
In this research, I wanted to see what kind of performance improvements could be gained by using a ClickHouse data source rather than PostgreSQL. Assuming that I would see performance advantages with using ClickHouse, would those advantages be retained if I access ClickHouse from within postgres using a foreign data wrapper (FDW)? The FDW in question is clickhousedb_fdw – an open source project from Percona!
The database environments under scrutiny are PostgreSQL v11, clickhousedb_fdw and a ClickHouse database. Ultimately, from within PostgreSQL v11, we are going to issue various SQL queries routed through our clickhousedb_fdw to the ClickHouse database. Then we’ll see how the FDW performance compares with those same queries executed in native PostgreSQL and native ClickHouse.
ClickHouse is an open source column based database management system which can achieve performance of between 100 and 1000 times faster than traditional database approaches, capable of processing more than a billion rows in less than a second.
clickhousedb_fdw, a ClickHouse database foreign data wrapper, or FDW, is an open source project from Percona. Here’s a link for the GitHub project repository:
https://github.com/Percona-Lab/clickhousedb_fdw
I wrote a blog in March which tells you more about our FDW: https://www.percona.com/blog/2019/03/29/postgresql-access-clickhouse-one-of-the-fastest-column-dbmss-with-clickhousedb_fdw/
As you’ll see, this provides for an FDW for ClickHouse that allows you to SELECT from, and INSERT INTO, a ClickHouse database from within a PostgreSQL v11 server.
The FDW supports advanced features such as aggregate pushdown and joins pushdown. These significantly improve performance by utilizing the remote server’s resources for these resource intensive operations.
Rather than using some machine generated dataset for this benchmark, we used the “On Time Reporting Carrier On-Time Performance” data from 1987 to 2018. You can access the data using our shell script available here:
https://github.com/Percona-Lab/ontime-airline-performance/blob/master/download.sh
The size of the database is 85GB, providing a single table of 109 columns.
Here are the queries I used to benchmark the ClickHouse, clickhousedb_fdw, and PostgreSQL.
| Q# | Query Contains Aggregates and Group By |
| Q1 | SELECT DayOfWeek, count(*) AS c FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC; |
| Q2 | SELECT DayOfWeek, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC; |
| Q3 | SELECT Origin, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Origin ORDER BY c DESC LIMIT 10; |
| Q4 | SELECT Carrier, count(*) FROM ontime WHERE DepDelay>10 AND Year = 2007 GROUP BY Carrier ORDER BY count(*) DESC; |
| Q5 | SELECT a.Carrier, c, c2, c*1000/c2 as c3 FROM ( SELECT Carrier, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year=2007 GROUP BY Carrier ) a INNER JOIN ( SELECT Carrier,count(*) AS c2 FROM ontime WHERE Year=2007 GROUP BY Carrier)b on a.Carrier=b.Carrier ORDER BY c3 DESC; |
| Q6 | SELECT a.Carrier, c, c2, c*1000/c2 as c3 FROM ( SELECT Carrier, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Carrier) a INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier ) b on a.Carrier=b.Carrier ORDER BY c3 DESC; |
| Q7 | SELECT Carrier, avg(DepDelay) * 1000 AS c3 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier; |
| Q8 | SELECT Year, avg(DepDelay) FROM ontime GROUP BY Year; |
| Q9 | select Year, count(*) as c1 from ontime group by Year; |
| Q10 | SELECT avg(cnt) FROM (SELECT Year,Month,count(*) AS cnt FROM ontime WHERE DepDel15=1 GROUP BY Year,Month) a; |
| Q11 | select avg(c1) from (select Year,Month,count(*) as c1 from ontime group by Year,Month) a; |
| Q12 | SELECT OriginCityName, DestCityName, count(*) AS c FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY c DESC LIMIT 10; |
| Q13 | SELECT OriginCityName, count(*) AS c FROM ontime GROUP BY OriginCityName ORDER BY c DESC LIMIT 10; |
| Query Contains Joins | |
| Q14 | SELECT a.Year, c1/c2 FROM ( select Year, count(*)*1000 as c1 from ontime WHERE DepDelay>10 GROUP BY Year) a INNER JOIN (select Year, count(*) as c2 from ontime GROUP BY Year ) b on a.Year=b.Year ORDER BY a.Year; |
| Q15 | SELECT a.”Year”, c1/c2 FROM ( select “Year”, count(*)*1000 as c1 FROM fontime WHERE “DepDelay”>10 GROUP BY “Year”) a INNER JOIN (select “Year”, count(*) as c2 FROM fontime GROUP BY “Year” ) b on a.”Year”=b.”Year”; |
Table-1: Queries used in benchmark
Here are the results from the each of the queries when run in different database set ups: PostgreSQL with and without indexes, native ClickHouse and clickhousedb_fdw. The time is shown in milliseconds.
| Q# | PostgreSQL | PostgreSQL (Indexed) | ClickHouse | clickhousedb_fdw |
| Q1 | 27920 | 19634 | 23 | 57 |
| Q2 | 35124 | 17301 | 50 | 80 |
| Q3 | 34046 | 15618 | 67 | 115 |
| Q4 | 31632 | 7667 | 25 | 37 |
| Q5 | 47220 | 8976 | 27 | 60 |
| Q6 | 58233 | 24368 | 55 | 153 |
| Q7 | 30566 | 13256 | 52 | 91 |
| Q8 | 38309 | 60511 | 112 | 179 |
| Q9 | 20674 | 37979 | 31 | 81 |
| Q10 | 34990 | 20102 | 56 | 148 |
| Q11 | 30489 | 51658 | 37 | 155 |
| Q12 | 39357 | 33742 | 186 | 1333 |
| Q13 | 29912 | 30709 | 101 | 384 |
| Q14 | 54126 | 39913 | 124 | 1364212 |
| Q15 | 97258 | 30211 | 245 | 259 |
Table-1: Time taken to execute the queries used in benchmark
The graph shows the query execution time in milliseconds, the X-axis shows the query number from the tables above, while the Y-axis shows the execution time in milliseconds. The results for ClickHouse and the data accessed from postgres using clickhousedb_fdw are shown. From the table, you can see there is a huge difference between PostgreSQL and ClickHouse, but there is minimal difference between ClickHouse and clickhousedb_fdw.
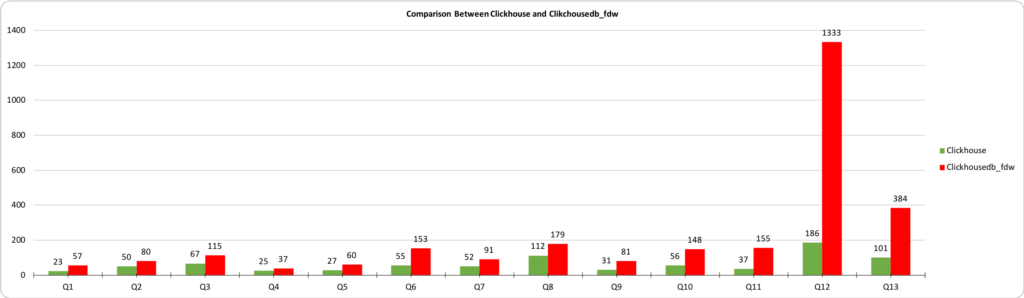
This graph shows the difference between ClickhouseDB and clickhousedb_fdw. In most of the queries, the FDW overhead is not that great, and barely significant apart from in Q12. This query involves joins and ORDER BY clause. Because of the ORDER BY clause the GROUP/BY and ORDER BY does not push down to ClickHouse.
In Table-2 we can see the spike of time in query Q12 and Q13. To reiterate, this is caused by the ORDER BY clause. To confirm this, I ran a queries Q-14 and Q-15 with and without the ORDER BY clause. Without the ORDER BY clause the completion time is 259ms and with ORDER BY clause, it is 1364212. To debug that the query I explain both the queries, and here is the results of explain.
|
1 2 3 |
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2 FROM (SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a INNER JOIN(SELECT "Year", count(*) AS c2 FROM fontime GROUP BY "Year") b ON a."Year"=b."Year"; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
QUERY PLAN Hash Join (cost=2250.00..128516.06 rows=50000000 width=12) Output: fontime."Year", (((count(*) * 1000)) / b.c2) Inner Unique: true Hash Cond: (fontime."Year" = b."Year") -> Foreign Scan (cost=1.00..-1.00 rows=100000 width=12) Output: fontime."Year", ((count(*) * 1000)) Relations: Aggregate on (fontime) Remote SQL: SELECT "Year", (count(*) * 1000) FROM "default".ontime WHERE (("DepDelay" > 10)) GROUP BY "Year" -> Hash (cost=999.00..999.00 rows=100000 width=12) Output: b.c2, b."Year" -> Subquery Scan on b (cost=1.00..999.00 rows=100000 width=12) Output: b.c2, b."Year" -> Foreign Scan (cost=1.00..-1.00 rows=100000 width=12) Output: fontime_1."Year", (count(*)) Relations: Aggregate on (fontime) Remote SQL: SELECT "Year", count(*) FROM "default".ontime GROUP BY "Year"(16 rows) |
|
1 2 3 |
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2 FROM(SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a INNER JOIN(SELECT "Year", count(*) as c2 FROM fontime GROUP BY "Year") b ON a."Year"= b."Year" ORDER BY a."Year"; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
QUERY PLAN Merge Join (cost=2.00..628498.02 rows=50000000 width=12) Output: fontime."Year", (((count(*) * 1000)) / (count(*))) Inner Unique: true Merge Cond: (fontime."Year" = fontime_1."Year") -> GroupAggregate (cost=1.00..499.01 rows=1 width=12) Output: fontime."Year", (count(*) * 1000) Group Key: fontime."Year" -> Foreign Scan on public.fontime (cost=1.00..-1.00 rows=100000 width=4) Remote SQL: SELECT "Year" FROM "default".ontime WHERE (("DepDelay" > 10)) ORDER BY "Year" ASC -> GroupAggregate (cost=1.00..499.01 rows=1 width=12) Output: fontime_1."Year", count(*) Group Key: fontime_1."Year" -> Foreign Scan on public.fontime fontime_1 (cost=1.00..-1.00 rows=100000 width=4) Remote SQL: SELECT "Year" FROM "default".ontime ORDER BY "Year" ASC(16 rows) |
The results from these experiments show that ClickHouse offers really good performance, and clickhousedb_fdw offers the benefits of ClickHouse performance from within PostgreSQL. While there is some overhead when using clickhousedb_fdw, it is negligible and is comparable to the performance achieved when running natively within the ClickHouse database. This also confirms that the PostgreSQL foreign data wrapper push-down feature provides wonderful results.





Is the data cached by the DBMS or OS?
Is parallel query in Postgres an option for these queries?
Somehow my setup on centos return constant zero cost on foreign scan that doesn’t push down the aggregation. Any hint ?
Can you please create an issue with complete detail, I will look at this.