
 When I attended AWS Re:Invent 2018, I saw there was a lot of attention from both customers and the AWS team on Amazon RDS Aurora Serverless. So I decided to take a deeper look at this technology, and write a series of blog posts on this topic.
When I attended AWS Re:Invent 2018, I saw there was a lot of attention from both customers and the AWS team on Amazon RDS Aurora Serverless. So I decided to take a deeper look at this technology, and write a series of blog posts on this topic.
In this first post of the series, you will learn about Amazon Aurora Serverless basics and use cases. In later posts, I will share benchmark results and in depth realization results.
A great source of information on this topic is How Amazon Aurora Serverless Works from the official AWS documentation. In this article, you learn what Serverless deployment rather than provisional deployment means. Instead of specifying an instance size you specify the minimum and maximum number of “Aurora Capacity Units” you would like to have:


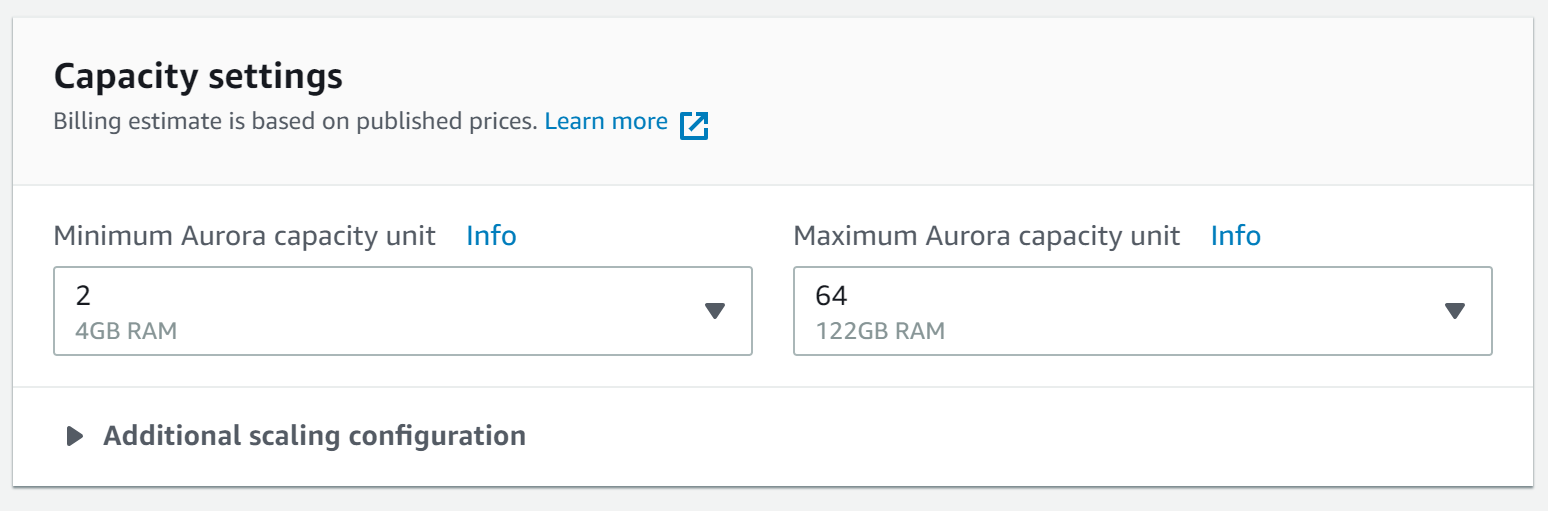
Once you set up such an instance it will automatically scale between its minimum and maximum capacity points. You also will be able to scale it manually if you like.
One of the most interesting Aurora Serverless properties in my opinion is its ability to go into pause if it stays idle for specified period of time.
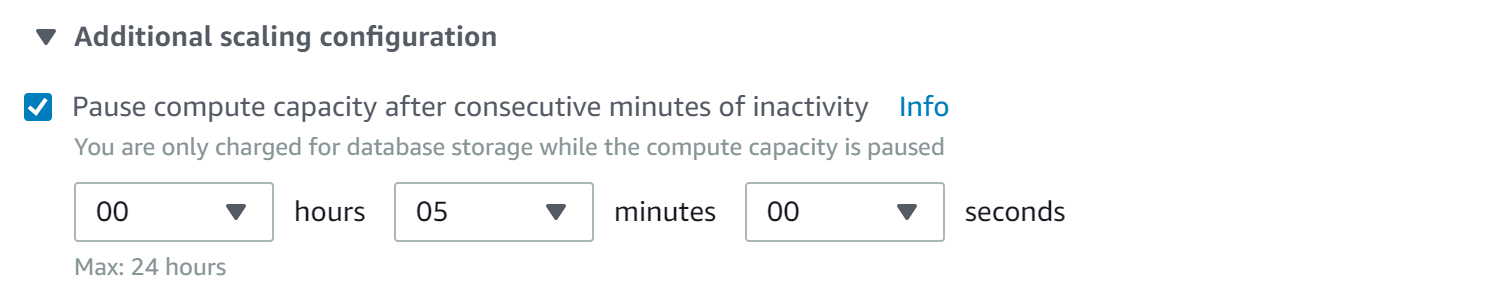
This feature can save a lot of money for test/dev environment where load can be intermittent. Be careful, though, using this for production size databases as waking up is far from instant. I’ve seen cases of it taking over 30 seconds in my experiments.
Another thing which may surprise you about Amazon Aurora Serverless, at the time of this writing, is that it is not very well coordinated with other Amazon RDS Aurora products – it is only available as a MySQL 5.6 based edition and is not compatible with recent parallel query innovations either as it comes with list of other significant limitations. I’m sure Amazon will resolve these in due course, but for now you need to be aware of them.
A simple way to think about it is as follows: Amazon Aurora Serverless is a way to deploy Amazon Aurora so it scales automatically with load; can automatically pause when there is no load; and resume automatically when requests come in.
When I think about Serverless Computing I think about about elastic scalability across multiple servers and resource usage based pricing. DynamoDB, another Database which is advertised as Serverless by Amazon, fits those criteria while Amazon Aurora Serverless does not.
With Amazon Aurora Serverless, for better or for worse, you’re still living in the “classical” instance word. Aurora Capacity Units (ACUs) are pretty much CPU and Memory Capacity. You still need to understand how many database connections you are allowed to have. You still need to monitor your CPU usage on the instance to understand when auto scaling will happen.
Amazon Aurora Serverless also does not have any magic to scale you beyond single instance performance, which you can get with provisioned Amazon Aurora
I’m excited about the new possibilities Amazon Aurora Serveless offers. As long as you do not expect magic and understand this is one of the newest products in the Amazon Aurora family, you surely should give it a try for applications which fit.
If you’re hungry for more information about Amazon Aurora Serverless and can’t wait for the next articles in this series, this article by Jeremy Daly contains a lot of great information.
Resources
RELATED POSTS





Hi Peter,
> Amazon Aurora Serverless also does not have any magic to scale you beyond single instance performance, which you can get with provisioned Amazon Aurora
This point I don’t understand. Is “magically scaling” not exaclty the special feature? The database automatically scales between the minium (1 ACU with 2GB RAM) and the maximum (384 ACU with 768GB RAM). This should automatically scale far beyong a single instance, or do I understand it completely wrong? Thanks!
Best regards,
Theodor