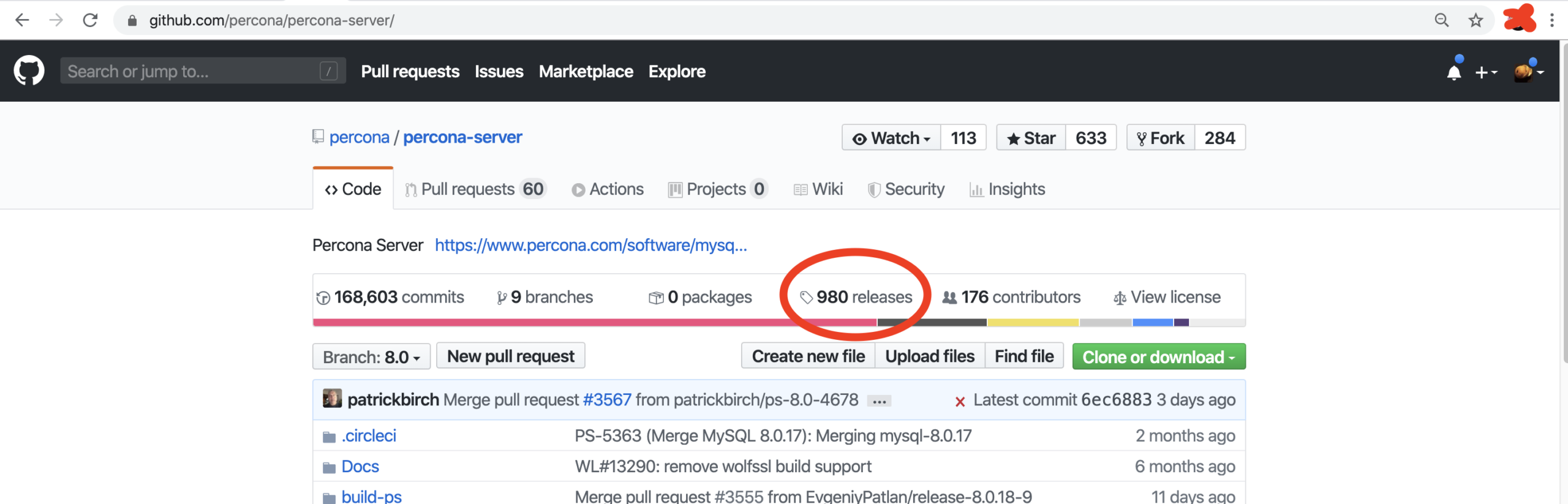
Inside one can see the releases:
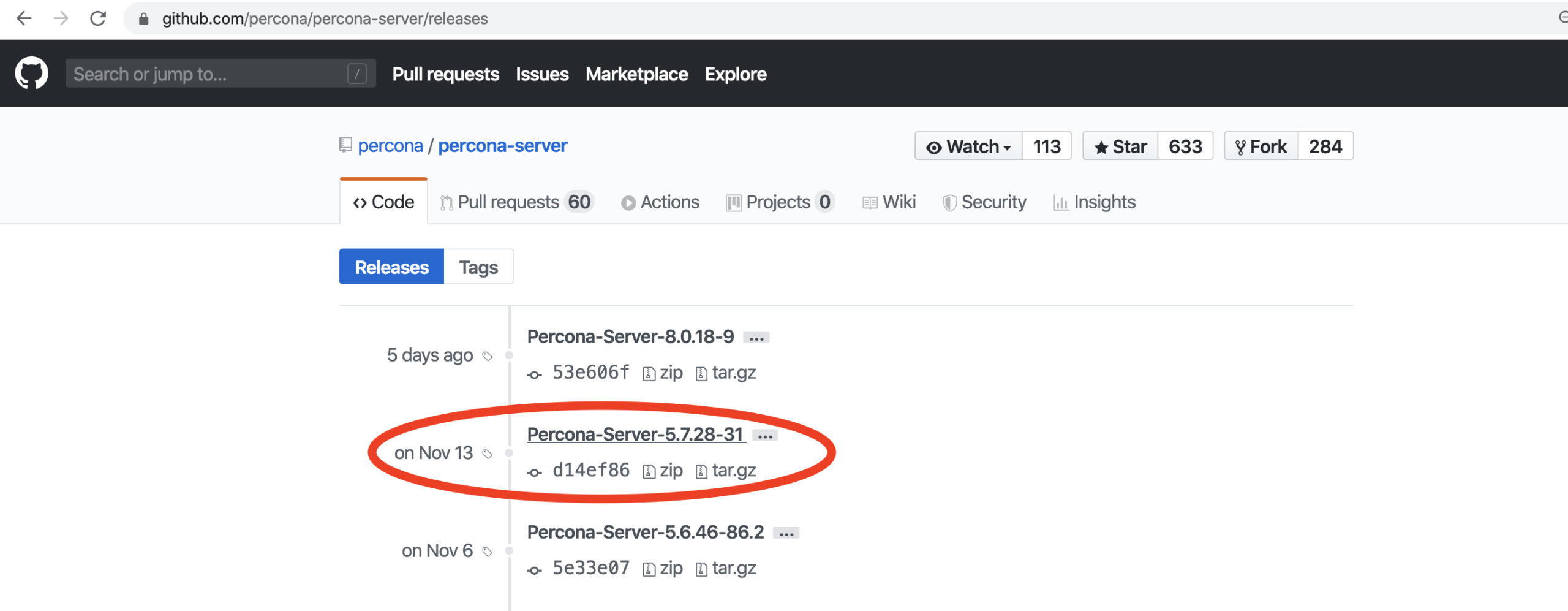
Click the link and it will take you to the tag page:
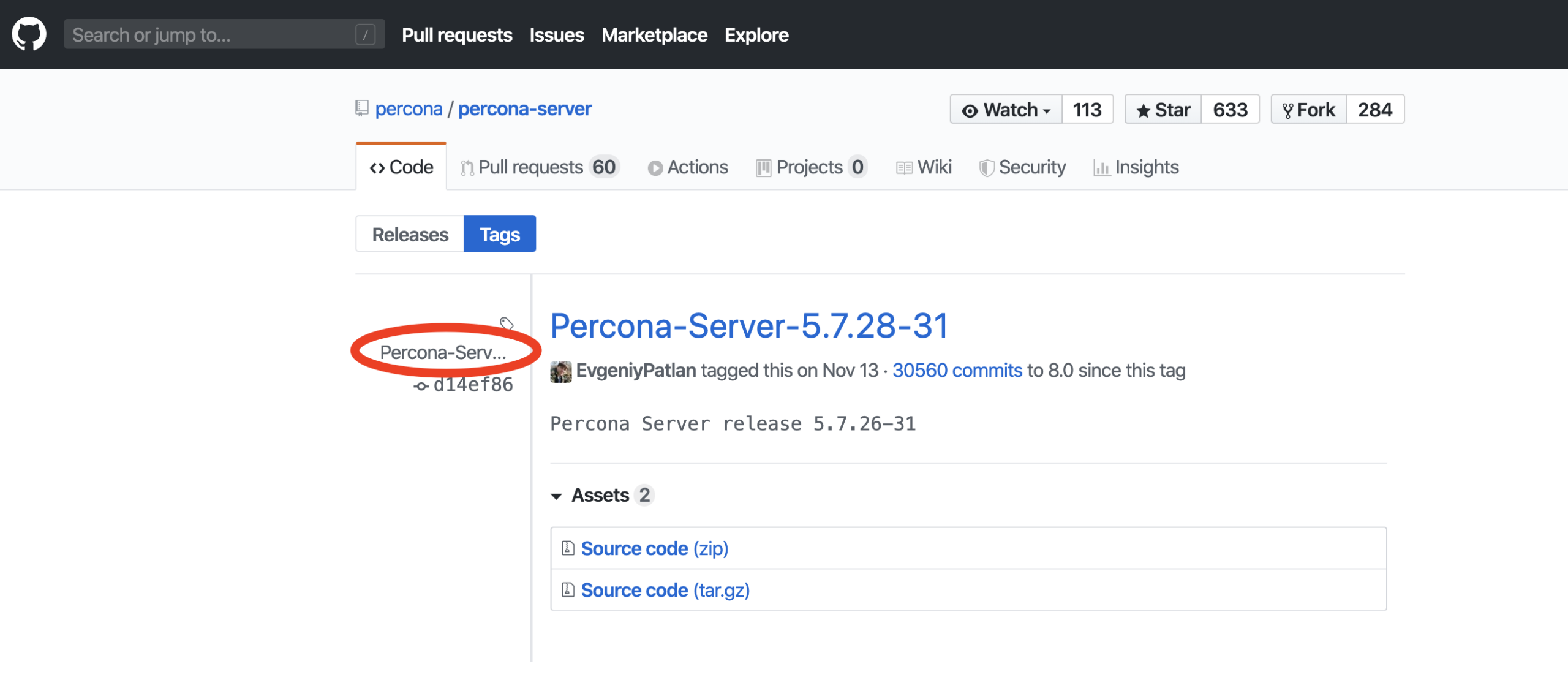
And finally, click the link shown above and you will be at the repo of the release needed: https://github.com/percona/percona-server/tree/Percona-Server-5.7.28-31
What’s next? Reading the actual content of the files.
The relevant part of the code tree is:
-root
---storage
------innobase
The InnoDB storage engine code is inside the “innobase” directory. Inside that directory, there’s a bunch of other directories. But how do you choose the correct one? Well, the filename has the answer. The files we need to look are:
All files have the same syntax: xxx0xxx.xx and the directory name is the part before the zero. In our case, we need to look inside two directories: btr and buf. Once inside the directories, finding the files is an easy task.
These are our files in the mentioned line numbers:
https://github.com/percona/percona-server/blob/Percona-Server-5.7.28-31/storage/innobase/btr/btr0sea.cc#L1121
https://github.com/percona/percona-server/blob/Percona-Server-5.7.28-31/storage/innobase/buf/buf0buf.cc#L1433
https://github.com/percona/percona-server/blob/Percona-Server-5.7.28-31/storage/innobase/btr/btr0cur.cc#L5889
The btr0sea.cc file as described in the head of the file is “The index tree adaptive search” a.k.a: the Adaptive Hash Index (AHI)
The buf0buf.cc as described in the file is “The database buffer buf_pool” a.k.a: the InnoDB buffer Pool
The btr0cur.cc as described in the file is “The index tree cursor” a.k.a: the actual B-Tree or where the data exists in InnoDB.
At btr0cur.cc line 5889 InnoDB is inside a function called btr_estimate_n_rows_in_range_low, and the description is documented as “Estimates the number of rows in a given index range” and the actual line is:
|
1 2 3 4 |
btr_cur_search_to_nth_level(index, 0, tuple1, mode1, BTR_SEARCH_LEAF | BTR_ESTIMATE, &cursor, 0, __FILE__, __LINE__, &mtr); |
But what is that btr_cur_search_to_nth_level? In the same file, we can find the definition and it is described as “Searches an index tree and positions a tree cursor on a given level”. So basically, it is looking for a row value. But that operation is stalled because it needs to acquire a shared resource that in this case is the buffer pool:
At buf0buf.cc line 1433, the buffer pool is trying to create a lock over a block
|
1 |
rw_lock_create(PFS_NOT_INSTRUMENTED, &block->lock, SYNC_LEVEL_VARYING); |
That operation happens inside a function called “buf_block_init” (find it by scrolling up in the code) and is described as “Initializes a buffer control block when the buf_pool is created”. This is actually creating the buffer pool space after an innodb_buffer_pool_size modification and is delayed.
At btr0sea.cc line 1121 the operation used was:
|
1 2 3 |
if (!buf_page_get_known_nowait( latch_mode, block, BUF_MAKE_YOUNG, __FILE__, __LINE__, mtr)) { |
That line is inside the function btr_search_guess_on_hash is described as “Tries to guess the right search position based on the hash search info of the index.” So, it is using info from the AHI. And the buf_page_get_known_nowait definition is “This is used to get access to a known database page, when no waiting can be done” which is pretty much self-explanatory.
So what do we have here? Contention on the AHI! Is this a problem? Let’s go back to the original line:
|
1 |
--Thread 139964395677440 has waited at btr0cur.cc line 5889 for 0 seconds the semaphore: |
It says that it has waited for 0 seconds. Contention disappeared pretty fast in this case. Also, something very important to notice: this contention appeared only ONCE during the time range monitored. That means that it is not a constant issue, falling into the category of not a problem. It happened once and happened fast.
But what if it was happening often? Then you should take action by increasing the buffer pool size, increasing the amount of AHI partitions, or even disabling the AHI entirely. All of those three options require testing, of course 🙂
The InnoDB code is pretty well documented to the extent that it helps in finding hot contention spots. Navigating the code is not an impossible task and the GitHub repositories make it pretty fast. Worth to mention is that in not every situation is it evident that the real problem and sometimes a deep understanding of the code comes handy. For those cases, Percona is here to help you to identify the issue and provide a solution.





Perfect timing for this post
Thank you ! I had to learn this, and this kind of up-to-date and simple tutorials were lacking