
In this blog post, we’ll look at the performance of multi-source replication with GTID.
Note. This blog was edited as I received some comments from Percona colleagues. I’ve updated the contents in the marked EDIT section. Thanks!
Multi-Source Replication is a topology I’ve seen discussed recently, so I decided to look into how it performs with the different replication concepts. Multi-source replication use replication channels, which allow a slave to replicate from multiple masters. This is a great way to consolidate data that has been sharded for production or simplify the analytics process by using the same server. Since multiple masters are taking writes, care is needed to not overlook the slave. The traditional replication concept uses the binary log file name, and the position inside that file.
This was the standard until the release of global transaction identifiers (GTID). I have set up a test environment to validate which concept would perform better, and be a better choice for use in this topology.
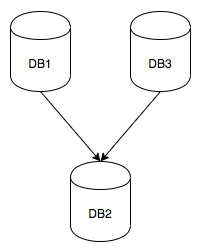
My test suite is rather simple, consisting of only three virtual machines, two masters and one slave. The slaves’ replication channels are set up using the same concept for each run, and no run had any replication filters. To prevent any replication errors, each master took writes against a different schema and user grants are identical on all three servers. The setup below ran with both replication channels using binary log file and position. Then the tables were dropped and the servers changed to use GTID for the next run.
Prepare the sysbench tables:
|
1 2 |
sysbench --db-driver=mysql --mysql-user= --mysql-password='' --mysql-db=db1 --range_size=100 --table_size=1000000 --tables=5 --threads=5 --events=0 --rand-type=uniform /usr/share/sysbench/oltp_read_only.lua prepare sysbench --db-driver=mysql --mysql-user= --mysql-password='' --mysql-db=db3 --range_size=100 --table_size=1000000 --tables=5 --threads=5 --events=0 --rand-type=uniform /usr/share/sysbench/oltp_read_only.lua prepare |
I used a read-only sysbench to warm up the InnoDB buffer pool. Both commands ran on the slave to ensure both schemas were loaded into the buffer pool:
|
1 2 |
sysbench --db-driver=mysql --mysql-user= --mysql-password='' --mysql-db=db1 --range_size=100 --table_size=1000000 --tables=5 --threads=5 --events=0 --time=3600 --rand-type=uniform /usr/share/sysbench/oltp_read_only.lua run sysbench --db-driver=mysql --mysql-user= --mysql-password='' --mysql-db=db3 --range_size=100 --table_size=1000000 --tables=5 --threads=5 --events=0 --time=3600 --rand-type=uniform /usr/share/sysbench/oltp_read_only.lua run |
After warming up the buffer pool, the slave should be fully caught up with both masters. To remove IO contention as a possible influencer, I stopped the SQL thread while I generated load on the master. Leaving the IO thread running allowed the slave to write the relay logs during this process, and help ensure that the test only measures the difference in the slave SQL thread.
|
1 |
stop slave sql thread for channel 'db1'; stop slave sql thread for channel 'db3'; |
Each master had a sysbench run against it for the schema that was designated to it in order to generate the writes:
|
1 2 |
sysbench --db-driver=mysql --mysql-user= --mysql-password='' --mysql-db=db1 --range_size=100 --table_size=1000000 --tables=5 --threads=1 --events=0 --time=3600 --rand-type=uniform /usr/share/sysbench/oltp_write_only.lua run sysbench --db-driver=mysql --mysql-user= --mysql-password='' --mysql-db=db3 --range_size=100 --table_size=1000000 --tables=5 --threads=1 --events=0 --time=3600 --rand-type=uniform /usr/share/sysbench/oltp_write_only.lua run |
Once the writes completed, I monitored the IO activity on the slave to ensure it was 100% idle and that all relay logs were fully captured. Once everything was fully written, I enabled a capture of the replication lag once per minute for each replication channel, and started the slaves SQL threads:
|
1 2 3 |
usr/bin/pt-heartbeat -D db1 -h localhost --master-server-id=101 --check usr/bin/pt-heartbeat -D db3 -h localhost --master-server-id=103 --check start slave sql thread for channel 'db1'; start slave sql thread for channel 'db3'; |
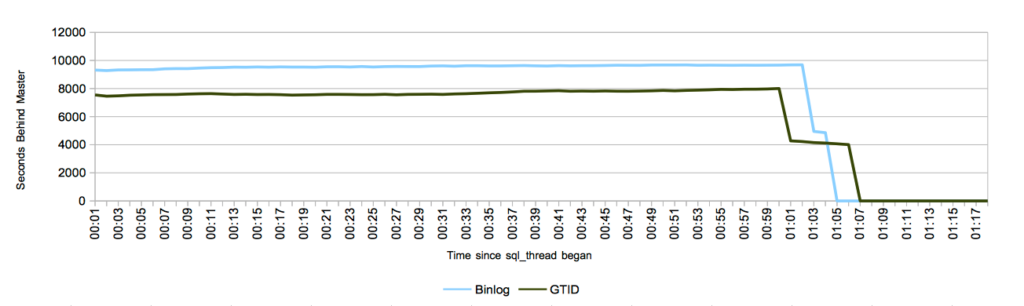
The above chart depicts the cumulative lag seen on the slave by pt-heartbeat since starting the sql_thread. The first item to noticed is that the replication delay was higher overall with the binary log. This could be because the SQL thread stopped for a different amount of time. This may appear to give GTID an advantage in this test, but remember with this test the amount of delay is less important than the processed rate. Focusing on when replication began to display a significant change towards catching up you can see that there are two distinct drops in delay. This is caused by the fact that the slave has two replication threads that individually monitor their delay. One of the replication threads caught up fully and the other was delayed for a bit longer.
In every test run, GTID took slightly longer to fully catch up than the traditional method. There are a couple of reasons to expect GTID’s to be slightly slower. One possibility is the that there are additional writes on the slave, in order to keep track of all the GTID’s that the slave ran. I removed the initial write to the relay log, but we must retain the committed GTID, and this causes additional writes. I used the default settings for MySQL, and as such log_slave_updates was disabled. This causes the replicated GTID to be stored in a table, which is periodically compressed. You can find more details on how log_slave_updates impacts GTID replication here.
I received some feedback regarding the above test that I missed a potential variable which could have impacted the results. With a one hour sysbench there could be a different number of transactions written to each server. This makes it so that each run could be different, and not necessarily comparable. To resolve this I set up a different test, where I could easily control the number, and size of transactions.
I created an identical table inside of each master’s schema.
|
1 2 3 4 5 6 7 |
CREATE TABLE `joinit` ( `i` int(11) NOT NULL AUTO_INCREMENT, `s` varchar(64) DEFAULT NULL, `t` time NOT NULL, `g` int(11) NOT NULL, PRIMARY KEY (`i`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; |
Just as in the previous test I then stopped the sql_thread on both channels of the slave:
|
1 |
stop slave sql thread for channel 'db1'; stop slave sql thread for channel 'db3'; |
I used a very simple bash loop to generate 500,000 insert statements against each of the masters:
|
1 2 3 |
for i in {1..500000}; do mysql -e "INSERT INTO db1.joinit VALUES (NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )));"; done; |
I also removed pt-heartbeat from this test. I did not want to add the additional writes, which might influence the results. Instead, I used the output from show slave status. I ran this test 10 times with each replication concept, truncating the table between runs. I also decided to change the way I looked at speed of the replication. Since this test focuses on replicating 1 million insert statements, I looked at the results as transactions per second:
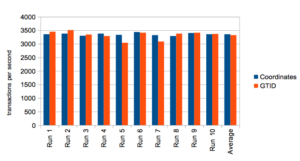
Overall the transactions per second remained within 10% for each concept. Looking at the average, my initial response was that it validates my original statement that GTID is “slightly” slower. However, when you look further the difference in the average transactions per second is only 32.32 transactions. That is .97% of the total transactions per second GTID averaged. Since the difference is less than 1%, I have to adjust my conclusion. There is no significant difference in the performance of the replication concepts.
So the question still exists, why should we use GTID, especially with multisource replication? I’ve found that the answer lies in the composition of a GTID. From MySQL’s GTID Concepts, a GTID is composed of two parts, the source_id, and the transaction_id. The source_id is a unique identifier targeting the server which originally wrote the transaction. This allows you to identify in the binary log which master took the initial write, and so you can pinpoint problems much easier.
The below excerpt from DB1’s (a master from this test) binary log shows that, before the transaction being written, the “SET @@SESSION.GTID_NEXT” ran. This is the GTID that you can follow through the rest of the topology to identify the same transaction.
“d1ab72e9-0220-11e8-aee7-00155dab6104” is the server_uuid for DB1, and 270035 is the transaction id.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
SET @@SESSION.GTID_NEXT= 'd1ab72e9-0220-11e8-aee7-00155dab6104:270035'/*!*/; # at 212345 #180221 15:37:56 server id 101 end_log_pos 212416 CRC32 0x758a2d77 Query thread_id=15 exec_time=0 error_code=0 SET TIMESTAMP=1519245476/*!*/; BEGIN /*!*/; # at 212416 #180221 15:37:56 server id 101 end_log_pos 212472 CRC32 0x4363b430 Table_map: `db1`.`sbtest1` mapped to number 109 # at 212472 #180221 15:37:56 server id 101 end_log_pos 212886 CRC32 0xebc7dd07 Update_rows: table id 109 flags: STMT_END_F ### UPDATE `db1`.`sbtest1` ### WHERE ### @1=654656 /* INT meta=0 nullable=0 is_null=0 */ ### @2=575055 /* INT meta=0 nullable=0 is_null=0 */ ### @3='20363719684-91714942007-16275727909-59392501704-12548243890-89454336635-33888955251-58527675655-80724884750-84323571901' /* STRING(120) meta=65144 nullable=0 is_null=0 */ ### @4='97609582672-87128964037-28290786562-40461379888-28354441688' /* STRING(60) meta=65084 nullable=0 is_null=0 */ ### SET ### @1=654656 /* INT meta=0 nullable=0 is_null=0 */ ### @2=575055 /* INT meta=0 nullable=0 is_null=0 */ ### @3='17385221703-35116499567-51878229032-71273693554-15554057523-51236572310-30075972872-00319230964-15844913650-16027840700' /* STRING(120) meta=65144 nullable=0 is_null=0 */ ### @4='97609582672-87128964037-28290786562-40461379888-28354441688' /* STRING(60) meta=65084 nullable=0 is_null=0 */ # at 212886 #180221 15:37:56 server id 101 end_log_pos 212942 CRC32 0xa6261395 Table_map: `db1`.`sbtest3` mapped to number 111 # at 212942 #180221 15:37:56 server id 101 end_log_pos 213166 CRC32 0x2782f0ba Write_rows: table id 111 flags: STMT_END_F ### INSERT INTO `db1`.`sbtest3` ### SET ### @1=817058 /* INT meta=0 nullable=0 is_null=0 */ ### @2=390619 /* INT meta=0 nullable=0 is_null=0 */ ### @3='01297933619-49903746173-24451604496-63437351643-68022151381-53341425828-64598253099-03878171884-20272994102-36742295812' /* STRING(120) meta=65144 nullable=0 is_null=0 */ ### @4='29893726257-50434258879-09435473253-27022021485-07601619471' /* STRING(60) meta=65084 nullable=0 is_null=0 */ # at 213166 #180221 15:37:56 server id 101 end_log_pos 213197 CRC32 0x5814a60c Xid = 2313 COMMIT/*!*/; # at 213197 |
The tests I ran show that there is not a significant difference in throughput for either replication concept. GTID is being recommended for use with multisource replication due to the ease of managing and troubleshooting the complex topology.
The GTID concept allows a slave to know exactly which server initially wrote the transaction, even in a tiered environment. This means that if you need to promote a slave from the bottom tier, to the middle tier, simply changing the master is all that is needed. The slave can pick up from the last transaction it ran on that server and continue replicating without a problem. Stephane Combaudon explains this in detail in a pair of blogs. You can find part 1 here and part 2 here. Facebook also has a great post about their experience deploying GTID-based replication and the troubles they faced.
Resources
RELATED POSTS





Bradley,
Any reason why you didn’t use parallel replication in this test?
Hi René,
I didn’t use parallel replication because I was trying to keep everything as simple as possible in order to reduce the variance additional features might add.