
In this blog post I’ll look at the performance of Percona XtraDB Cluster on AWS using different service instances, and recommend some best practices for maximizing performance.
You can use Percona XtraDB Cluster in AWS environments. We often get questions about how best to deploy it, and how to optimize both performance and spend when doing so. I decided to look into it with some benchmark testing.
For these benchmark tests, I used the following configuration:
We evaluated different AWS instances to provide the best recommendation to run Percona XtraDB Cluster. We used instances
We also used different instance sizes:
| Instance | vCPU | Memory |
| r4.large | 2 | 15.25 |
| r4.xlarge | 4 | 30.5 |
| r4.2xlarge | 8 | 61 |
| r4.4xlarge | 16 | 122 |
| i3.large | 2 | 15.25 |
| i3.xlarge | 4 | 30.5 |
| i3.2xlarge | 8 | 61 |
| i3.4xlarge | 16 | 122 |
While I3 instances with NVMe storage do not provide the same functionality for handling shared storage and snapshots as General Purpose and IO provisioned volumes, since Percona XtraDB Cluster provides data duplication by itself we think it is still valid to include them in this comparison.
We ran benchmarks in the US East 1 (N. Virginia) Region, and we used different availability zones for each of the Percona XtraDB Cluster zones (mostly zones “b”, “c” and “d”):
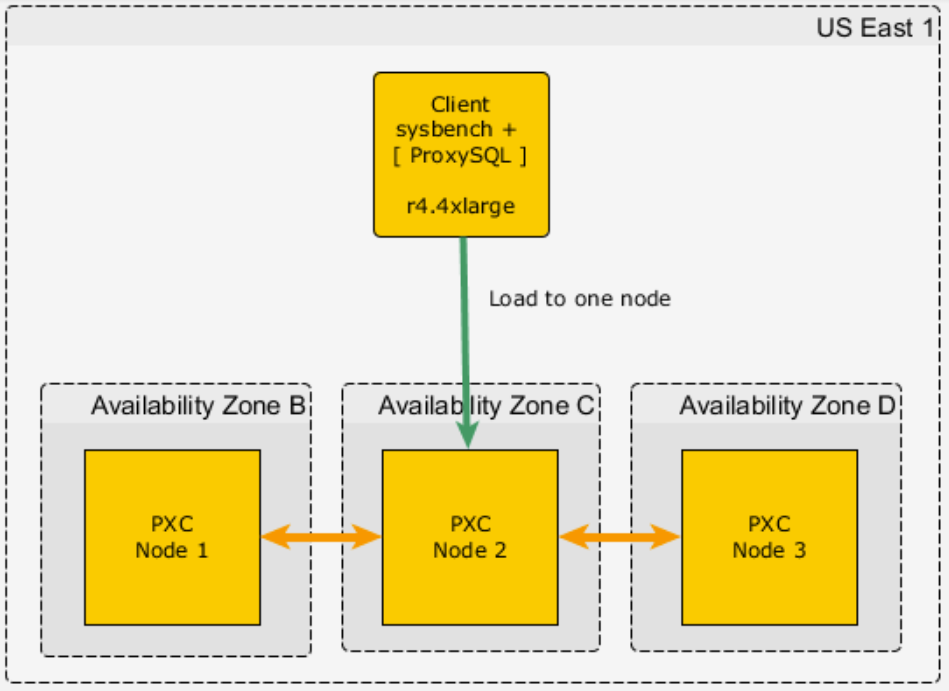
The client was directly connected and used ProxySQL, so we were able to measure ProxySQL’s performance overhead as well.
ProxySQL is an advanced method to access Percona XtraDB Cluster. It can perform a health check of the nodes and route the traffic to the ONLINE node. It can also split read and write traffic and route read traffic to different nodes (although we didn’t use this capability in our benchmark).
In our benchmarks, we used 1,4, 16, 64 and 256 user threads. For this detailed review, however, we’ll look at the 64 thread case.
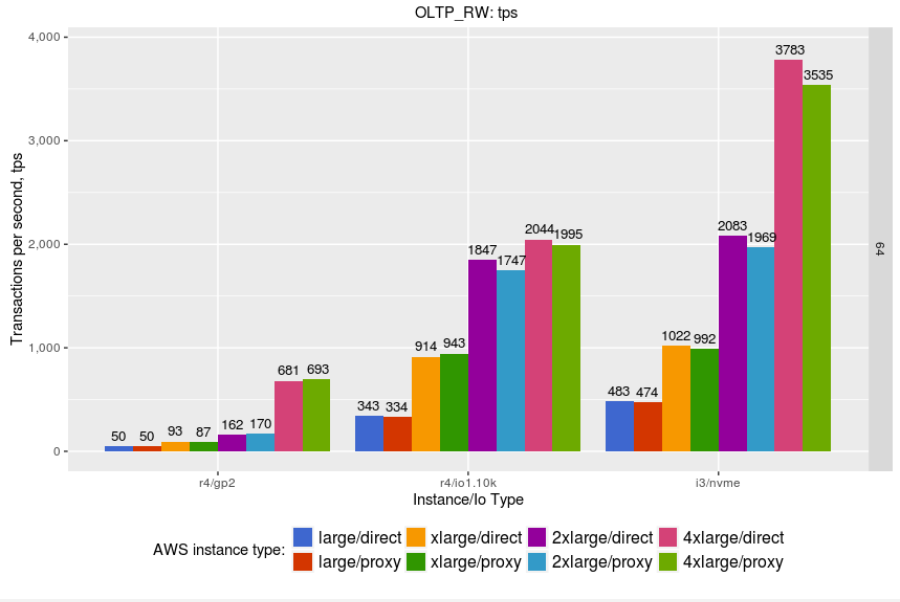
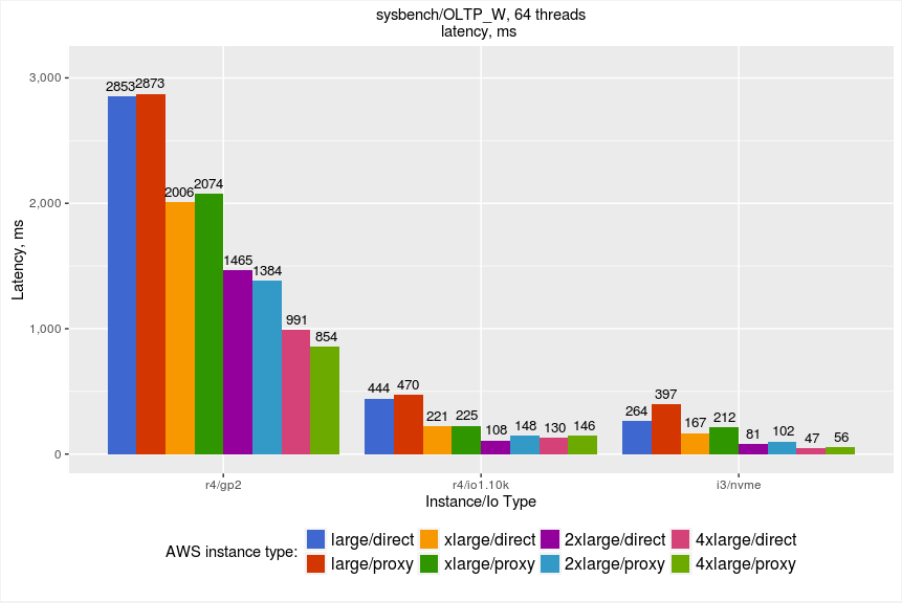
First, let’s review the average throughput (higher is better) and latency (lower is better) results (we measured 99% percentile with one-second resolution):
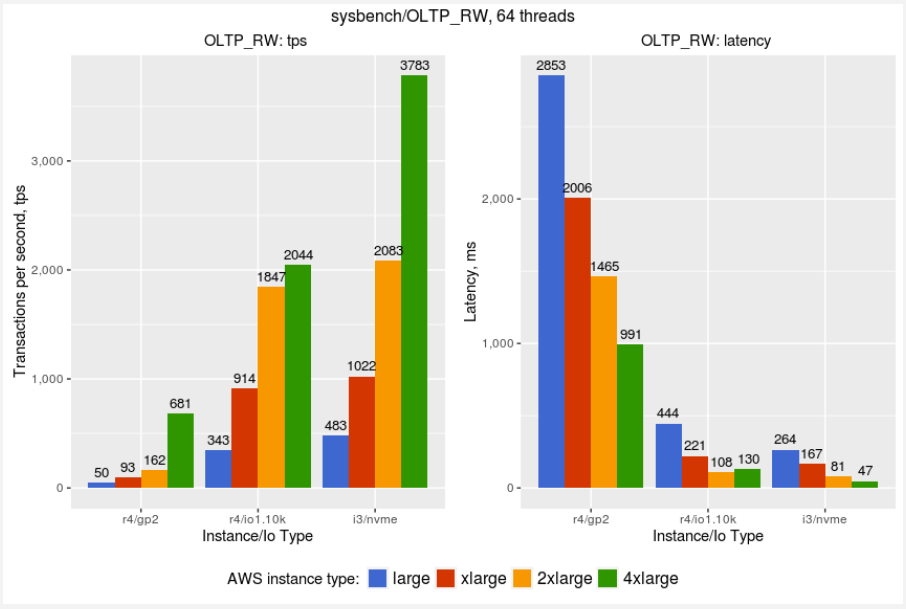
The performance for Percona XtraDB Cluster running on GP2 volumes is often pretty slow, so it is hard to recommend this volume type for the serious workloads.
IO provisioned volumes perform much better, and should be considered as the primary target for Percona XtraDB Cluster deployments. I3 instances show even better performance.
I3 instances use locally attached volumes and do not provide equal functionality as EBS IO provisioned volumes — although some of these limitations are covered by Percona XtraDB Cluster’s ability to keep copies of data on each node.
Along with average throughput and latency, it is important to take into account “jitter” — how stable is the performance during the runs?
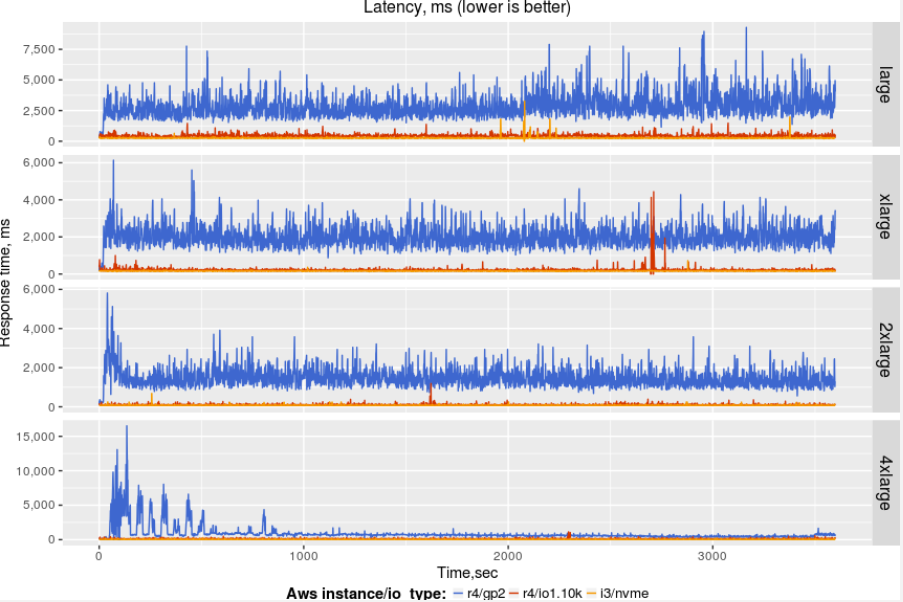
Latency variation for GP2 volumes is significant — practically not acceptable for serious usage. Let’s review the latency for only IO provisioning and NVMe volumes. The following chart provides better scale for just these two:
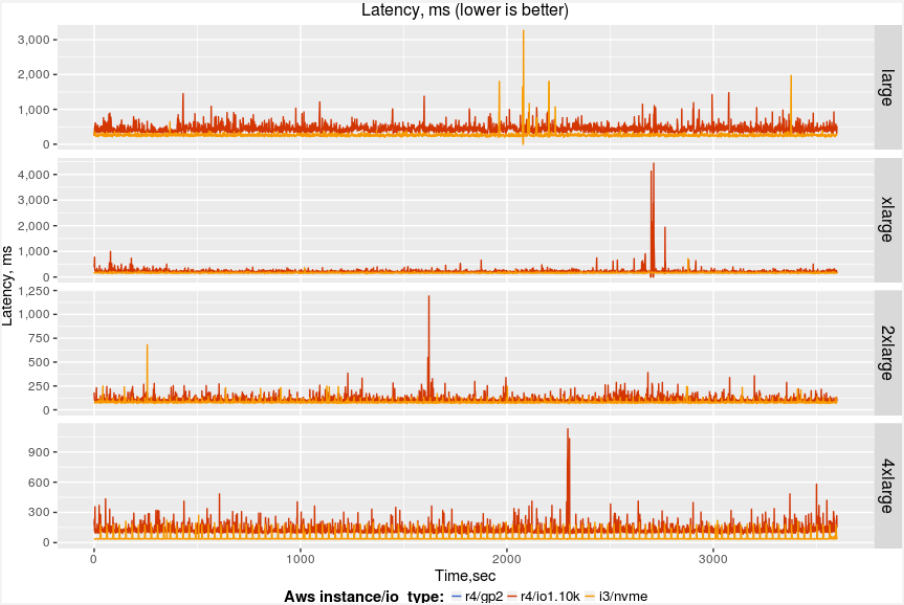
At this scale, we see that NVMe provides a 99% better response time and is more stable. There is still variation for IO provisioned volumes.
When speaking about instance and volume types, it would be impractical to avoid mentioning of the instance costs. We need to analyze how much we need to pay to achieve the better performance. So we prepared data how much does it cost to produce throughput of 1000 transactions per second.
We compare on-demand and reserved instances pricing (reserved for one year / all upfront / tenancy-default):
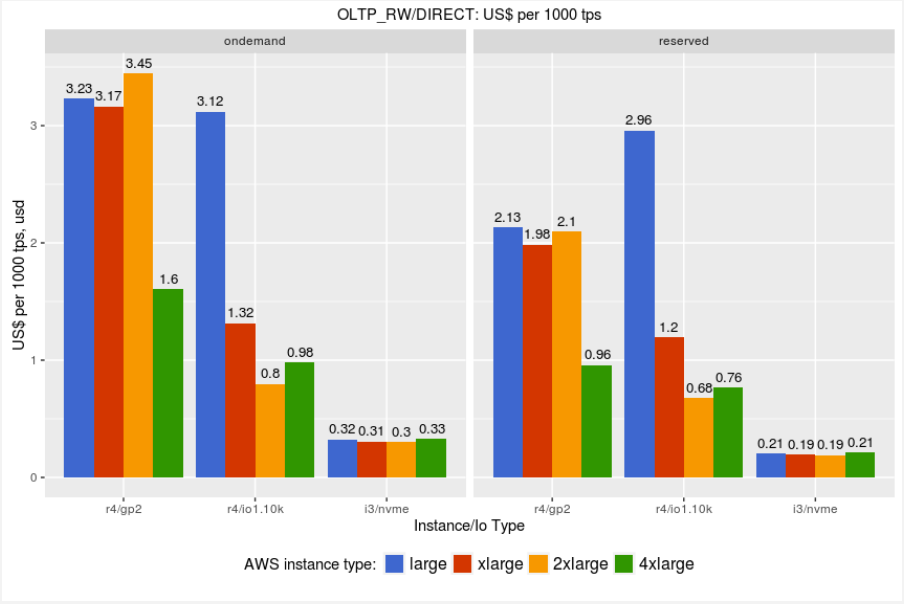
Because IO provisioned instances give much better performance, the price performance is comparable if not better than GP2 instances.
I3 instances are a clear winner.
It is also interesting to compare the raw cost of benchmarked instances:
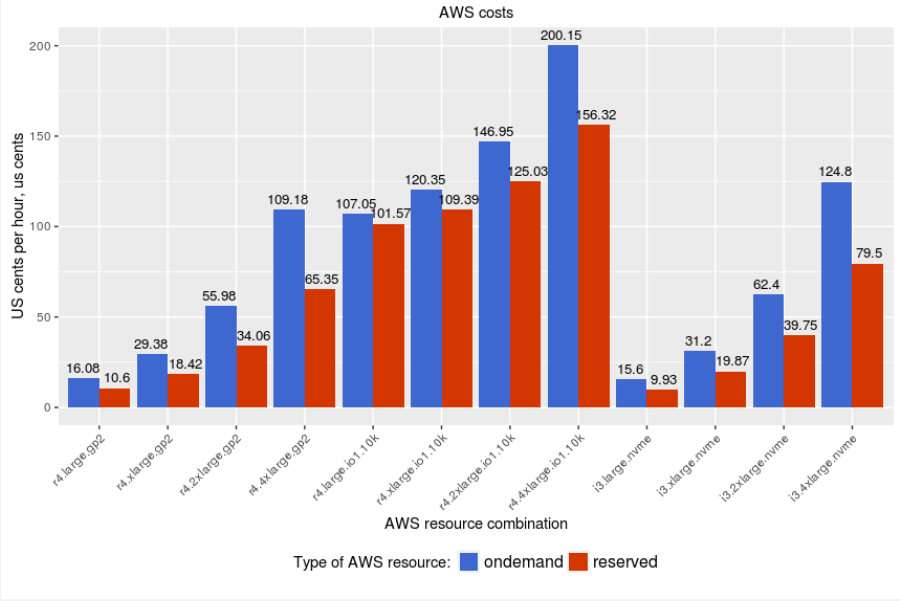
We can see that IO provisioned instances are the most expensive, and using reserved instances does not provide much savings. To understand the reason for this, let’s take a look at how cost is calculated for components:
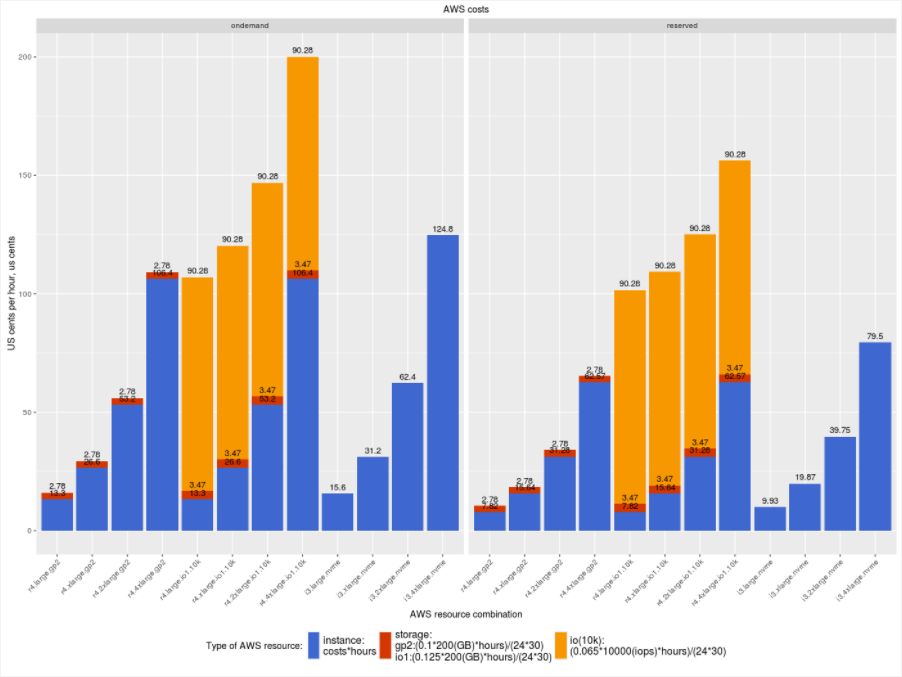
So for IO provisioned volumes, the majority of the cost comes from IO provisioning (which is the same for both on-demand and reserved instances).
Another interesting effort is looking at how Percona XtraDB Cluster performance scales with the instance size. As we double resources (both CPU and Memory) while increasing the instance size, how does it affect Percona XtraDB Cluster?
So let’s take a look at throughput:
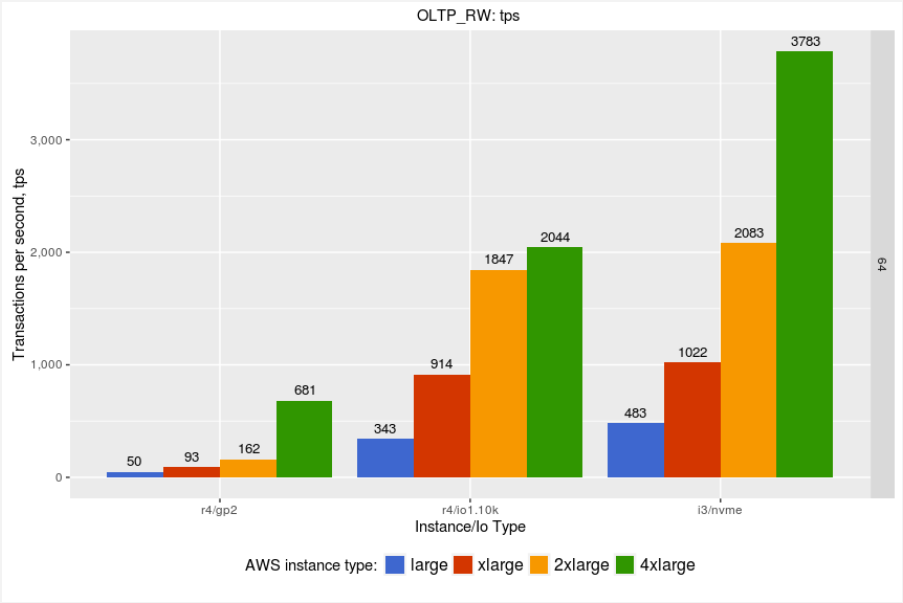
Throughput improves with increasing the instance size. Let’s calculate speedup with increasing instance size for IO provisioned and I3 instances:
| Speedup X Times to Large Instance | IO1 | i3 |
| large | 1 | 1 |
| xlarge | 2.67 | 2.11 |
| 2xlarge | 5.38 | 4.31 |
| 4xlarge | 5.96 | 7.83 |
Percona XtraDB Cluster can scale (improve performance) with increasing instance size. Keep in mind, however, that it depends significantly on the workload. You may not get the same performance speedup as in this benchmark.
As mentioned above, ProxySQL adds additional functionality to the cluster. It can also add overhead, however. We would like to understand the expected performance penalty, so we compared the throughput and latency with and without ProxySQL.
Out of box, the ProxySQL performance was not great and required additional tuning.
ProxySQL specific configuration:
Throughput:
Response time:
ProxySQL performance penalty in throughput
| ProxySQL performance penalty | IO1 | i3 |
| large | 0.97 | 0.98 |
| xlarge | 1.03 | 0.97 |
| 2xlarge | 0.95 | 0.95 |
| 4xlarge | 0.96 | 0.93 |
It appears that ProxySQL adds 3-7% overhead. I wouldn’t consider this a significant penalty for additional functionality.
First, the results show that instances based on General Purpose volumes do not provide acceptable performance and should be avoided in general for serious production usage. The choice is between IO provisioned instances and NVMe based instances.
IO provisioned instances are more expensive, but offer much better performance than General Purpose volumes. If we also look at price/performance metric, IO provisioned volumes are comparable with General Purpose volumes. You should use IO provisioned volumes if you are looking for the functionality provided by EBS volumes.
If you do not need EBS volumes, however, then i3 instances with NVMe volumes are a better choice. Both are cheaper and provide better performance than IO provisioned instances. Percona XtraDB Cluster provides data duplication on its own, which mitigates the need for EBS volumes to some extent.
We recommend using Percona XtraDB Cluster in combination with ProxySQL, as ProxySQL provides additional management and routing functionality. In general, the overhead for ProxySQL is not significant. But in our experience, however, ProxySQL has to be properly tuned — otherwise the performance penalty could be a bottleneck.
AWS has great capability to increase the instance size (both CPU and memory) if we exceed the capacity of the current instance. From our experiments, we see that Percona XtraDB Cluster can scale along with and benefit from increased instance size.
Below is a chart showing the speedup in relation to the instance size:
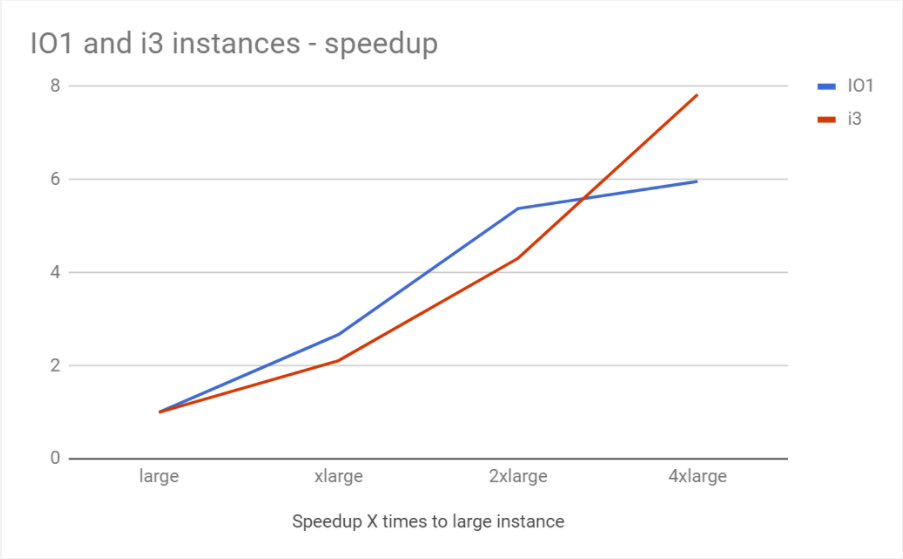
So increasing the instance size is a feasible strategy for improving Percona XtraDB Cluster performance in an AWS environment.
Thanks for reading this benchmark! Put any questions or thoughts in the comments below.





Availability Zone (AZ) mapping is not same in different account:
https://aws.amazon.com/ec2/faqs/
Q: How can I make sure that I am in the same Availability Zone as another developer?
We do not currently support the ability to coordinate launches into the same Availability Zone across AWS developer accounts. One Availability Zone name (for example, us-east-1a) in two AWS customer accounts may relate to different physical Availability Zones.
Hi Vadim, Alexey
great report !
Is it possible to know how much CPU / RAM ProxySQL using during the test, because from me scalability of system depend also on this, and is it possible to view Galera and ProxySQL configuration files ?
Thank you very much
any thoughts on having one node on premises and 2 in the cloud?