
The main benefit of using GTIDs is to have much easier failover than with file-based replication. We will see how to change the replication topology when using GTID-based replication. That will show where GTIDs shine and where improvements are expected.
This is the second post of a series of articles focused on MySQL 5.6 GTIDs. You can find part one here.
Our goal will be to go from setup #1 to setup #2 on the picture below, following various scenarios:
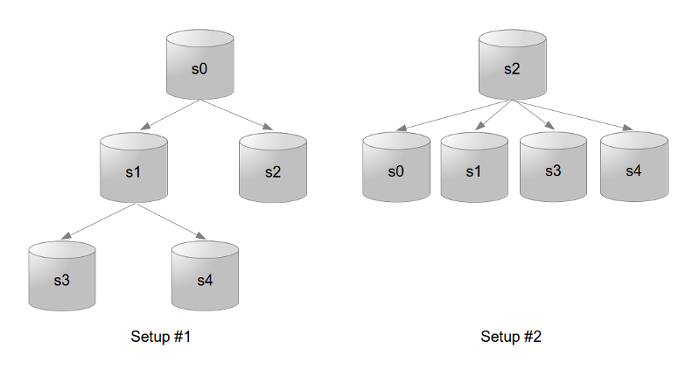
For these tests, all servers are running on 127.0.0.1 with ports ranging from 10000 for s0 to 10004 for s4.
This is the easiest case, we will make s2 a master and redirect replication on the other servers to s2. This scenario can happen when you want to perform a planned failover.
With GTIDs, all the operations are straightforward:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#For s2 (the new master), we remove its configuration as a slave s1> stop slave; s1> reset slave all; # For s0 s0> change master to master_host='127.0.0.1',master_user='rsandbox',master_password='rsandbox',master_port=10001,master_auto_position=1; s0> start slave; # For s1, s3 and s4 mysql> stop slave; mysql> change master to master_port=10002; mysql> start slave; |
Those of you who have already done these operations with file-based replication know that it is usually very tedious and that proper recording of binlog file/binlog position needs to be done with care if you don’t want to break replication or corrupt your data.
Now let’s imagine that s0 has crashed, and that s1 has not received all writes (and therefore s3 and s4 are also lagging behind).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
s2> select count(*) from t; +----------+ | count(*) | +----------+ | 2 | +----------+ # s1 is behind s1> select count(*) from t; +----------+ | count(*) | +----------+ | 0 | +----------+ |
Can we still use master_auto_position = 1? Let’s hope so, as it is one of the ideas of GTIDs: having for each event across the cluster a monotonically incremental identifier for each event.
Notice that this is the same problem for s0 (which will be late when it comes back) and s1, s3 and s4.
Let’s give it a try!
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# For s0,s1, s3, s4 mysql> stop slave; mysql> change master to master_port=10002; mysql> start slave; # And then check the number of records from the t table s1> select count(*) from t; +----------+ | count(*) | +----------+ | 2 | +----------+ |
Great! So again, using GTIDs avoids the tedious work of looking for the binlog position of a specific event. The only part were we should pay attention is the server we choose for promotion: if it is not up-to-date, data may be lost or replication may be broken.
If the binary logs of the master are no longer readable, you will probably lose the events that have not been sent to the slaves (your last chance is to be able to recover data from the crashed master, but that’s another story). In this case, you will have to promote the most up-to-date slave and reconfigure the other slaves as we did above.
So we will suppose that we can read the binary logs of the crashed master. The first thing to do after choosing which slave will be the new master is to recover the missing events with mysqlbinlog.
Let’s say that we want to promote s1 as the new master. We need to know the coordinates of the last event executed:
|
1 2 3 4 |
s1> show slave statusG [...] Executed_Gtid_Set: 219be3a9-c3ae-11e2-b985-0800272864ba:1, 3d3871d1-c3ae-11e2-b986-0800272864ba:1-4 |
We can see that it’s not obvious to know which was the last executed event: is it 219be3a9-c3ae-11e2-b985-0800272864ba:1 or 3d3871d1-c3ae-11e2-b986-0800272864ba:4 ? A ‘Last_Executed_GTID’ column would have been useful.
In our case we can check that 3ec18c45-c3ae-11e2-b986-0800272864ba is the server UUID of s2, and that the other one is from s0 (for s0 which is crashed, the server UUID can be read in the auto.cnf file in the datadir).
So the last executed event is 219be3a9-c3ae-11e2-b985-0800272864ba:1. How can I instruct mysqlbinlog to start reading from there? Unfortunately, there is no --start-gtid-position option or equivalent. See bug #68566.
Does it mean that we cannot easily recover the data with mysqlbinlog? There is a solution of course, but very poor in my opinion: look for the binlog file/position of the last executed event and use mysqlbinlog with the good old --start-position option! Even with GTIDs, you cannot totally forget old-style replication positioning.
Reconfiguring replication when using GTIDs is usually straightforward: just connect the slave to the correct master with master_auto_position = 1. This can even be made easier with mysqlfailover from the MySQL Utilities (this will be the topic of a future post).
Unfortunately, this will not work for every use case, and until this is fixed, it is good to be aware of the current limitations.





You are hitting a fundamental (and in my opinion bad) part of the design of
MySQL 5.6 global transaction ID. In general, there is no ordering implied
between events, because multi-threaded slave may put events in a different
order on one slave than on another (or on the master).
So in general “last executed GTID” makes little sense, rather the set of all
executed events is needed. And using mysqlbinlog to apply a binlog from a
different server from a specific point does not work, you need to apply just
the set of events missing.
Well, if the user is not using multi-threaded slave, perhaps the notion of
“last executed” and “specific point” does make sense, but the server code is
unable to make the necessary assumptions because it needs to handle the
general case also.
On Scenario #1, replace “change master to master_port=10001;”
with “change master to master_port=10002;”
‘@Kristian,
Well, the (slave) server *knows* whether it is replicating in parallel or not, so it doesn’t have to always manage the general case. When it knows it uses single thread replication the “last executed” assumption is safe.
‘@Kristian: Good point. I haven’t tried GTIDs in combination with multi-threaded slave yet, as enabling GTIDs only has provided a few surprises. So this hadn’t come to my mind.
@Shlomi: Fixed, thanks!
Stephane, how are you coping with bug#69095 (replication fails with GTID enabled and master changes from SBR to RBR) and bug#69135 (mysql.slave_master_info is not updated) ?
‘@Giuseppe: These bugs are very annoying and I don’t know any workaround.
However IMO all these bugs don’t mean you should not use GTIDs, you just need to be aware of the current limitations and see if you can accommodate with them (think of replication 10 years ago or partioning in 5.1 for instance).
When the slave A meet a primary dupicate key error,the binlog of a transaction will be splited to 2 transactions.
If the binlog of the slave A be processed by another slave ,the error will occur:
Last_SQL_Error: Cannot execute the current event group in the parallel mode. which prevents execution of this evf a group that is unsupported in the parallel execution mode.
Is this a bug?
http://stackoverflow.com/questions/17716190/is-a-gtid-bug-of-mysql5-6-when-the-slave-meet-a-primary-dupicate-key
Just a tip: when running databases on your own servers, be prepared with running a log management software to get alerts if any problems arise. One tool that’s worth checking out is NXLog – https://nxlog.co/products/nxlog-community-edition – a free and open source centralized log management software, which is able to scale to thousands of servers while keep running at high-performance. And it can collect and process logs from Linux, Windows, Android and more operating systems. It worth checking out if you want to get notified about any server or software issues that may come up.