
In this blog post, we look at the performance of Percona XtraDB Cluster on Amazon GP2 volumes.
In our overview blog post on Best Practices for Percona XtraDB Cluster on AWS, GP2 volumes did not show good results. However, we allocated only the size needed to fit the database (200GB volumes). Percona XtraDB Cluster did not show good performance on these volumes and provided only limited IOPs.
After publishing our material, Amazon engineers pointed that we should try GP2 volumes with the size allocated to provide 10000 IOPS. If we allocated volumes with size 3.3 TiB or more, we should achieve 10000 IOPS.
It might not be initially clear what the benefit of allocating 3.3 TiB volumes for the database, which is only 100 GiB in size, but in reality GP2 volumes this size are cheaper than IO provisioned volumes that provide 10000 IOPS. Below, we will show Percona XtraDB Cluster results on GP2 volumes 3.3 TB in size.
In the previous post. we used four different instance sizes: r4.large, r4.xlarge, r4.2xlarge and r4.4xlarge. In this case with GP2 volumes of 3.3TB, they are only available with r4.2xlarge and r4.4xlarge instances. We will only test these instances.
The dataset and workload are the same as in the previous post.
First, let’s review throughput and latency:
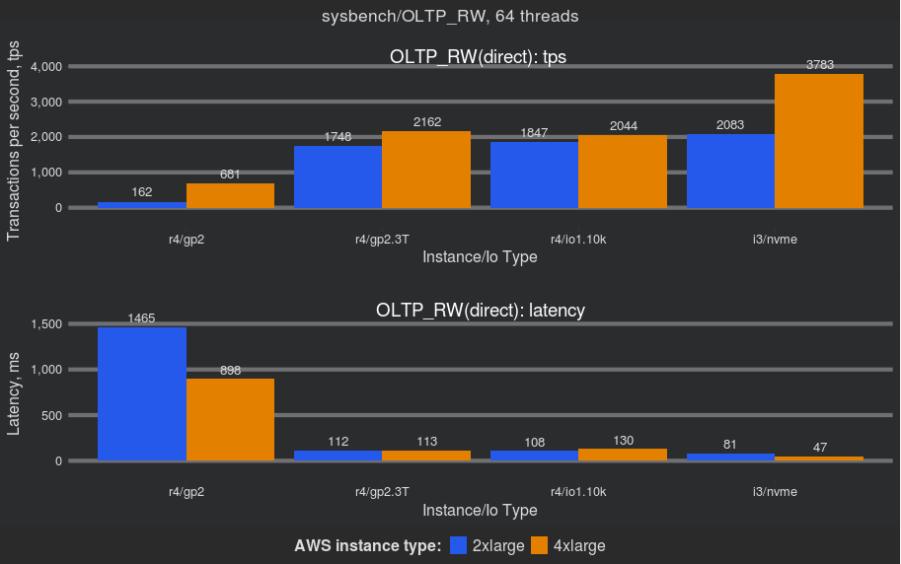
The legend:
The takeaway from these results is that 3.3 TB GP2 volumes greatly improve performance, and the results are comparable with IO provisioned volumes.
To compare the stability of latency on GP2 vs. IO1, we check the latency distribution (99% latency with 5-second interval resolution):
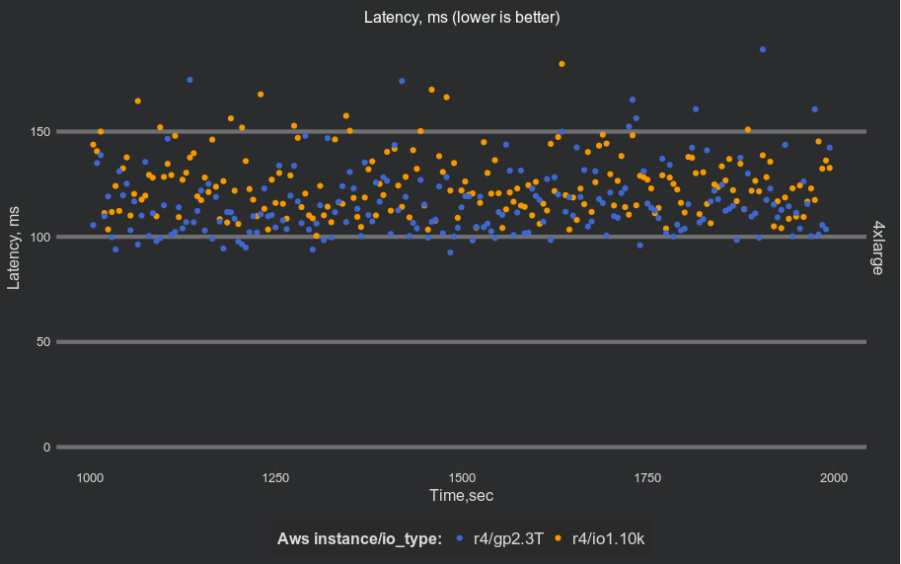
There is no major difference between these volumes types.
With cloud resources, you should always consider cost. Let’s review the cost of the volumes itself:
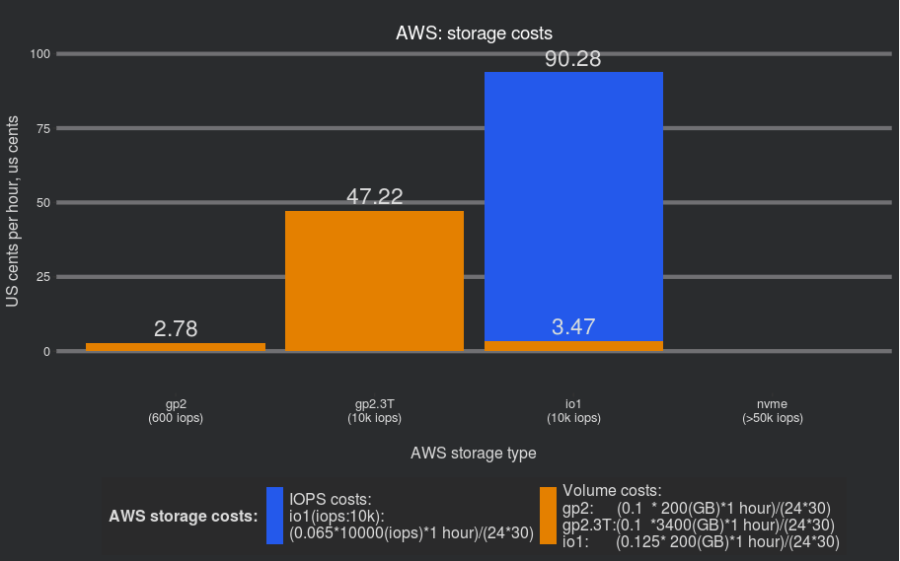
We can see that 3.3TB GP2 volumes are much more expensive than 200GB, but still about only the half of the cost of IO provisioned volumes (when we add the cost of provisioned IOPS).
And to compare the full cost of resources, let’s review the cost of an instance (we will use 1-year reserved prices):
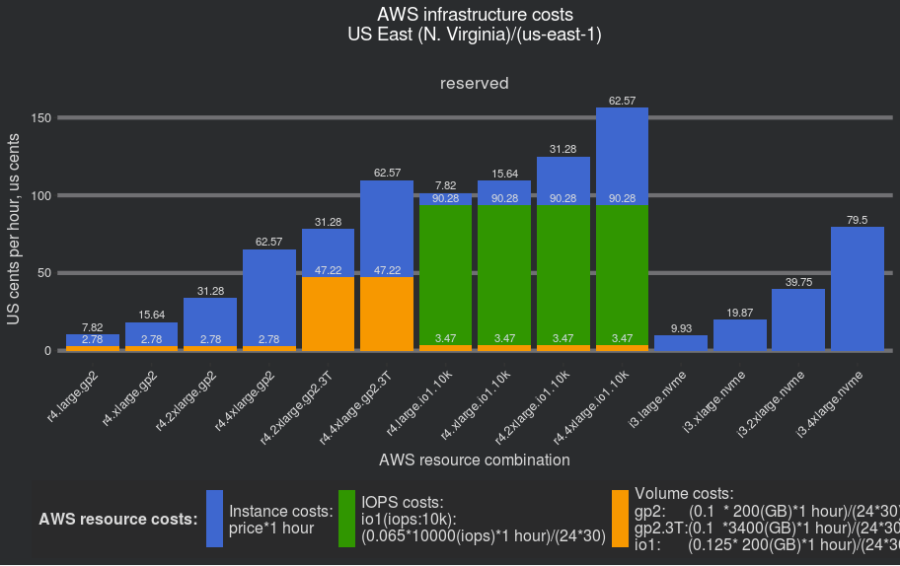
The points of interest:
And given the identical throughput, it may be more economically feasible to use 3.3TB GP2 volumes instead of IO provisioned volumes.
Now we can compare the transactions per second cost of 3.3 TB GP2 volumes with other instances:
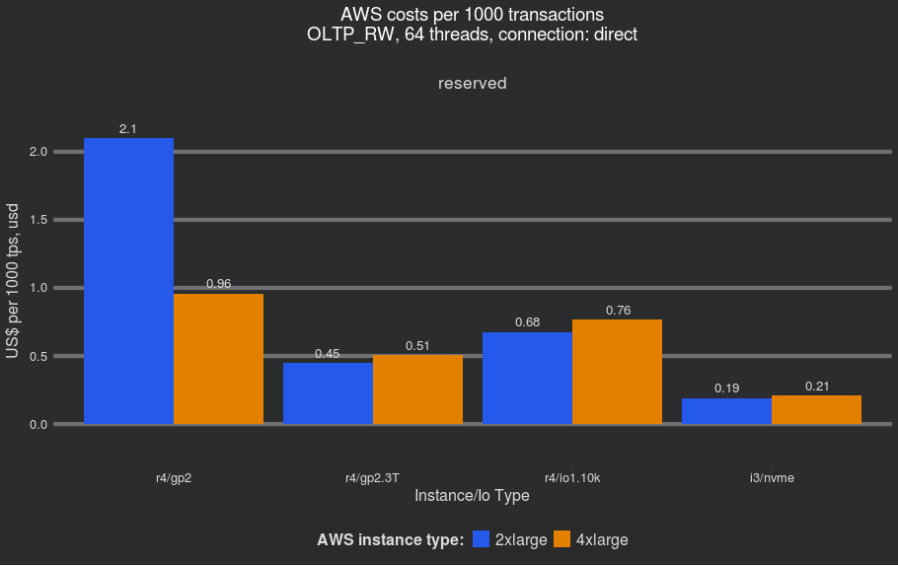
While i3 instances are still a clear winner, if you need to have the capabilities that EBS volumes provide, you might want to consider large GP2 volumes instead of IO provisioned volumes.
In general, large GP2 volumes provide a way to increase IO performance. It seems to be a viable alternative to IO provisioned volumes.





Hi Vadim,
I think another way to look at your findings is what if if you need less than 10K IOPS per volume it is cheaper to get them through larger volume size than through purchasing them as provisioned IOPS
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.html
While performance of GP2 with 10000 iops and io1 with 10000 iops seems to be very similar I wonder if there might be difference in some rare circumstances when system is committed. Though in this case the NVMe which tend to be dedicated to host should be the least affected.
If you need less than 10K IOPS per volume it is indeed cheaper and you might have some side benefits too, including more free storage for manual and automatic backups.
But it will be also much harder to reduce the size of a large GP2 volume than simply reducing the Provisioned IOPS on a IO1. Something to keep also in mind if the spike is temporary or if any sharding is planned later on.
Are there any issues with over-provisioning storage with respect to backup, restore, failover, etc.
For some apps, there’s a point of diminishing returns from increasing the IOPS.
I helped to load-test an app in 2017 that was moving from on-prem hosts to AWS. We tested simulated traffic for our real app, not an artificial load by using sysbench.
We tried using 100GB gp2 volumes, 1000GB gp2 volumes, and either size with 10k provisioned IOPS.
The result was that 1000GB gp2 volume with no provisioned IOPS gave the same throughput as with provisioned IOPS. Since it was much more expensive to add provisioned IOPS, we decided not to use them.
IOPS is not always the bottleneck. It’s not always best to throw higher IOPS capacity at the app to make it faster. It depends on the app.
Hi Bill,
Yes good point. Of course finding a way to get better IO performance in most cost effective way only makes sense if IO performance matter for your database/application performance to begin with.