
In this blog post we are going to take a closer look at ProxySQL rules. How do they work, and how big is the performance impact of having many rules?
I would like to say thank you to Renè, who was willing to answer all my questions during my tests.
ProxySQL is heavily based on the query rules. We can set up ProxySQL without rules based only on the host groups, but if we want read/write splitting or sharding (or anything else) we need rules.
ProxySQL knows the SQL protocol and language, so we can easily create rules based on username, schema name and even on the query itself. We can write regular expressions that match the query digest. Let me show you an example:
|
1 |
insert into mysql_query_rules (username,destination_hostgroup,active,retries,match_digest) values('Testuser',601,1,3,'^SELECT'); |
This rule matches all the queries starting with “SELECT”, and sends them to host group 601.
After version 1.3.1, the default regex engine was RE2. Starting after version 1.4, the default regex engine will be PCRE.
I would like to highlight three options that can have a bigger impact on your rules than you think: flagIN, flagOUT, apply.
With regards to the manual:
. . .these allow us to create “chains of rules” that get applied one after the other. An input flag value is set to 0, and only rules with flagIN=0 are considered at the beginning. When a matching rule is found for a specific query, flagOUT is evaluated and if NOT NULL the query will be flagged with the specified flag in flagOUT. If flagOUT differs from flagIN, the query will exit the current chain and enters a new chain of rules having flagIN as the new input flag. If flagOUT matches flagIN, the query will be re-evaluated again against the first rule with said flagIN. This happens until there are no more matching rules, or apply is set to 1 (which means this is the last rule to be applied)
You might not be sure what this means, but I will show you later.
As you can see, adding a rule is easy and we can add hundreds of rules, But is there any performance impact?
We can write rules based on any part of the query (for example, “userid” or some “sharding key”). In these tests I wrote the rules based on table names because I can easily generate tables with “sysbench”, and run queries against these tables.
I created 1000 tables using sysbench, and I am going to test them with a direct MySQL connection, ProxySQL without rules, with ten rules and with 100 rules.
Time to do some tests to see if adding 100 or more rules have any effect on the performance?
I used two c4.4xlarge instances with SSDs, and I am going to share the steps so anybody can repeat my test and share/compare the results. NodeA is running MySQL 5.7.17 server, and NodeB is running “ProxySQL 1.3.4: and sysbench. During the test I increased the sysbench threads in the following steps:1,2,4,8,12,16,20,24.
I tried to use the simplest ProxySQL configuration as possible:
|
1 2 3 4 5 6 |
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('10.10.10.243',600,3306,1000,0); INSERT INTO mysql_replication_hostgroups VALUES (600,'',''); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK; insert into mysql_users (username,password,active,default_hostgroup,default_schema) values ('testuser_rw','Testpass1.',1,600,'test'); LOAD MYSQL USERS TO RUNTIME;SAVE MYSQL USERS TO DISK; |
Only one server, one host group. I tried to measure the impact the rules had, so in all the test I sent the queries to the same host group. I only changed the rules (and some ProxySQL settings, as I will explain later).
As I mentioned, I am going to filter based on table names. Here are the 100 rules that I used:
|
1 2 3 |
insert into mysql_query_rules (username,destination_hostgroup,active,retries,match_digest) values('testuser_rw',600,1,3,'(from|into|update|into table) sbtest1b'); insert into mysql_query_rules (username,destination_hostgroup,active,retries,match_digest) values('testuser_rw',600,1,3,'(from|into|update|into table) sbtest2b'); ... insert into mysql_query_rules (username,destination_hostgroup,active,retries,match_digest) values('testuser_rw',600,1,3,'(from|into|update|into table) sbtest100b');First Test |
First I ran tests with a direct MySQL connection, ProxySQL without rules, ProxySQL with ten rules and ProxySQL with 100 rules.
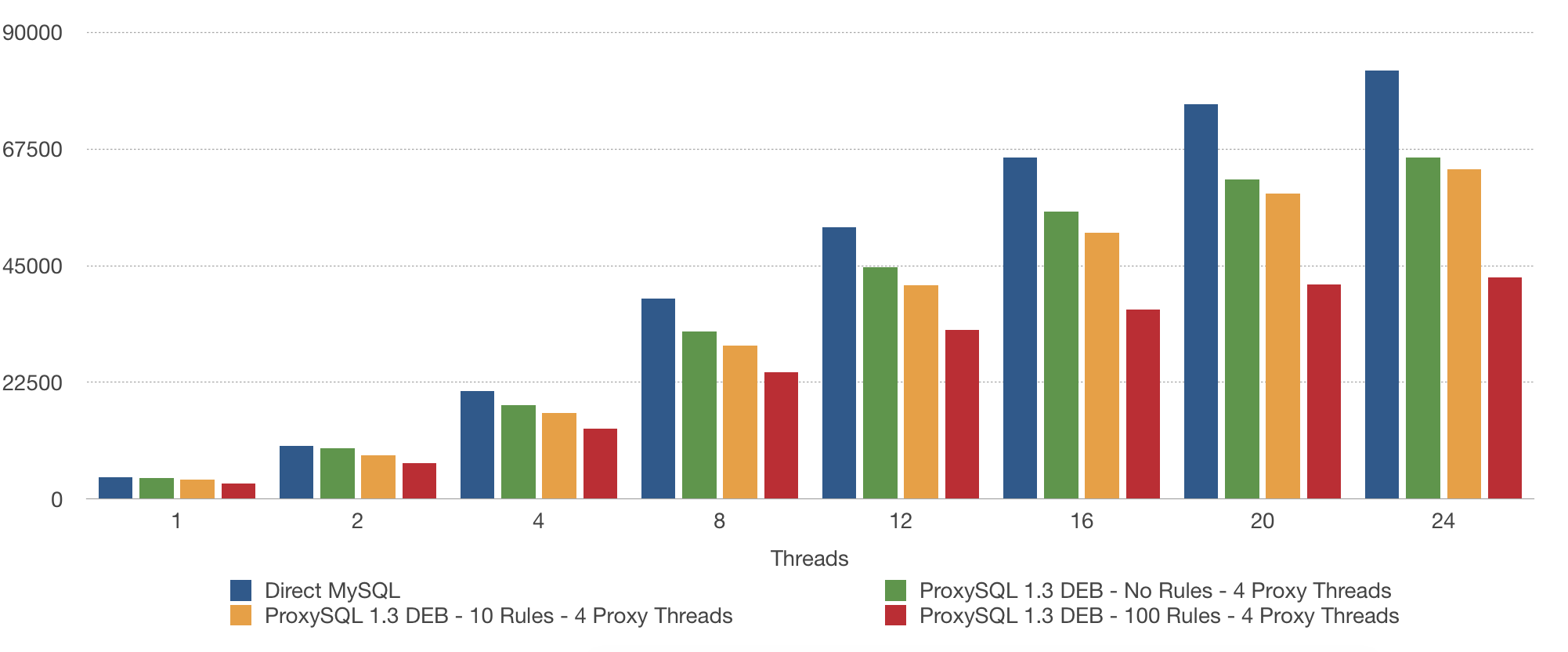
ProxySQL itself has an impact on the performance, but there is a big difference between 10 and 100 rules. So adding more and more rules can have a negative effect on the performance.
That’s all? Can we do anything to speed things up? I used the default ProxySQL settings. Let’s have a look what can we tune.
Let’s go step by step. First we can increase the thread number inside ProxySQL (the default is 4). We will increase it to 8:
|
1 2 |
UPDATE global_variables SET variable_value='8' WHERE variable_name='mysql-threads'; SAVE MYSQL VARIABLES TO DISK; |
ProxySQL has to be restarted after this changes.
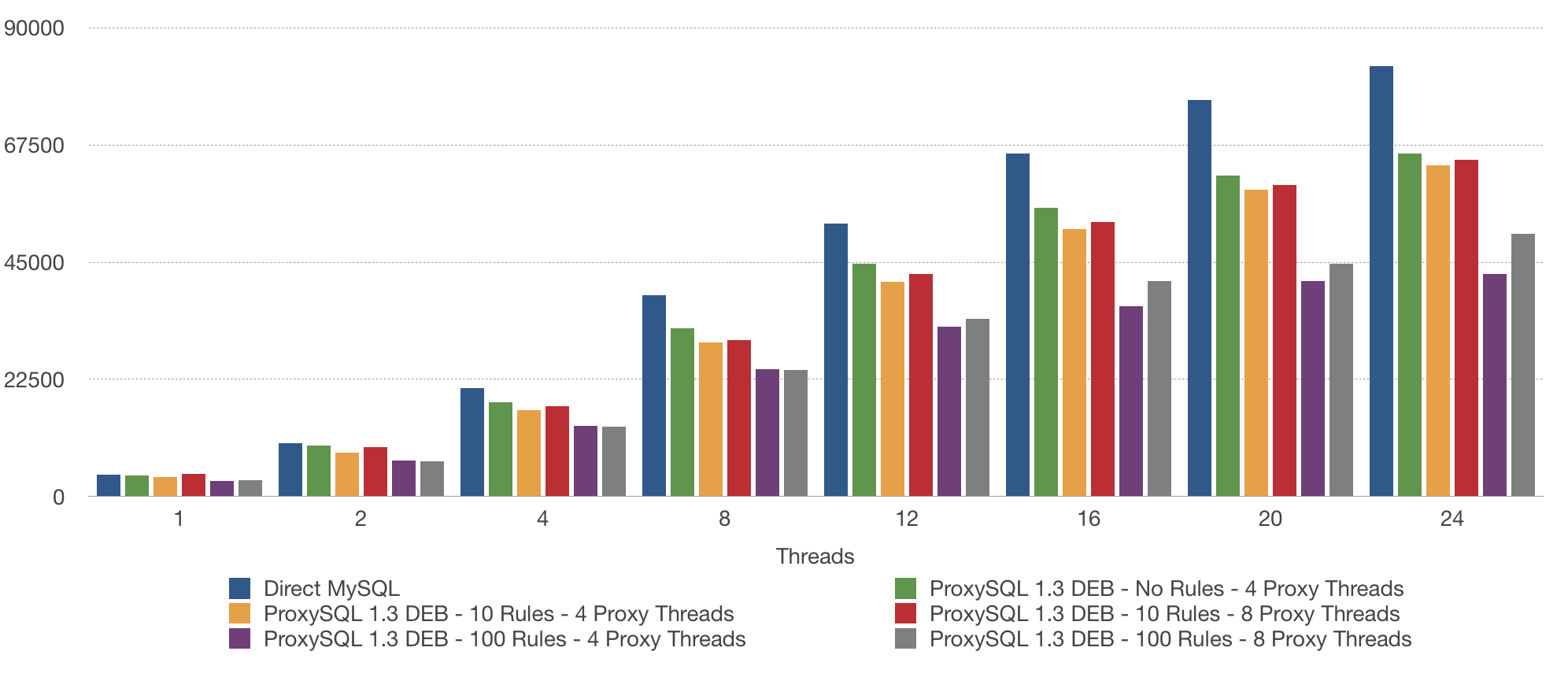
With this simple changes, we can improve the performance. As we can see, the difference is getting larger and larger as we increase the number of the sysbench threads.
By compiling our own package, we can gain some extra performance. It is not clear why, so we opened a ticket for further investigation:
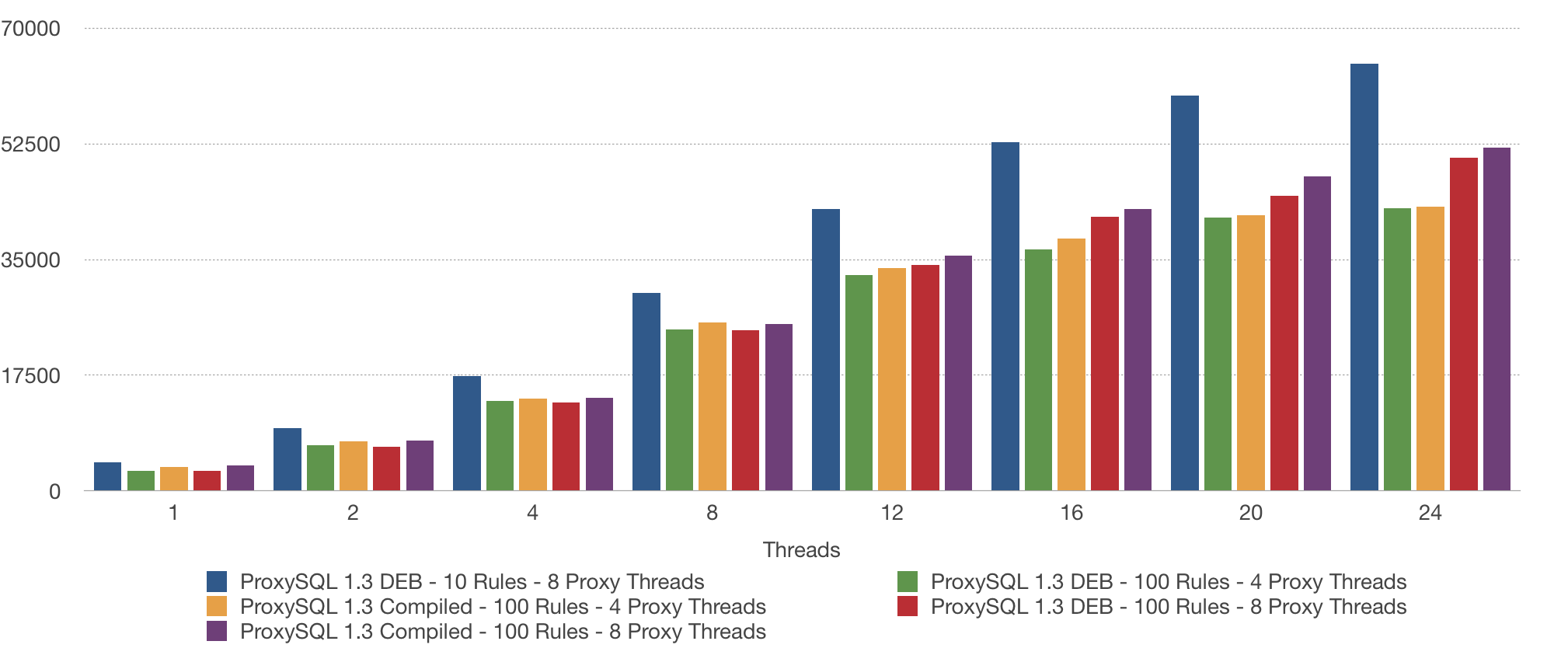
I removed some of the columns because the graph got to busy.
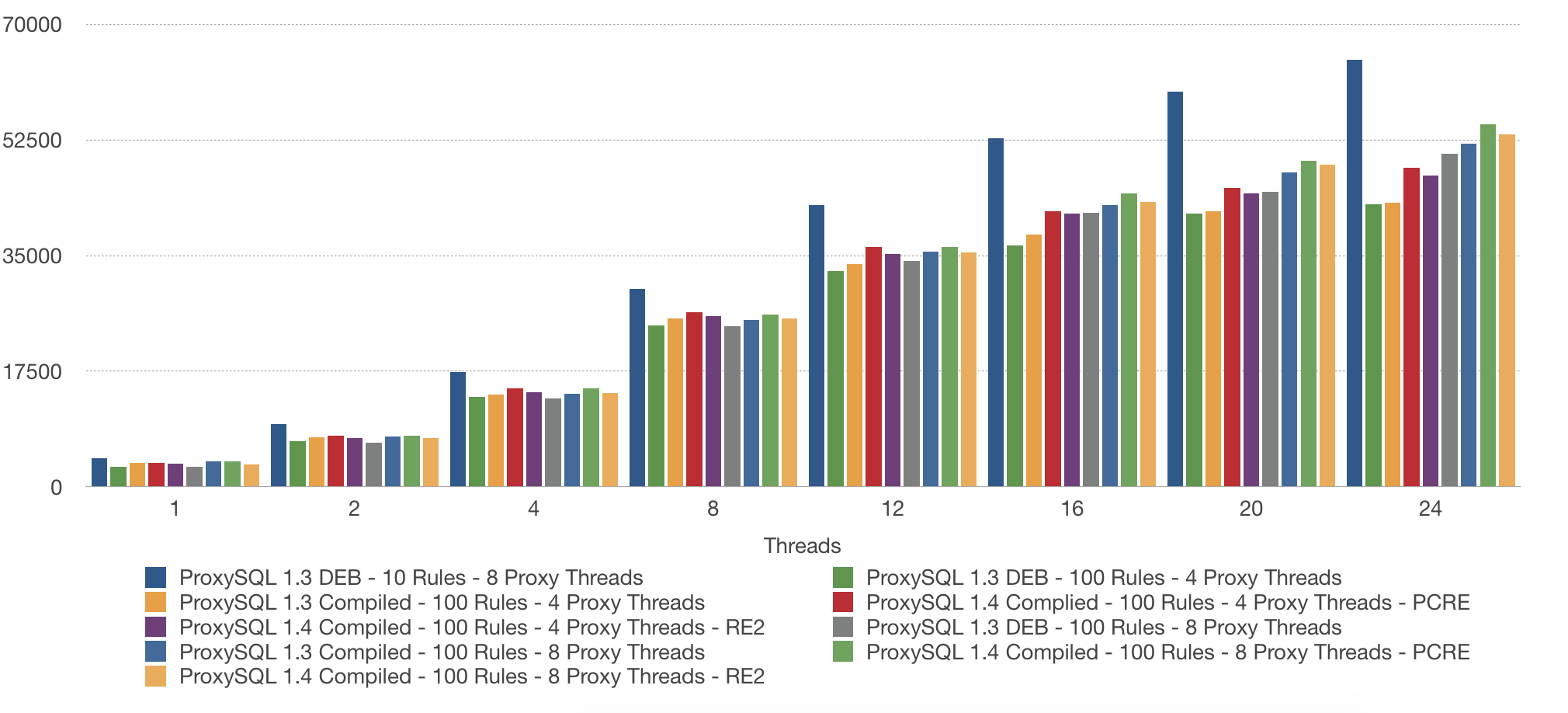
In ProxySQL 1.4 (which is not GA yet), we can change between the regex engines. However, even using the same engine (RE2) is faster in 1.4:
As I mentioned, ProxySQL has a few important parameters like “apply”. With apply, if the query matches a rule it won’t check the remaining rules. In an ideal world, if you have 100 rules and 100 queries in random order which match only one rule, you only have to check 50 rules on average.
The new rules:
|
1 |
insert into mysql_query_rules (username,destination_hostgroup,active,retries,match_digest,apply) values('testuser_rw',600,1,3,'(from|into|update|into table) sbtest1b',1); |
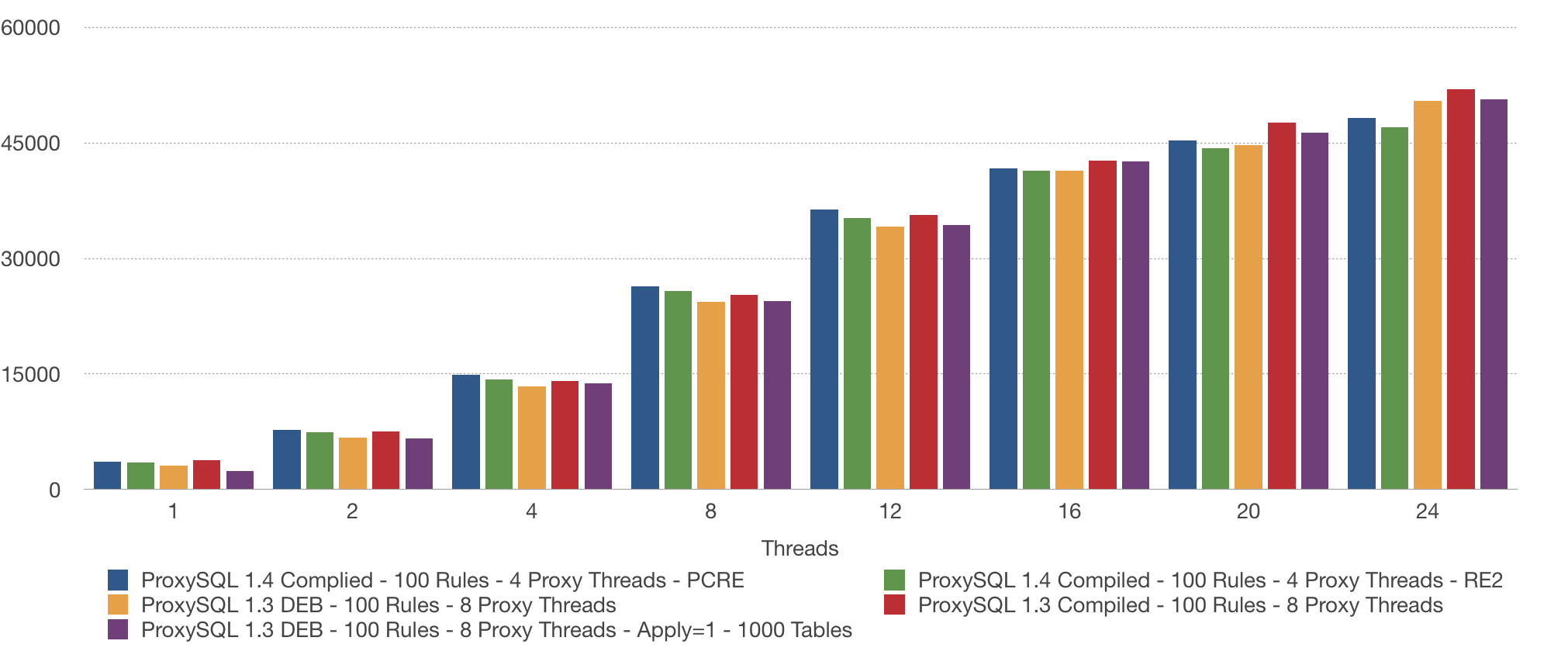
As you can see it didn’t help at all. But why? Because in this test we have 1000 tables, and we are running queries on all of the tables. This means 90% the queries have to check all the rules anyway. Let’s make a test with 100 tables to see if the “apply” helps or not:
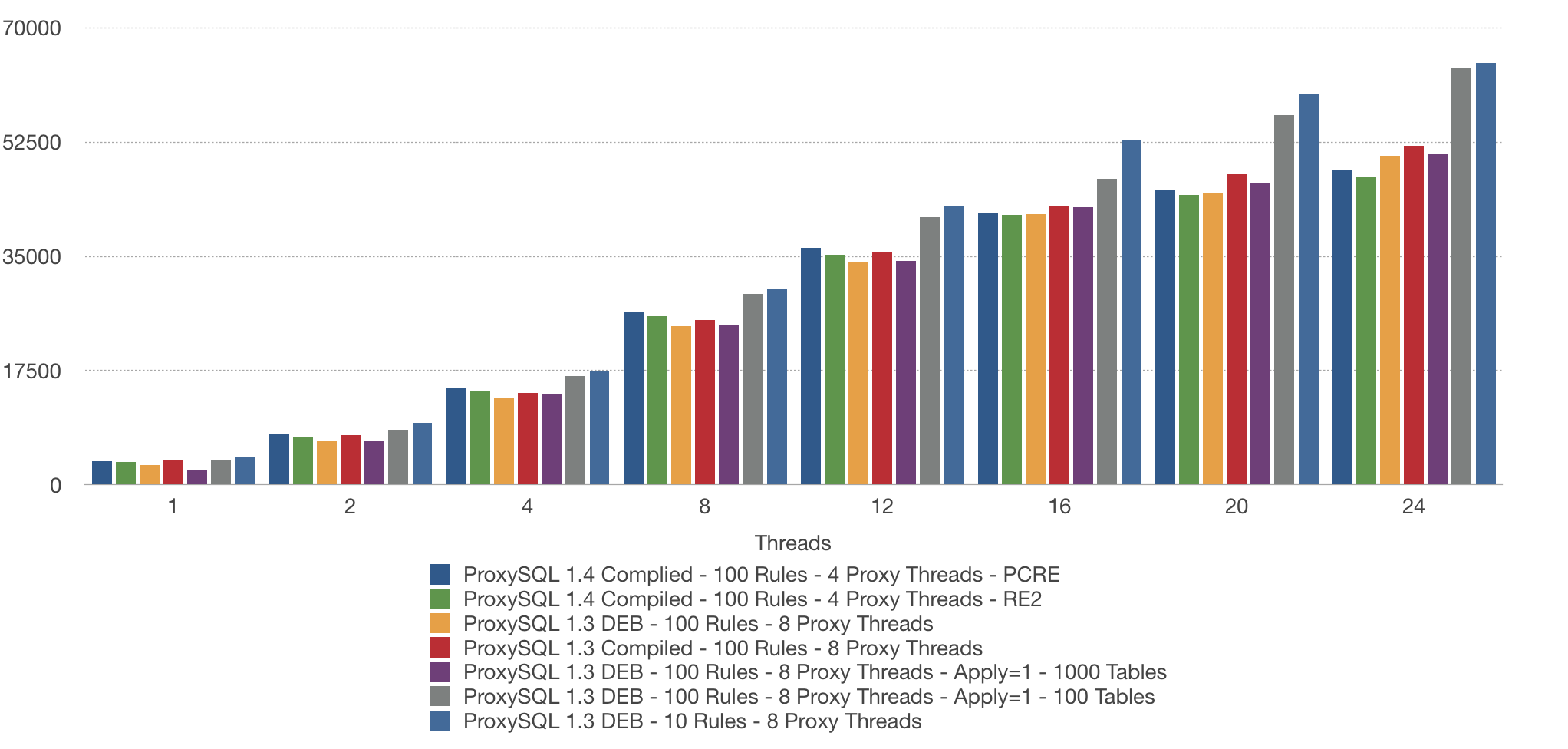
As we can see, with 100 tables we get a much better performance. But of course this is not a valid solution because we can’t just drop tables, “userids” or “sharding keys”. In the next post I will show you how to use “apply” in a more effective way.
So far, ProxySQL 1.4 with the PCRE engine and eight threads gives us the best performance with 100 rules and 1000 tables. As we can see, both the number of the rules and the query distribution matter. Both impact the performance. In my next blog post, I will show you how you can add some logic into your rules so that, even if you have more rules, you will get better performance.





It would be interesting if proxysql kept stats on how many # of pattern matches and tried the higher # patterns first.
Have you every test performance between
match_digestandmatch_pattern? I just wonder caculate every queries digest have great impact.Query digest is helpfull to query statistics. But if I chase the performance, it can’t be turn off to just use
match_pattern.Processing query digest has a performance impact, but it is a very important element. In fact, without processing the query digest, ProxySQL won’t be able to understand when it has to automatically disable multiplexing, for example in case of user variables, temporary tables, lock tables, flush tables with read lock, get_lock() , etc etc).
If you disable query digest, performance will improve but ProxySQL won’t be smart to understand when it is safe or unsafe to use multiplexing.
Query digest can be disabled (although I recommend not to, for the reasons explained above): it is enough to set mysql-query_digests=’false’ .
If the digest is available (and I would like to repeat, I recommend to not disable it), matching against the digest is normally faster then matching against the original query, for two reasons:
a) the digest of a query is normally smaller than the original query, therefore the regex engine may have less data to process
b) it the pattern to match should exclude the parameters, the regex will be way more complex.
About b) , you would need to write very complex regex to NOT match this query:
SELECT * FROM randomtable WHERE comment LIKE ‘%INTO sbtest1 % FROM sbtest2 %’
Of course, if your query rules has to match against literals/parameters (for example, if you want to block a specific userid) you must use match_pattern and not match_digest
I was just trying to understand the usecase of flagin, flagout & apply. As the explanation is not easy for a newbie to understand. Can you please help me here?
Also, I’m trying to mask an entire table containing my user_data from the developers. Any wildcard query rules to mask an entire table?