
 From time to time you may have experienced that MySQL was not able to find the best execution plan for a query. You felt the query should have been faster. You felt that something didn’t work, but you didn’t realize exactly what.
From time to time you may have experienced that MySQL was not able to find the best execution plan for a query. You felt the query should have been faster. You felt that something didn’t work, but you didn’t realize exactly what.
Maybe some of you did tests and discovered there was a better execution plan that MySQL wasn’t able to find (forcing the order of the tables with STRAIGHT_JOIN for example).
In this article, we’ll see a new interesting feature available on MySQL 8.0 as well as Percona Server for MySQL 8.0: the histogram-based statistics.
Today, we’ll see what a histogram is, how you can create and manage it, and how MySQL’s optimizer can use it.
Just for completeness, histogram statistics have been available on MariaDB since version 10.0.2, with a slightly different implementation. Anyway, what we’ll see here is related to Percona Server and MySQL 8.0 only.
We can define a histogram as a good approximation of the data distribution of the values in a column.
Histogram-based statistics were introduced to give the optimizer more execution plans to investigate and solve a query. Until then, in some cases, the optimizer was not able to find out the best possible execution plan because non-indexed columns were ignored.
With histogram statistics, now the optimizer may have more options because also non-indexed columns can be considered. In some specific cases, a query can run faster than usual.
Let’s consider the following table to store departing times of the trains:
|
1 2 3 4 5 |
CREATE TABLE train_schedule( id INT PRIMARY KEY, train_code VARCHAR(10), departure_station VARCHAR(100), departure_time TIME); |
We can assume that during peak hours, from 7 AM until 9 AM, there are more rows, and during the night hours we have very few rows.
Let’s take a look at the following two queries:
|
1 2 |
SELECT * FROM train_schedule WHERE departure_time BETWEEN '07:30:00' AND '09:15:00'; SELECT * FROM train_schedule WHERE departure_time BETWEEN '01:00:00' AND '03:00:00'; |
Without any kind of statistics, the optimizer assumes by default that the values in the departure_time column are evenly distributed, but they aren’t. In fact, the first query returns more rows because of this assumption.
Histograms were invented to provide to the optimizer a good estimation of the rows returned. This seems to be trivial for the simple queries we have seen so far. But let’s think now about having the same table involved in JOINs with other tables. In such a case, the number of rows returned can be very important for the optimizer to decide the order to consider the tables in the execution plan.
A good estimation of the rows returned gives the optimizer the capability to open the table in the first stages in case it returns few rows. This minimizes the total amount of rows for the final cartesian product. Then the query can run faster.
MySQL supports two different types of histograms: “singleton” and “equi-height”. Common for all histogram types is that they split the data set into a set of “buckets”, and MySQL automatically divides the values into the buckets and will also automatically decide what type of histogram to create.
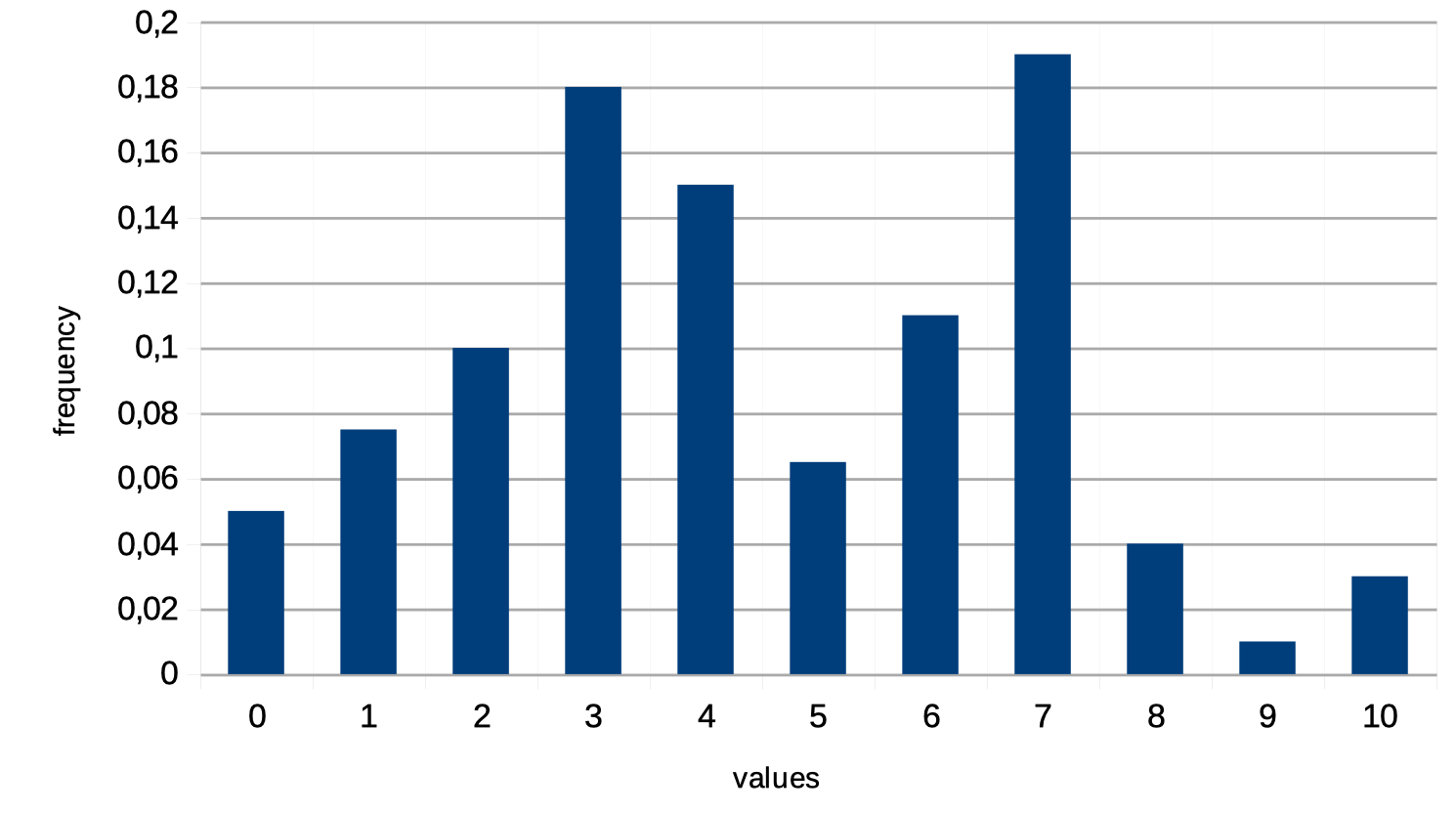
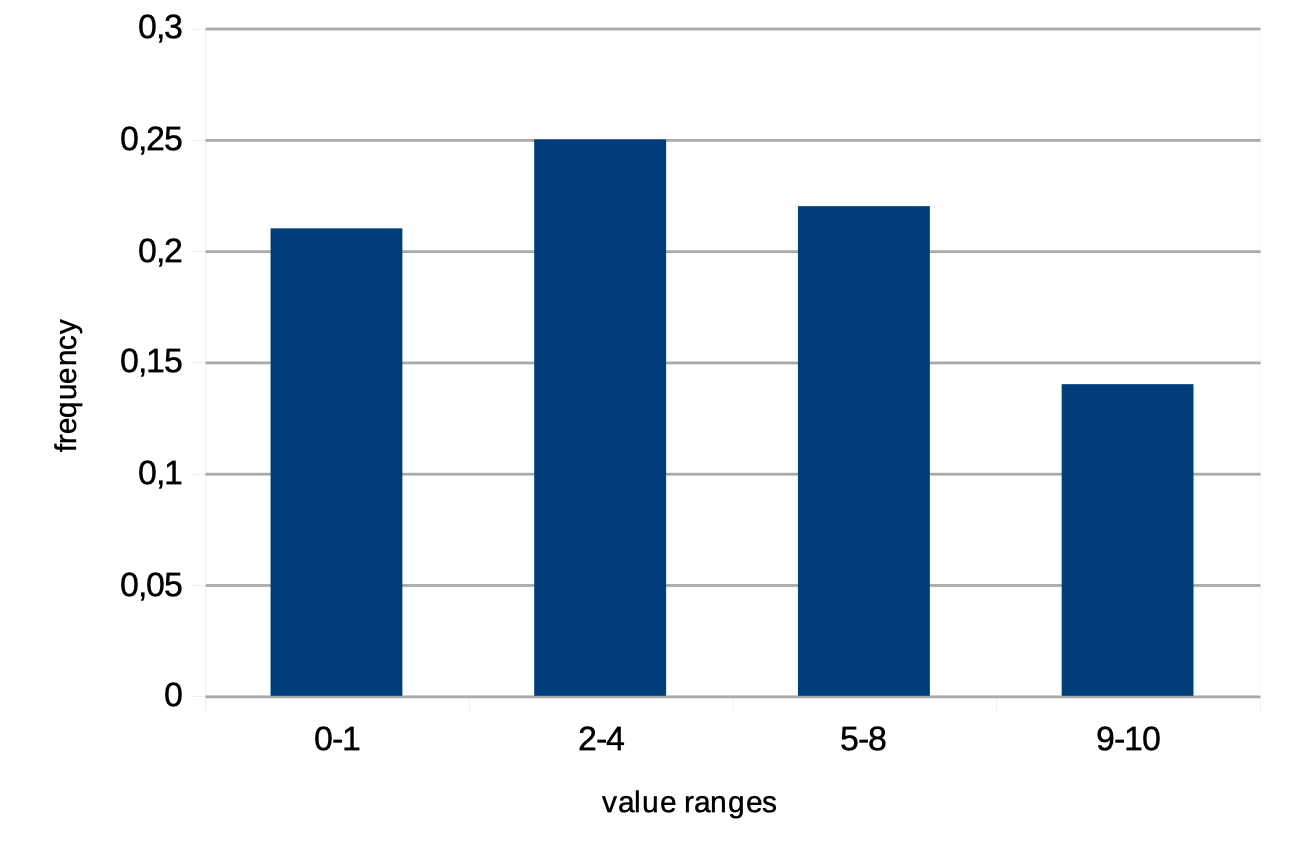
The histogram feature is available and enabled on the server, but not usable by the optimizer. Without an explicit creation, the optimizer works the same as usual and cannot get any benefit from the histogram-bases statistics.
There is some manual operation to do. Let’s see.
In the next examples, we’ll use the world sample database you can download from here: https://dev.mysql.com/doc/index-other.html
Let’s start executing a query joining two tables to find out all the languages spoken on the largest cities of the world, with more than 10 million people.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mysql> select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000; +-----------------+-----------+ | name | language | +-----------------+-----------+ | Mumbai (Bombay) | Asami | | Mumbai (Bombay) | Bengali | | Mumbai (Bombay) | Gujarati | | Mumbai (Bombay) | Hindi | | Mumbai (Bombay) | Kannada | | Mumbai (Bombay) | Malajalam | | Mumbai (Bombay) | Marathi | | Mumbai (Bombay) | Orija | | Mumbai (Bombay) | Punjabi | | Mumbai (Bombay) | Tamil | | Mumbai (Bombay) | Telugu | | Mumbai (Bombay) | Urdu | +-----------------+-----------+ 12 rows in set (0.04 sec) |
The query takes 0.04 seconds. It’s not a lot, but consider that the database is very small. Use the BENCHMARK function to have more relevant response times if you like.
Let’s see the EXPLAIN:
|
1 2 3 4 5 6 7 |
mysql> explain select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000; +----+-------------+-----------------+------------+-------+---------------------+-------------+---------+-----------------------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------------+------------+-------+---------------------+-------------+---------+-----------------------------------+------+----------+-------------+ | 1 | SIMPLE | countrylanguage | NULL | index | PRIMARY,CountryCode | CountryCode | 3 | NULL | 984 | 100.00 | Using index | | 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | world.countrylanguage.CountryCode | 18 | 33.33 | Using where | +----+-------------+-----------------+------------+-------+---------------------+-------------+---------+-----------------------------------+------+----------+-------------+ |
Indexes are used for both the tables and the estimated cartesian product has 984 * 18 = 17,712 rows.
Now generate the histogram on the Population column. It’s the only column used for filtering the data and it’s not indexed.
For that, we have to use the ANALYZE command:
|
1 2 3 4 5 6 |
mysql> ANALYZE TABLE city UPDATE HISTOGRAM ON population WITH 1024 BUCKETS; +------------+-----------+----------+-------------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +------------+-----------+----------+-------------------------------------------------------+ | world.city | histogram | status | Histogram statistics created for column 'Population'. | +------------+-----------+----------+-------------------------------------------------------+ |
We have created a histogram using 1024 buckets. The number of buckets is not mandatory, and it can be any number from 1 to 1024. If omitted, the default value is 100.
The number of chunks affects the reliability of the statistics. The more distinct values you have, the more the chunks you need.
Let’s have a look now at the execution plan and execute the query again.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
mysql> explain select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000; +----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+ | 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 0.06 | Using where | | 1 | SIMPLE | countrylanguage | NULL | ref | PRIMARY,CountryCode | CountryCode | 3 | world.city.CountryCode | 984 | 100.00 | Using index | +----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+ mysql> select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000; +-----------------+-----------+ | name | language | +-----------------+-----------+ | Mumbai (Bombay) | Asami | | Mumbai (Bombay) | Bengali | | Mumbai (Bombay) | Gujarati | | Mumbai (Bombay) | Hindi | | Mumbai (Bombay) | Kannada | | Mumbai (Bombay) | Malajalam | | Mumbai (Bombay) | Marathi | | Mumbai (Bombay) | Orija | | Mumbai (Bombay) | Punjabi | | Mumbai (Bombay) | Tamil | | Mumbai (Bombay) | Telugu | | Mumbai (Bombay) | Urdu | +-----------------+-----------+ 12 rows in set (0.00 sec) |
The execution plan is different, and the query runs faster.
We can notice that the order of the tables is the opposite as before. Even if it requires a full scan, the city table is in the first stage. It’s because of the filtered value that is only 0.06. It means that only 0.06% of the rows returned by the full scan will be used to be joined with the following table. So, it’s only 4188 * 0.06% = 2.5 rows. In total, the estimated cartesian product is 2.5 * 984 = 2.460 rows. This is significantly lower than the previous execution and explains why the query is faster.
What we have seen sounds a little counterintuitive, doesn’t it? In fact, until MySQL 5.7, we were used to considering full scans as very bad in most cases. In our case, instead, forcing a full scan using a histogram statistic on a non-indexed column lets the query to get optimized. Awesome.
Histogram statistics are stored in the column_statistics table in the data dictionary and are not directly accessible by the users. Instead the INFORMATION_SCHEMA.COLUMN_STATISTICS table, which is implemented as a view of the data dictionary, can be used for the same purpose.
Let’s see the statistics for our table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
mysql> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM) -> FROM information_schema.column_statistics -> WHERE COLUMN_NAME = 'population'G *************************** 1. row *************************** SCHEMA_NAME: world TABLE_NAME: city COLUMN_NAME: Population JSON_PRETTY(HISTOGRAM): { "buckets": [ [ 42, 455, 0.000980632507967639, 4 ], [ 503, 682, 0.001961265015935278, 4 ], [ 700, 1137, 0.0029418975239029173, 4 ], ... ... [ 8591309, 9604900, 0.9990193674920324, 4 ], [ 9696300, 10500000, 1.0, 4 ] ], "data-type": "int", "null-values": 0.0, "collation-id": 8, "last-updated": "2019-10-14 22:24:58.232254", "sampling-rate": 1.0, "histogram-type": "equi-height", "number-of-buckets-specified": 1024 } |
We can see for any chunk the min and max values, the cumulative frequency, and the number of items. Also, we can see that MySQL decided to use an equi-height histogram.
Let’s try to generate a histogram on another table and column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 |
mysql> ANALYZE TABLE country UPDATE HISTOGRAM ON Region; +---------------+-----------+----------+---------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +---------------+-----------+----------+---------------------------------------------------+ | world.country | histogram | status | Histogram statistics created for column 'Region'. | +---------------+-----------+----------+---------------------------------------------------+ 1 row in set (0.01 sec) mysql> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM) FROM information_schema.column_statistics WHERE COLUMN_NAME = 'Region'G *************************** 1. row *************************** SCHEMA_NAME: world TABLE_NAME: country COLUMN_NAME: Region JSON_PRETTY(HISTOGRAM): { "buckets": [ [ "base64:type254:QW50YXJjdGljYQ==", 0.02092050209205021 ], [ "base64:type254:QXVzdHJhbGlhIGFuZCBOZXcgWmVhbGFuZA==", 0.04184100418410042 ], [ "base64:type254:QmFsdGljIENvdW50cmllcw==", 0.05439330543933054 ], [ "base64:type254:QnJpdGlzaCBJc2xhbmRz", 0.06276150627615062 ], [ "base64:type254:Q2FyaWJiZWFu", 0.1631799163179916 ], [ "base64:type254:Q2VudHJhbCBBZnJpY2E=", 0.20083682008368198 ], [ "base64:type254:Q2VudHJhbCBBbWVyaWNh", 0.23430962343096232 ], [ "base64:type254:RWFzdGVybiBBZnJpY2E=", 0.3179916317991631 ], [ "base64:type254:RWFzdGVybiBBc2lh", 0.35146443514644343 ], [ "base64:type254:RWFzdGVybiBFdXJvcGU=", 0.39330543933054385 ], [ "base64:type254:TWVsYW5lc2lh", 0.41422594142259406 ], [ "base64:type254:TWljcm9uZXNpYQ==", 0.44351464435146437 ], [ "base64:type254:TWljcm9uZXNpYS9DYXJpYmJlYW4=", 0.4476987447698744 ], [ "base64:type254:TWlkZGxlIEVhc3Q=", 0.5230125523012552 ], [ "base64:type254:Tm9yZGljIENvdW50cmllcw==", 0.5523012552301255 ], [ "base64:type254:Tm9ydGggQW1lcmljYQ==", 0.5732217573221757 ], [ "base64:type254:Tm9ydGhlcm4gQWZyaWNh", 0.602510460251046 ], [ "base64:type254:UG9seW5lc2lh", 0.6443514644351465 ], [ "base64:type254:U291dGggQW1lcmljYQ==", 0.7029288702928871 ], [ "base64:type254:U291dGhlYXN0IEFzaWE=", 0.7489539748953975 ], [ "base64:type254:U291dGhlcm4gQWZyaWNh", 0.7698744769874477 ], [ "base64:type254:U291dGhlcm4gYW5kIENlbnRyYWwgQXNpYQ==", 0.8284518828451883 ], [ "base64:type254:U291dGhlcm4gRXVyb3Bl", 0.891213389121339 ], [ "base64:type254:V2VzdGVybiBBZnJpY2E=", 0.9623430962343097 ], [ "base64:type254:V2VzdGVybiBFdXJvcGU=", 1.0 ] ], "data-type": "string", "null-values": 0.0, "collation-id": 8, "last-updated": "2019-10-14 22:29:13.418582", "sampling-rate": 1.0, "histogram-type": "singleton", "number-of-buckets-specified": 100 } |
In this case, a singleton histogram was generated.
Using the following query we can see more human-readable statistics.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
mysql> SELECT SUBSTRING_INDEX(v, ':', -1) value, concat(round(c*100,1),'%') cumulfreq, -> CONCAT(round((c - LAG(c, 1, 0) over()) * 100,1), '%') freq -> FROM information_schema.column_statistics, JSON_TABLE(histogram->'$.buckets','$[*]' COLUMNS(v VARCHAR(60) PATH '$[0]', c double PATH '$[1]')) hist -> WHERE schema_name = 'world' and table_name = 'country' and column_name = 'region'; +---------------------------+-----------+-------+ | value | cumulfreq | freq | +---------------------------+-----------+-------+ | Antarctica | 2.1% | 2.1% | | Australia and New Zealand | 4.2% | 2.1% | | Baltic Countries | 5.4% | 1.3% | | British Islands | 6.3% | 0.8% | | Caribbean | 16.3% | 10.0% | | Central Africa | 20.1% | 3.8% | | Central America | 23.4% | 3.3% | | Eastern Africa | 31.8% | 8.4% | | Eastern Asia | 35.1% | 3.3% | | Eastern Europe | 39.3% | 4.2% | | Melanesia | 41.4% | 2.1% | | Micronesia | 44.4% | 2.9% | | Micronesia/Caribbean | 44.8% | 0.4% | | Middle East | 52.3% | 7.5% | | Nordic Countries | 55.2% | 2.9% | | North America | 57.3% | 2.1% | | Northern Africa | 60.3% | 2.9% | | Polynesia | 64.4% | 4.2% | | South America | 70.3% | 5.9% | | Southeast Asia | 74.9% | 4.6% | | Southern Africa | 77.0% | 2.1% | | Southern and Central Asia | 82.8% | 5.9% | | Southern Europe | 89.1% | 6.3% | | Western Africa | 96.2% | 7.1% | | Western Europe | 100.0% | 3.8% | +---------------------------+-----------+-------+ |
Histogram statistics are not automatically recalculated. If you have a table that is very frequently updated with a lot of INSERTs, UPDATEs, and DELETEs, the statistics can run out of date very soon. Having unreliable histograms can lead the optimizer to the wrong choice.
When you find a histogram was useful to optimize a query, you need to also have a scheduled plan to refresh the statistics from time to time, in particular after doing massive modifications to the table.
To refresh a histogram you just need to run the same ANALYZE command we have seen before.
To completely drop a histogram you may run the following:
|
1 |
ANALYZE TABLE city DROP HISTOGRAM ON population; |
The histogram_generation_max_mem_size system variable controls the maximum amount of memory available for histogram generation. The global and session values may be set at runtime.
If the estimated amount of data to be read into memory for histogram generation exceeds the limit defined by the variable, MySQL samples the data rather than reading all of it into memory. Sampling is evenly distributed over the entire table.
The default value is 20000000 but you can increase it in the case of a large column if you want more accurate statistics. For very large columns, pay attention not to increase the threshold more than the memory available in order to avoid excessive overhead or outage.
Histogram statistics are particularly useful for non-indexed columns, as shown in the example.
Execution plans that can rely on indexes are usually the best, but histograms can help in some edge cases or when creating a new index is a bad idea.
Since this is not an automatic feature, some manual testing is required to investigate if you really can get the benefit of a histogram. Also, the maintenance requires some scheduled and manual activity.
Use histograms if you really need them, but don’t abuse them since histograms on very large tables can consume a lot of memory.
Usually, the best candidates for a histogram are the columns with:
Install Percona Server 8.0, test and enjoy the histograms.
Further reading on the same topic: Billion Goods in Few Categories – How Histograms Save a Life?




