
One of the common ways to classify database workloads is whether it is “read intensive” or “write intensive”. In other words, whether the workload is dominated by reads or writes.
Why should you care? Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability.
This question looks trivial on the surface, but as you go deeper—complexity emerges. There are different “levels” of reads and writes for you to consider. You can also choose to look at event counts or at the time it takes to do operations. These can provide very different responses, especially as the cost difference between a single read and a single write can be an order of magnitude.
Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench. The illustrations below are taken from Percona Monitoring and Management (PMM) while running this benchmark.

At the highest level, you can think about queries that are sent to the database. In this case we can see about 30K of SELECT queries versus 20K of UPDATE+INSERT queries, making this benchmark slightly more read intensive by this measure.
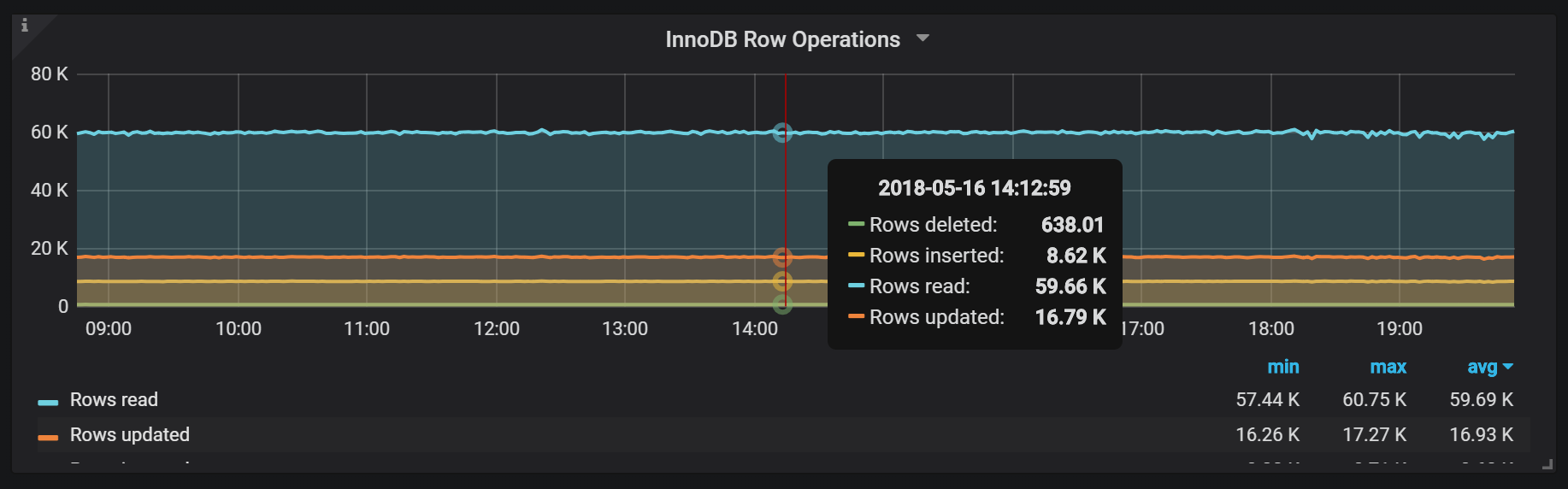
Another way to look at the load is through actual operations at the row level – a single query may touch just one row or may touch millions. In this benchmark the difference between looking at workload from a SQL commands standpoint vs a row operation standpoint yields the same results, but it is not going to always be the case.
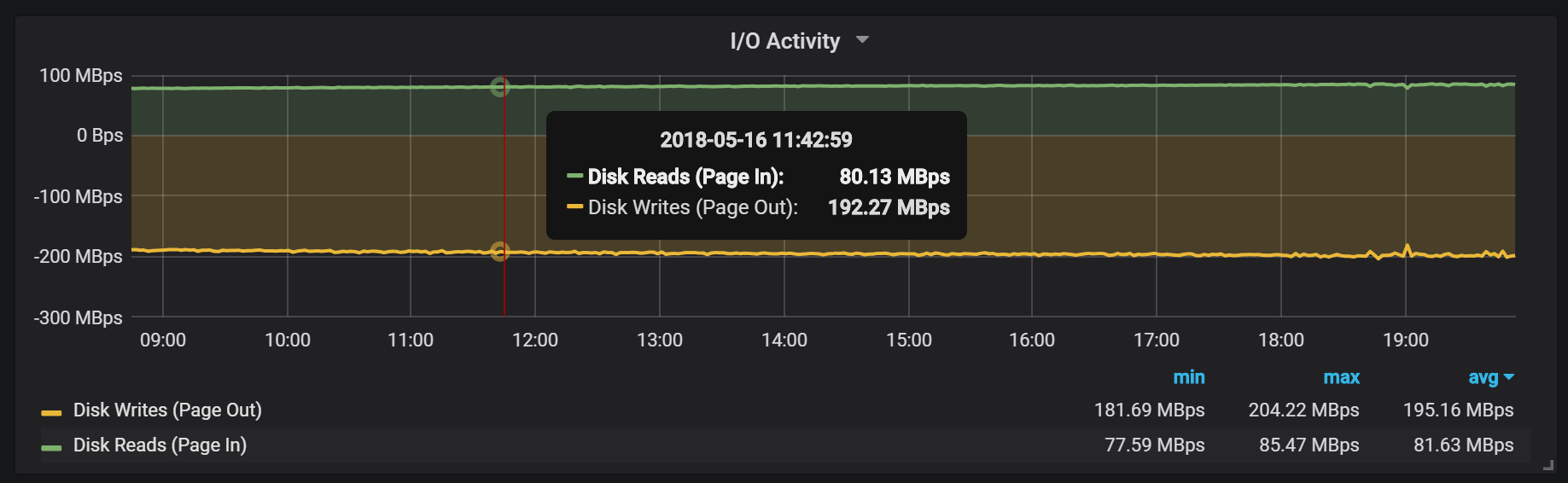
Let’s now look at the operating system level. We can see the amount of data written to the disk is 2x more than the amount of data being read from the disk. This workload is write intensive by this measure.


Yet another way to take a look at your workload is to take a look at it from the aspect of tables. This view shows us that tables are being mostly accessed for reads and writes. This, in turn, allows us to see whether a given table is getting more reads or writes. This is helpful, for example, if you are considering to move some of the tables to a different server and want to clearly understand how your workload will be impacted.
As I mentioned already, the counts often do not reflect the time to respond, which is typically more representative of the real work being done. To look at timing information from query point of view, we want to look at query analytics.
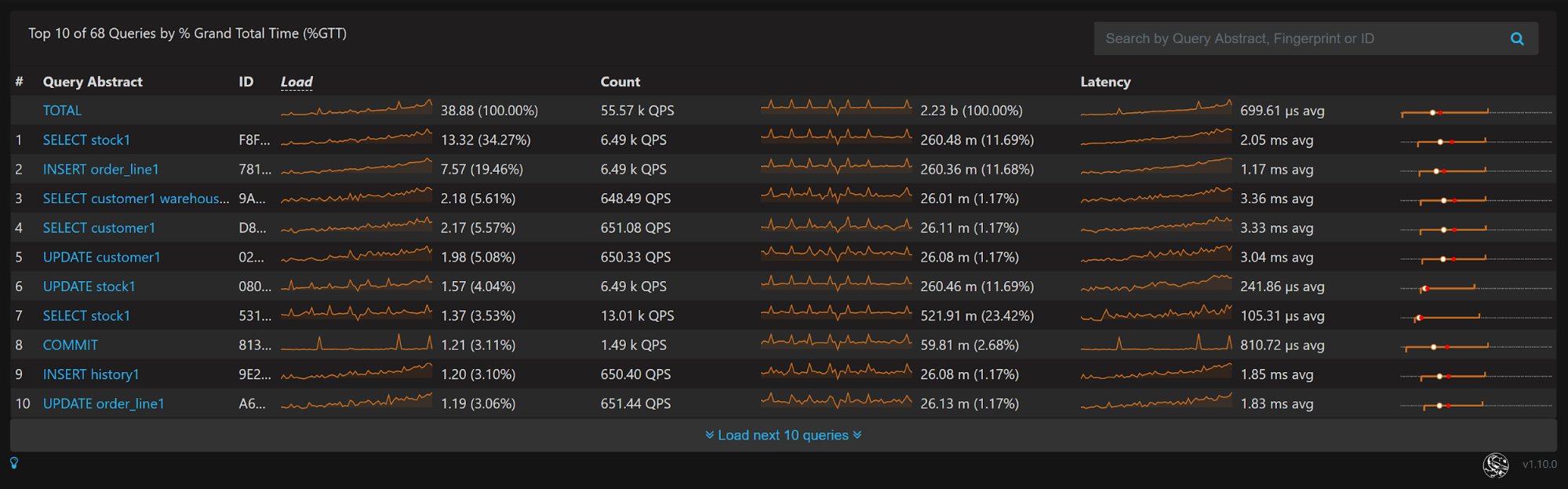
The “Load” column here is a measure of such a combined response time, versus count which is reflective of query counts. Looking at this list we can see that three out of the top five queries are SELECT queries. Looking at the numbers overall, we can see we have a read intensive application from this perspective.
In terms of row level operations, there is currently no easy way to see if reads or writes are dominating overall but you can get an idea from the table operations dashboard:

This shows the load on a per table basis. It labels reads “Fetch” and breaks down writes in more detail—”Update”, “Delete”, “Inserts”—which is helpful. Not all writes are equal either.
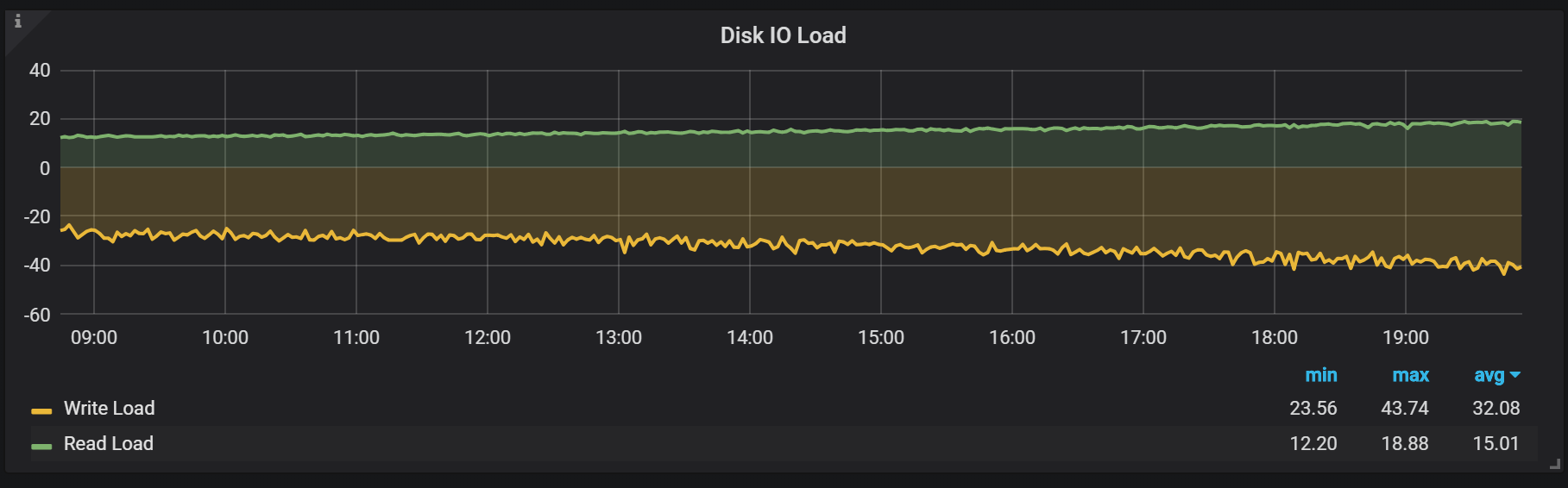
If we want to look at a response time based view of read vs write on an operating system, we can check out this disk IO Load graph. You can see in this case it happens to match the IO activity graph, with storage taking more time to serve write requests versus read requests
As you can see, the question about whether a workload is read intensive or write intensive, while simple on the surface, can have many different answers. You might ask me “OK, so what should I use?” Well… it really depends.
Looking at query counts is a great way to understand the application’s demands on the database—you can’t really do anything to change the database size. However, by changing the database configuration and schema you may drastically alter the impact of these queries, both from the standpoint of the number of rows they crunch and in terms of the disk IO they require.
The response time-based statistics, gathered from the impact your queries cause on the system or disk IO, provide a better representation of the load these queries currently generate.
Another thing to keep in mind—reads and writes are not created equal. My rule of thumb for InnoDB is that a single row write is about 10x more expensive than a single row read.
If you found this post useful, you might also like to see some of Percona’s other resources.
For an introduction to PMM, our free and open source management and monitoring software, you might find value in my recorded webinar, MySQL Troubleshooting and Performance Optimization with PMM.




