
Following my post from a year ago about ClickHouse I wanted to review what happened in ClickHouse since then. There is indeed some interesting news to share.
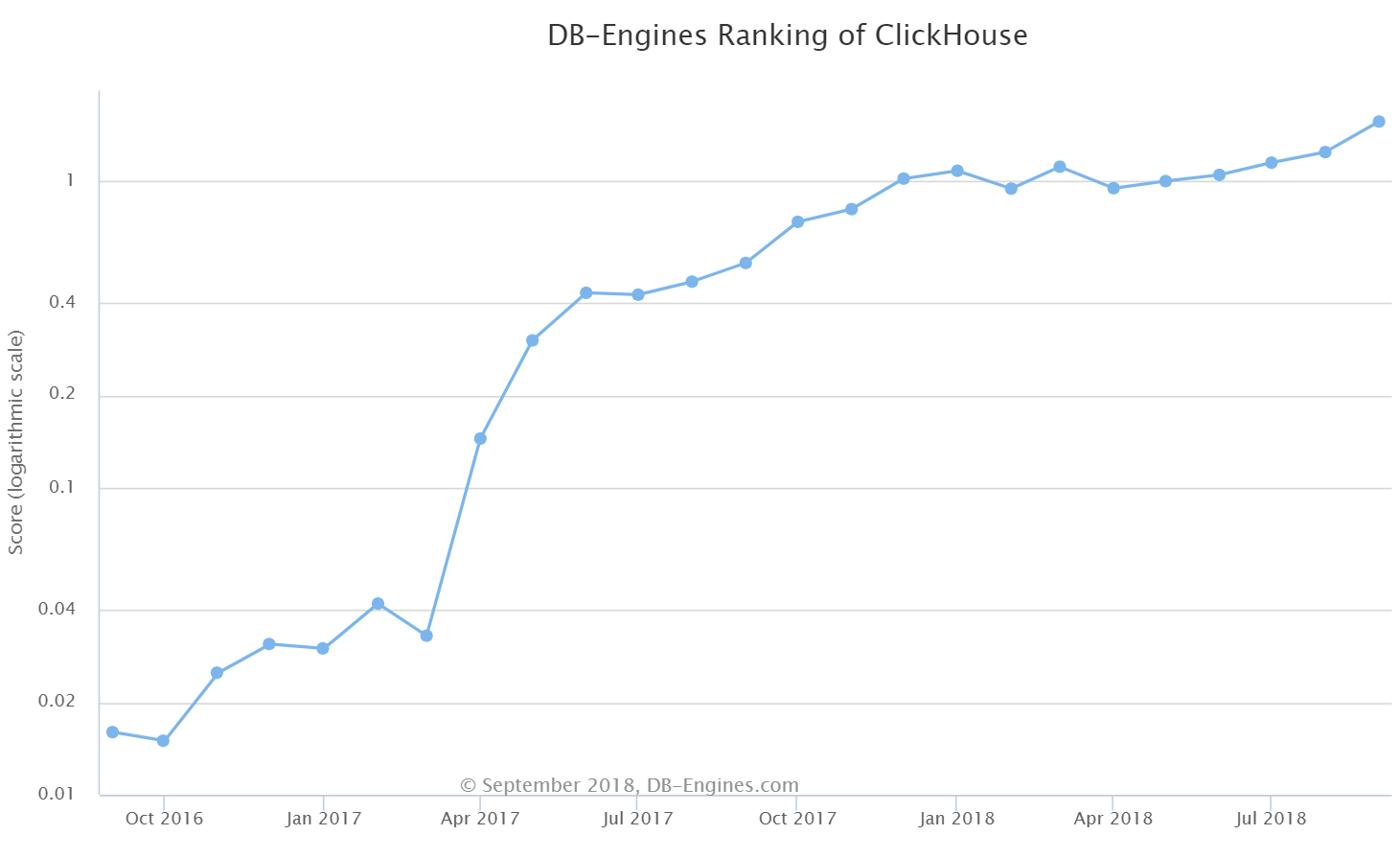
1. ClickHouse in DB-Engines Ranking. It did not quite get into the top 100, but the gain from position 174 to 106 is still impressive. Its DB-Engines Ranking score tripled from 0.54 last September to 1.57 this September
And indeed, in my conversation with customers and partners, the narrative has changed from: “ClickHouse, what is it?” to “We are using or considering ClickHouse for our analytics needs”.
2. ClickHouse changed their versioning schema. Unfortunately, it changed from the unconventional …; 1.1.54390; 1.1.54394 naming structure to the still unconventional 18.6.0; 18.10.3; 18.12.13 naming structure, where “18.” is a year of the release.
Now to the more interesting technical improvements.
3. Support of the more traditional JOIN syntax. Now if you join two tables you can use SELECT ... FROM tab1 ANY LEFT JOIN tab2 ON tab1_col=tab2_col .
So now, if we take a query from the workload described in https://www.percona.com/blog/2017/06/22/clickhouse-general-analytical-workload-based-star-schema-benchmark/
We can write this:
|
1 2 3 4 5 |
SELECT C_REGION, sum(LO_EXTENDEDPRICE * LO_DISCOUNT) FROM lineorder ANY INNER JOIN customer ON LO_CUSTKEY=C_CUSTKEY WHERE (toYear(LO_ORDERDATE) = 1993) AND ((LO_DISCOUNT >= 1) AND (LO_DISCOUNT <= 3)) AND (LO_QUANTITY < 25) GROUP BY C_REGION; |
instead of the monstrous:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT C_REGION, sum(LO_EXTENDEDPRICE * LO_DISCOUNT) FROM lineorder ANY INNER JOIN ( SELECT C_REGION, C_CUSTKEY AS LO_CUSTKEY FROM customer ) USING (LO_CUSTKEY) WHERE (toYear(LO_ORDERDATE) = 1993) AND ((LO_DISCOUNT >= 1) AND (LO_DISCOUNT <= 3)) AND (LO_QUANTITY < 25) GROUP BY C_REGION; |
4. Support for DELETE and UPDATE operations. This has probably been the most requested feature since the first ClickHouse release.
ClickHouse uses an LSM-tree like structure—MergeTree—and it is not friendly to single row operations. To highlight this specific limitation, ClickHouse uses ALTER TABLE UPDATE / ALTER TABLE DELETE syntax to highlight this will be executed as a bulk operation, so please consider it as such. Updating or deleting rows in ClickHouse should be an exceptional operation, rather than a part of your day-to-day workload.
We can update a column like this: ALTER TABLE lineorder UPDATE LO_DISCOUNT = 5 WHERE LO_CUSTKEY = 199568
5. ClickHouse added a feature which I call Dictionary Compression, but ClickHouse uses the name “LowCardinality”. It is still experimental, but I hope soon it will be production ready. Basically it allows internally to replace long strings with a short list of enumerated values.
For example, consider the table from our example lineorder which contains 600037902 rows, but has only five different values for the column LO_ORDERPRIORITY:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT DISTINCT LO_ORDERPRIORITY FROM lineorder ┌─LO_ORDERPRIORITY─┐ │ 1-URGENT │ │ 5-LOW │ │ 4-NOT SPECIFIED │ │ 2-HIGH │ │ 3-MEDIUM │ └──────────────────┘ |
So we can define our table as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE lineorder_dict ( LO_ORDERKEY UInt32, LO_LINENUMBER UInt8, LO_CUSTKEY UInt32, LO_PARTKEY UInt32, LO_SUPPKEY UInt32, LO_ORDERDATE Date, LO_ORDERPRIORITY LowCardinality(String), LO_SHIPPRIORITY UInt8, LO_QUANTITY UInt8, LO_EXTENDEDPRICE UInt32, LO_ORDTOTALPRICE UInt32, LO_DISCOUNT UInt8, LO_REVENUE UInt32, LO_SUPPLYCOST UInt32, LO_TAX UInt8, LO_COMMITDATE Date, LO_SHIPMODE LowCardinality(String) )Engine=MergeTree(LO_ORDERDATE,(LO_ORDERKEY,LO_LINENUMBER),8192); |
How does this help? Firstly, it offers space savings. The table will take less space in storage, as it will use integer values instead of strings. And secondly, performance. The filtering operation will be executed faster.
For example: here’s a query against the table with LO_ORDERPRIORITY stored as String:
|
1 2 3 4 5 6 7 8 9 |
SELECT count(*) FROM lineorder WHERE LO_ORDERPRIORITY = '2-HIGH' ┌───count()─┐ │ 119995822 │ └───────────┘ 1 rows in set. Elapsed: 0.859 sec. Processed 600.04 million rows, 10.44 GB (698.62 million rows/s., 12.16 GB/s.) |
And now the same query against table with LO_ORDERPRIORITY as LowCardinality(String):
|
1 2 3 4 5 6 7 8 9 |
SELECT count(*) FROM lineorder_dict WHERE LO_ORDERPRIORITY = '2-HIGH' ┌───count()─┐ │ 119995822 │ └───────────┘ 1 rows in set. Elapsed: 0.350 sec. Processed 600.04 million rows, 600.95 MB (1.71 billion rows/s., 1.72 GB/s.) |
This is 0.859 sec vs 0.350 sec (for the LowCardinality case).
Unfortunately this feature is not optimized for all use cases, and actually in aggregation it performs slower.
An aggregation query against table with LO_ORDERPRIORITY as String:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT DISTINCT LO_ORDERPRIORITY FROM lineorder ┌─LO_ORDERPRIORITY─┐ │ 4-NOT SPECIFIED │ │ 1-URGENT │ │ 2-HIGH │ │ 3-MEDIUM │ │ 5-LOW │ └──────────────────┘ 5 rows in set. Elapsed: 1.200 sec. Processed 600.04 million rows, 10.44 GB (500.22 million rows/s., 8.70 GB/s.) |
Versus an aggregation query against table with LO_ORDERPRIORITY as LowCardinality(String):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT DISTINCT LO_ORDERPRIORITY FROM lineorder_dict ┌─LO_ORDERPRIORITY─┐ │ 4-NOT SPECIFIED │ │ 1-URGENT │ │ 2-HIGH │ │ 3-MEDIUM │ │ 5-LOW │ └──────────────────┘ 5 rows in set. Elapsed: 2.334 sec. Processed 600.04 million rows, 600.95 MB (257.05 million rows/s., 257.45 MB/s.) |
This is 1.200 sec vs 2.334 sec (for the LowCardinality case)
6. And the last feature I want to mention is the better support of Tableau Software: this required ODBC drivers. It may not seem significant, but Tableau is the number one software for data analysts, and by supporting this, ClickHouse will reach a much wider audience.
Summing up: ClickHouse definitely became much more user-friendly since a year ago!
Resources
RELATED POSTS





Wow, it is moving up the db-engines list fast. Soon it will pass RocksDB.
RocksDB also uses LSM-tree. Why is it more update-friendly than Clickhouse?
Andy,
That’s a complicated question.
In short – RocksDB was designed as a key-value engine, while ClickHouse was designed for the bulk operations.
With this RocksDB performance will be affected if there are multiple updates of a row that are not merged – RockDB will need to find the latest version of the row. By the same reason point selects in RocksDB is not as fast as in InnoDB.
Vadim, thank you for the update, I am a newcomer and an early adopter of Clickhouse. I have had a great experience so far using it locally on a single cluster/machine. Speaking about updates and deletes, in my opinion there should never be the case to implement them in the classic old-fashioned way of RDBMS. Both operations must be implemented with inserts, i.e. a flag to mark delete event, a version to mark updates. It’s just a matter to make it more user friendly for the developers and without compromising on speed.