
 In this blog post, I’m going to revisit the ProxySQL Query Rewrite feature. You may have seen me talking about possible use case scenarios in the past few conferences, but the reason I’m starting with this is that query rewriting was the original intention for building ProxySQL.
In this blog post, I’m going to revisit the ProxySQL Query Rewrite feature. You may have seen me talking about possible use case scenarios in the past few conferences, but the reason I’m starting with this is that query rewriting was the original intention for building ProxySQL.
Why would you need to rewrite a query?
So here we have a case of a bad query hitting the backend database. You as a DBA have identified the query as causing severe slowdown, which could lead to a site-wide outage. This query needs to be optimized, and you have asked the developer to correct this bad query. Their answer isn’t really what you expected. You can rewrite some queries to have the same data result by choosing a different optimizer path. In cases where an application was written in ORM – such as Hibernate or similar – it is not easy to quickly make a code change.
The query rewrite feature of ProxySQL makes this possible (until the application can be modified).
How do we rewrite a query? There are two ways to accomplish this with ProxySQL.
Query rewrite is just a match_pattern + replace_pattern activity, whereas match_digest is only used for matching a query, not rewriting it. Logically, match_digest serves the same purpose of username, schemaname, proxy_addr, etc. It only matches the query.
These two different mechanisms offers ways to optimize query matching operation efficiently depending on the query type (such as DML operation versus SELECT query). Please note that if your intention is to rewrite queries, the rule must match the original query by using match_pattern. Query rules are processed by using rule_id field and only applied if active = 1.
Here’s how we can demonstrate match_digest in our test lab:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
mysql> SELECT hostgroup hg, sum_time, count_star, digest_text FROM stats_mysql_query_digest ORDER BY sum_time DESC limit 10; +----+-----------+------------+-----------------------------------+ | hg | sum_time | count_star | digest_text | +----+-----------+------------+-----------------------------------+ | 0 | 243549572 | 85710 | SELECT c FROM sbtest10 WHERE id=? | | 0 | 146324255 | 42856 | COMMIT | | 0 | 126643488 | 44310 | SELECT c FROM sbtest7 WHERE id=? | | 0 | 126517140 | 42927 | BEGIN | | 0 | 123797307 | 43820 | SELECT c FROM sbtest1 WHERE id=? | | 0 | 123345775 | 43460 | SELECT c FROM sbtest6 WHERE id=? | | 0 | 122121030 | 43010 | SELECT c FROM sbtest9 WHERE id=? | | 0 | 121245265 | 42400 | SELECT c FROM sbtest8 WHERE id=? | | 0 | 120554811 | 42520 | SELECT c FROM sbtest3 WHERE id=? | | 0 | 119244143 | 42070 | SELECT c FROM sbtest5 WHERE id=? | +----+-----------+------------+-----------------------------------+ 10 rows in set (0.00 sec) mysql> INSERT INTO mysql_query_rules (rule_id,active,username,match_digest, match_pattern,replace_pattern,apply) VALUES (10,1,'root','SELECT.*WHERE id=?','sbtest2','sbtest10',1); Query OK, 1 row affected (0.00 sec) mysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.00 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | 0 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 1 | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ 1 row in set (0.00 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | 593 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 1 | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ 1 row in set (0.00 sec) |
We can also monitor Query Rules activity live using the ProxyTop utility:
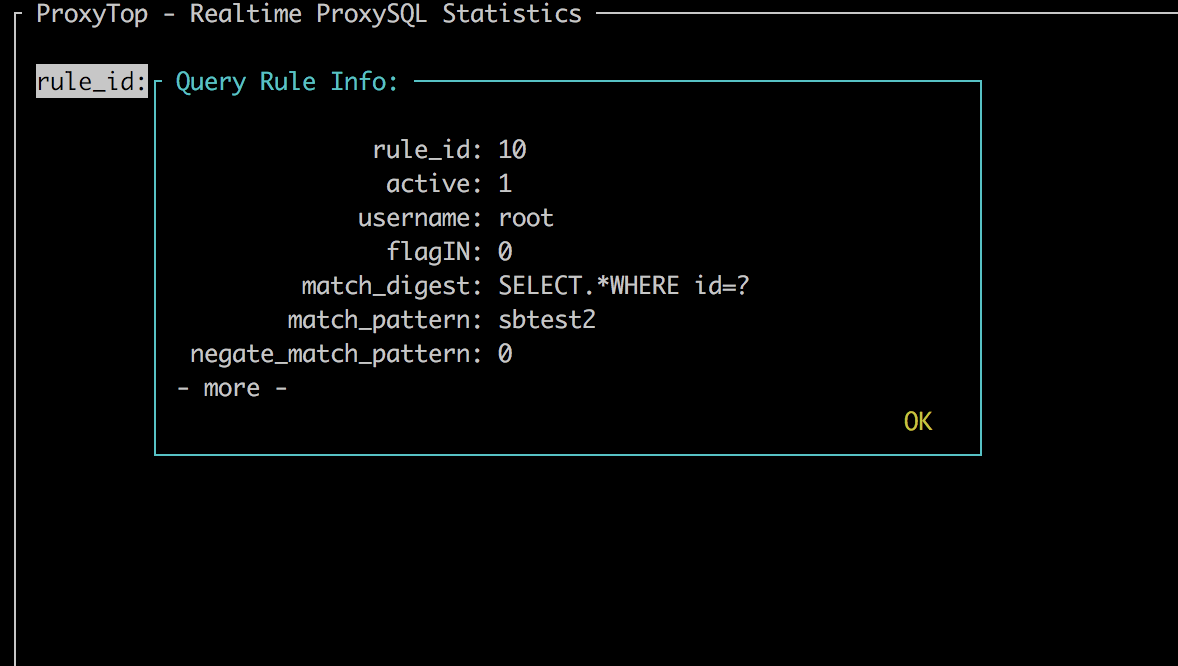
To reset ProxySQL’s statistics for query rules, use following steps:
|
1 2 3 4 5 6 7 8 9 10 |
mysql> SELECT 1 FROM stats_mysql_query_digest_reset LIMIT 1; +---+ | 1 | +---+ | 1 | +---+ 1 row in set (0.01 sec) mysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.00 sec) |
Here’s a match_pattern example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
mysql> SELECT hostgroup hg, sum_time, count_star, digest_text FROM stats_mysql_query_digest ORDER BY sum_time DESC limit 5; +----+----------+------------+----------------------------------+ | hg | sum_time | count_star | digest_text | +----+----------+------------+----------------------------------+ | 0 | 98753983 | 16292 | BEGIN | | 0 | 84613532 | 16232 | COMMIT | | 1 | 49327292 | 16556 | SELECT c FROM sbtest3 WHERE id=? | | 1 | 49027118 | 16706 | SELECT c FROM sbtest2 WHERE id=? | | 1 | 48095847 | 16396 | SELECT c FROM sbtest4 WHERE id=? | +----+----------+------------+----------------------------------+ 5 rows in set (0.01 sec) mysql> INSERT INTO mysql_query_rules (rule_id,active,username,match_pattern,replace_pattern,apply) VALUES (20,1,'root','DISTINCT(.*)ORDER BY c','DISTINCT1',1); Query OK, 1 row affected (0.00 sec) mysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.01 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ | 0 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 1 | | 0 | 20 | NULL | 1 | root | NULL | DISTINCT(.*)ORDER BY c | DISTINCT1 | NULL | 1 | +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ 2 rows in set (0.01 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ | 9994 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 1 | | 6487 | 20 | NULL | 1 | root | NULL | DISTINCT(.*)ORDER BY c | DISTINCT1 | NULL | 1 | +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ 2 rows in set (0.00 sec) mysql> SELECT 1 FROM stats_mysql_query_digest_reset LIMIT 1; +---+ | 1 | +---+ | 1 | +---+ 1 row in set (0.00 sec) mysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.00 sec) |
The key in query ruling for a rewrite is the order of the apply field:
As we can see in the test below, all queries matching with rule_id = 10 or rule_id = 20 have hits. In reality, all rules in runtime_mysql_query_rules are active. If we want to disable a rule that is in the mysql_query_rules table, set active = 0:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
mysql> update mysql_query_rules set apply = 1 where rule_id in (10); Query OK, 1 row affected (0.00 sec) mysql> update mysql_query_rules set apply = 0 where rule_id in (20); Query OK, 1 row affected (0.00 sec) mysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.00 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ | 0 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 1 | | 0 | 20 | NULL | 1 | root | NULL | DISTINCT(.*)ORDER BY c | DISTINCT1 | NULL | 0 | +------+---------+--------+--------+----------+--------------------+------------------------+-----------------+-----------+-------+ 2 rows in set (0.00 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, flagIN, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +-------+---------+--------+--------+----------+--------------------+------------------------+-----------------+--------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | flagIN | apply | +-------+---------+--------+--------+----------+--------------------+------------------------+-----------------+--------+-------+ | 10195 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | 0 | 1 | | 6599 | 20 | NULL | 1 | root | NULL | DISTINCT(.*)ORDER BY c | DISTINCT1 | 0 | 0 | +-------+---------+--------+--------+----------+--------------------+------------------------+-----------------+--------+-------+ 2 rows in set (0.00 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, flagIN, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +-------+---------+--------+--------+----------+--------------------+------------------------+-----------------+--------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | flagIN | apply | +-------+---------+--------+--------+----------+--------------------+------------------------+-----------------+--------+-------+ | 20217 | 5 | NULL | 1 | root | NULL | DISTINCT(.*)ORDER BY c | DISTINCT1 | 0 | 1 | | 27020 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | 0 | 0 | +-------+---------+--------+--------+----------+--------------------+------------------------+-----------------+--------+-------+ 2 rows in set (0.00 sec) mysql> update mysql_query_rules set active = 0 where rule_id = 5; Query OK, 1 row affected (0.00 sec) mysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.02 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | 0 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 0 | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ 1 row in set (0.00 sec) mysql> SELECT hits, mysql_query_rules.rule_id,digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id; +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | hits | rule_id | digest | active | username | match_digest | match_pattern | replace_pattern | cache_ttl | apply | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ | 4224 | 10 | NULL | 1 | root | SELECT.*WHERE id=? | sbtest2 | sbtest10 | NULL | 0 | +------+---------+--------+--------+----------+--------------------+---------------+-----------------+-----------+-------+ 1 row in set (0.01 sec) |
Additionally, ProxySQL can help to identify bad queries. Login to the admin module and follow these steps:
Find the most time-consuming queries:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> SELECT SUM(sum_time), SUM(count_star), digest_text FROM stats_mysql_query_digest GROUP BY digest ORDER BY SUM(sum_time) DESC LIMIT 3G *************************** 1. row *************************** SUM(sum_time): 95053795 SUM(count_star): 13164 digest_text: BEGIN *************************** 2. row *************************** SUM(sum_time): 85094367 SUM(count_star): 13130 digest_text: COMMIT *************************** 3. row *************************** SUM(sum_time): 52110099 SUM(count_star): 13806 digest_text: SELECT c FROM sbtest3 WHERE id=? 3 rows in set (0.00 sec) |
Find highest average execution time:
|
1 2 3 4 5 6 7 |
mysql> SELECT SUM(sum_time), SUM(count_star), SUM(sum_time)/SUM(count_star) avg, digest_text FROM stats_mysql_query_digest GROUP BY digest ORDER BY SUM(sum_time)/SUM(count_star) DESC limit 1; +---------------+-----------------+--------+--------------------------------+ | SUM(sum_time) | SUM(count_star) | avg | digest_text | +---------------+-----------------+--------+--------------------------------+ | 972162 | 1 | 972162 | CREATE INDEX k_5 ON sbtest5(k) | +---------------+-----------------+--------+--------------------------------+ 1 row in set (0.00 sec) |
The above information can also be gathered from information_schema.events_statements_summary_by_digest, but I prefer the ProxySQL admin interface. Also, you can run the slow query log analysis by running a detailed pt-query-digest on your system to identify slow queries. You can also use PMM’s QAN.
Conclusion
I’ve found the best documentation on ProxySQL query rewrite is at IBM’s site, where they explain query rewrite fundamentals with examples. It’s worth a read. I’m not going to get into the details of these techniques here, but if you find more relevant resources, please post them in the comments section.
A few of the possible query optimization techniques:
At the time of this blog post, ProxySQL has also announced a new fast schema routing algorithm to support thousands of shards.
There may be other cases where you want to divert traffic to another table. Think of a table hitting the maximum integer value, and you want to keep inserts going into a new table while you alter the old one to correct the issue. In the mean time, all selects can still point to the old table to continue operation.
As of MySQL 5.7.6, Oracle also offers query rewrite as a plugin, and you can find the documentation here. The biggest disadvantage of using Oracle’s built-in solution is the rewrite rule sits with the server it is implemented on. That’s where ProxySQL has a bigger advantage: it sits between the application and database server, so the rule applies to the entire topology, not just for a single host.
As you can see, ProxySQL query rewrite is a great way to solve some real operational issues and make you a hero to the team and project. To become a rock star, you might want to consider Percona Training on ProxySQL. The training will provide the knowledge to set up a ProxySQL environment with best practices, understand when and how to change the configuration, and maintain it to ensure increasing your uptime SLAs. Contact us for more details at [email protected].
References:
https://www.percona.com/blog/2017/04/10/proxysql-rules-do-i-have-too-many/
http://www.proxysql.com/blog/query-rewrite-with-proxysql-use-case-scenario
https://github.com/sysown/proxysql/wiki/ProxySQL-Configuration#query-rewrite
https://dev.mysql.com/doc/refman/5.7/en/rewriter-query-rewrite-plugin.html





I’ve never had the proper time to play around with/implement proxysql since I first heard of it, but I always thought the following would be a good way to deal with query rewrites. Wonder what you think.
– Have application insert in-line comment with unique identifier into all queries sent from application, preferably at or near the front of the query. A decent example, and potentially automated would be an identifier of the filename and line #.
– When it is found that query needs rewriting, base your match pattern on the unique identifier.
This allows you to simply match on that unique identifier and then rewrite the rest of the query without hassle. You wouldn’t have to worry about similar queries that you do not want to rewrite, or that may match your non unique identifier. I haven’t tested it, but I do think it would work. I know there is a –comments option for the mysql command line tool that allows you to see such comments. I assume proxy sql can see the comments as well.
That sounds like a great idea, for (non-framework or) non-ORM applications. Sadly, to use it with most (frameworks or) ORMs (e.g.: Hibernate, Doctrine) would require modifying the ORM code, and probably the API (to pass in data on which to base the unique ID). In C, it could be done without modifying the API (using macros), but in a more “modern” language, it’s a much harder problem. (You _could_ look at the calling stack, but that’s painfully slow in the languages I’m familiar with.)