
Recently, at Percona Live Europe 2019, Dimitri Kravchuk from Oracle mentioned that he observed some unclear drop in performance for MySQL on an ext4 filesystem with the latest Linux kernels. I decided to check this case out on my side and found out that indeed, starting from linux kernel 4.9, there are some cases with notable (up to 2x) performance drops for ext4 filesystem in direct i/o mode.
So what’s wrong with ext4? It started in 2016 from the patch that was pushed to kernel 4.9: “ext4: Allow parallel DIO reads”. The purpose of that patch was to help to improve read scalability in direct i/o mode. However, along with improvements in pure read workloads, it also introduced regression in intense mixed random read/write scenarios. And it’s quite weird, but this issue had not been noticed for 3 years. Only this summer was performance regression reported and discussed in LKML. As a result of this discussion, there is an attempt to fix it, but from my current understanding that fix will be pushed only to upcoming 5.4/5.5 kernels. Below I will describe what this regression looks like, how it affects MySQL workloads, and what workarounds we can apply to mitigate this issue.
Let’s start by defining the scope of this ext4 performance regression. It will only have an impact if the setup/workload meets following conditions:
– fast ssd/nvme
– linux kernel>=4.9
– files resides on ext4 file system
– files opened with O_DIRECT flag
– at least some I/O should be synchronous
In the original report to LKML, the issue was observed/reproduced with a mixed random read/write scenario with sync I/O and O_DIRECT. But how do these factors relate to MySQL? The only files opened by InnoDB in O_DIRECT mode are tablespaces (*.ibd files), and I/O pattern for tablespaces consists of following operations:
– reads ibd data in synchronous mode
– writes ibd data in asynchronous mode
– posix_allocate to extend tablespace file followed by a synchronous write
– fsync
There are also extra I/O from WAL log files:
– writes data to log files in synchronous mode
– fsync
So in the case of InnoDB tablespaces that are opened with O_DIRECT, we have a mix of sync reads and async writes and it turned out that such a combination along with sync writes to innodb log file is enough to cause notable performance regression as well. I have sketched the workload for fio tool (see below) that simulates the I/O access pattern for InnoDB and have run it for SSD and NVMe drives for linux kernels 4.4.0, 5.3.0, and 5.3.0 with ext4 scalability fix.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
[global] filename=tablespace1.ibd:tablespace2.ibd:tablespace3.ibd:tablespace4.ibd:tablespace5.ibd direct=1 bs=16k iodepth=1 #read data from *.ibd tablespaces [ibd_sync_read] rw=randread ioengine=psync #write data to *.ibd tavlespaces [ibd_async_write] rw=randwrite ioengine=libaio #write data to ib* log file [ib_log_sync_write] rw=write bs=8k direct=0 ioengine=psync fsync=1 filename=log.ib numjobs=1 |
fio results on the chart:
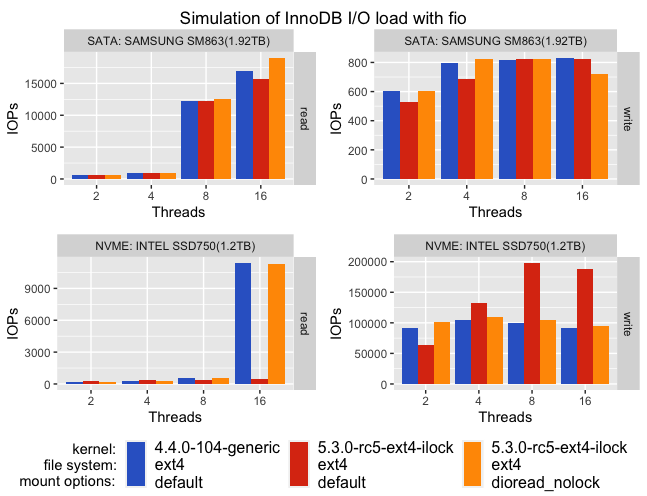
– for SATA/SSD drive there is almost no difference in throughtput, and only at 16 threads do we see a drop in reads for ext4/kernel-5.3.0. For ext4/kernel-5.3.0 mounted with dioread_nolock (that enables scalability fixes), we see that IOPS back and even look better.
– for NVMe drive the situation looks quite different – until 8 i/o threads IOPS for both reads and writes are more/less similar but after increasing pressure on i/o we see a notable spike for writes and similar drop for reads. And again mounting ext4 with dioread_nolock helps to get the same throughput as and for kernels < 4.9.
The similar performance data for the original issue reported to LKML (with more details and analysis) can be found in the patch itself.
Now let’s check the impact of this issue on an IO-bound sysbench/OLTP_RW workload in O_DIRECT mode. I ran a test for the following setup:
– filesystem: xfs, ext4/default, ext4/dioread_nolock
– drives: SATA/SSD and NVMe
– kernels: 4.4.0, 5.3.0, 5.3.0+ilock_fix
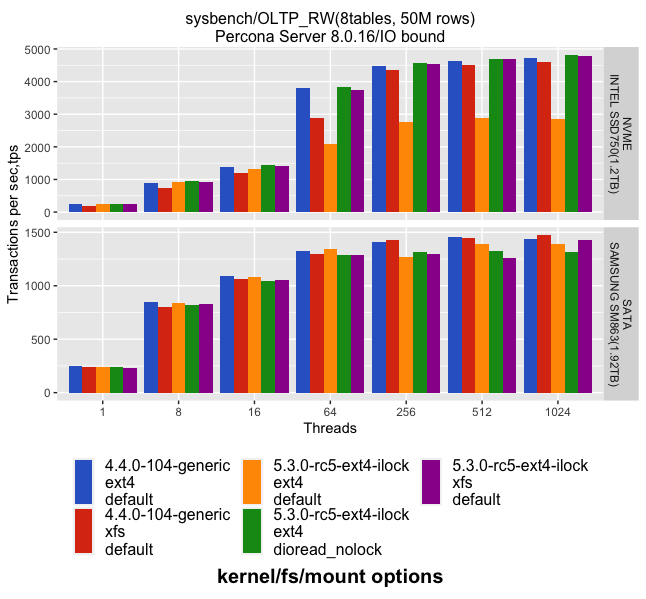
– in the case of SATA/SSD, the ext4 scalability issue has an impact on tps rate after 256 threads and drop is 10-15%
– in the case of NVMe and regular ext4 with kernel 5.3.0 causes performance drop in ~30-80%. If we apply a fix by mounting ext4 with dioread_nolock or use xfs, throughput looks good.
As ext4 regression affects O_DIRECT, let’s replace O_DIRECT with O_DSYNC and look at results of the same sysbench/OLTP_RW workload on kernel 5.3.0:
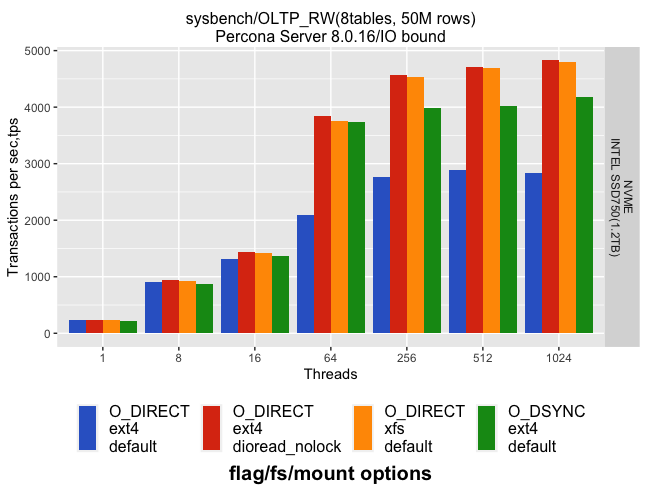
Note: In order to make results between O_DIRECT and O_DSYNC comparable, I have limited available memory for MySQL instance by cgroup.
In the case of O_DSYNC and regular ext4, the performance is just 10% less than for O_DIRECT/ext4/dioread_nolock and O_DIRECT/xfs and ~35% better than for O_DIRECT/ext4. That means that O_DSYNC can be used as a workaround for cases when you have fast storage and ext4 as filesystem but can’t switch to xfs or upgrade kernel.
If your workload/setup is affected, there are the following options that you may consider as a workaround:
– downgrade linux kernel to 4.8
– install kernel 5.3.0 with fix and mount ext4 with dioread_nolock option
– if O_DIRECT is important, switch to xfs filesystem
– if changing filesystem is not an option, replace O_DIRECT with O_DSYNC+cgroup





Remember, you can also disable write barriers to increase perf on Ext4
Alexey, So “dioread_nolock” – it increases performance but does it have any impact to the data consistency or durability ? If it just improves performance why is not it default ?
Peter, there is a mix of two aspects of “dioread_nolock” option:
1) in regular kernel this option should improve performance for unbuffered(direct i/o) reads however it will not help with observed performance drop
2) in the branch of kernel 5.3.0 with fix – this option is used not only in the meaning as for regular kernel but also to solve observed scalability issue
re: why it is not default – because it has specifc area of application – direct I/O and likely may have impact on buffered.
Hi, can you provide the sysbench parameters you used?