
In this blog post, I will run a gh-ost benchmark against the performance of pt-online-schema-change.
When gh-ost came out, I was very excited. As MySQL ROW replication became commonplace, you could use it to track changes instead of triggers. This practice is cleaner and safer compared to Percona Toolkit’s pt-online-schema-change. Since gh-ost doesn’t need triggers, I assumed it would generate lower overhead and work faster. I frequently called it “pt-online-schema-change on steroids” in my talks. Finally, I’ve found some time to check my theoretical claims with some benchmarks.
DISCLAIMER: These benchmarks correspond to one specific ALTER TABLE on the table of one specific structure and hardware configuration. I have not set up a broad set of tests. If you have other results – please comment!
Prepare the table by running:
|
1 |
sysbench --threads=40 --rate=0 --report-interval=1 --percentile=99 --events=0 --time=0 --db-ps-mode=auto --mysql-user=sbtest --mysql-password=sbtest /usr/share/sysbench/oltp_read_write.lua --table_size=10000000 prepare |
The table size is about 3GB (completely fitting to innodb_buffer_pool).
Run the benchmark in “full ACID” mode with:
This is important as this workload is heavily commit-bound, and extensively relies on group commit.
This is the pt-online-schema-change command to alter table:
|
1 |
time pt-online-schema-change --execute --alter "ADD COLUMN c1 INT" D=sbtest,t=sbtest1 |
This the gh-ost command to alter table:
|
1 |
time ./gh-ost --user="sbtest" --password="sbtest" --host=localhost --allow-on-master --database="sbtest" --table="sbtest1" --alter="ADD COLUMN c1 INT" --execute |
For each test the old sysbench table was dropped and a new one prepared. I tested alter table in three different cases:
I measured the alter table completion times for all cases, as well as the overhead generated by the alter (in other words, how much peak throughput is reduced by running alter table through the tools).
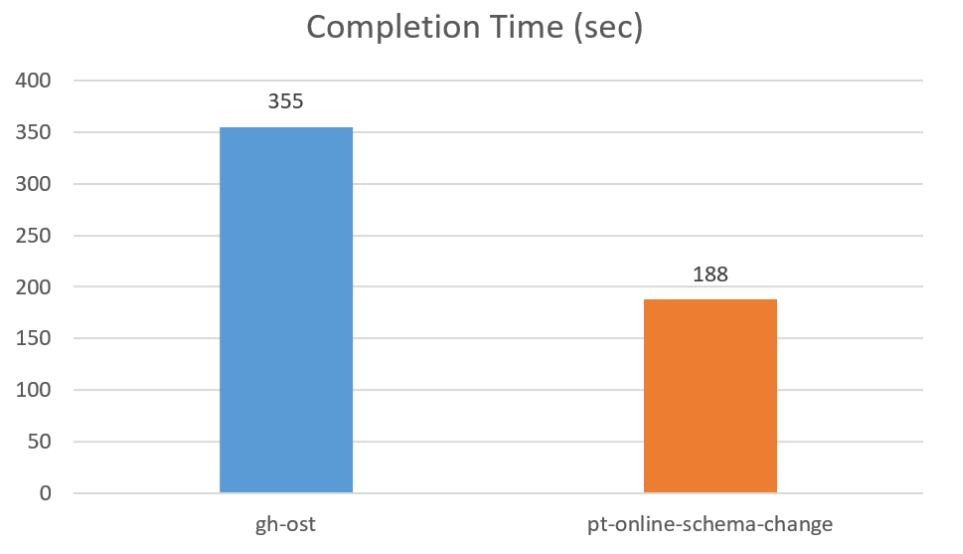
For the Idle Load test, pt-online-schema-change completed nearly twice as fast as gh-ost. This was a big surprise for me. I haven’t looked into the reasons or details yet, though I can see most of the CPU usage for gh-ost is on the MySQL server side. Perhaps the differences relate to the SQL used to perform non-blocking alter tables.
I generated the Light Background Load by running the sysbench command below. It corresponds to a roughly 4% load, as the system can handle some 2500 transactions/sec at this concurrency under full load. Adjust the --rate value to scale it for your system.
|
1 |
time sysbench --threads=40 --rate=100 --report-interval=1 --percentile=99 --events=0 --time=0 --db-ps-mode=auto --mysql-user=sbtest --mysql-password=sbtest /usr/share/sysbench/oltp_read_write.lua --table_size=10000000 run |
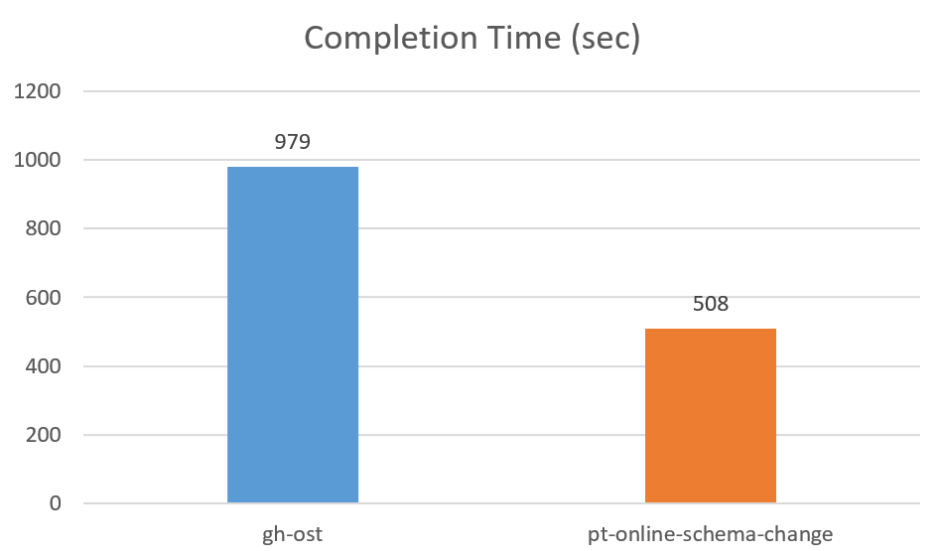
The numbers changed (as expected), but pt-online-schema-change is still approximately twice as fast as gh-ost.
What is really interesting in this case is how a relatively light background load affects the process completion time. It took both pt-online-schema-change and gh-ost about 2.7x times longer to finish!
I generated the Heavy Background Load running the sysbench command below. It corresponds to a roughly 40% load, as the system can handle some 2500 transactions/sec at this concurrency under full load. Adjust --rate value to scale it for your system.
|
1 |
time sysbench --threads=40 --rate=1000 --report-interval=1 --percentile=99 --events=0 --time=0 --db-ps-mode=auto --mysql-user=sbtest --mysql-password=sbtest /usr/share/sysbench/oltp_read_write.lua --table_size=10000000 run |
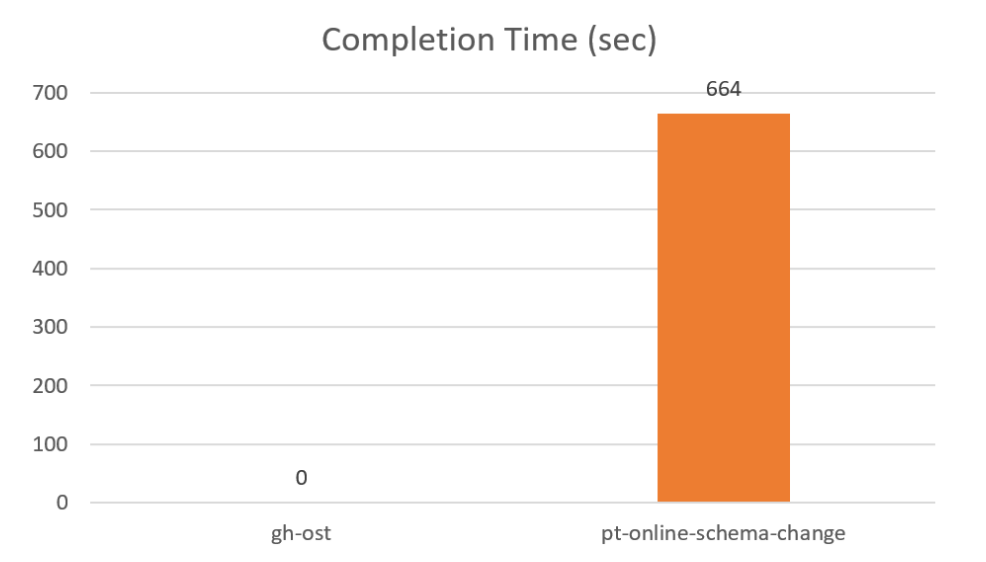
What happened in this case? When the load gets higher, gh-ost can’t keep up with binary log processing, and just never finishes at all. While this may be surprising at first, it makes sense if you think more about how these tools work. pt-online-schema-change uses triggers, and while they have a lot of limitations and overhead they can execute in parallel. gh-ost, on the other hand, processes the binary log in a single thread and might not be able to keep up.
In MySQL 5.6 we didn’t have parallel replication, which applies writes to the same table in parallel. For that version the gh-ost limitation probably isn’t as big a deal, as such a heavy load would also cause replication lag. MySQL 5.7 has parallel replication. This makes it much easier to quickly replicate workloads that are too heavy for gh-ost to handle.
I should note that the workload being simulated in this benchmark is a rather extreme case. The table being altered by gh-ost here is at the same time handling a background load so high it can’t be replicated in a single thread.
Future versions of gh-ost could improve this issue by applying binlog events in parallel, similar to what MySQL replicas do.
An excerpt from the gh-ost log shows how it is totally backed up trying to apply the binary log:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
root@rocky:/tmp# time ./gh-ost --user="sbtest" --password="sbtest" --host=localhost --allow-on-master --database="sbtest" --table="sbtest1" --alter="ADD COLUMN c1 INT" --execute 2017/06/25 19:16:05 binlogsyncer.go:75: [info] create BinlogSyncer with config &{99999 mysql localhost 3306 sbtest sbtest false false <nil>} 2017/06/25 19:16:05 binlogsyncer.go:241: [info] begin to sync binlog from position (rocky-bin.000018, 640881773) 2017/06/25 19:16:05 binlogsyncer.go:134: [info] register slave for master server localhost:3306 2017/06/25 19:16:05 binlogsyncer.go:568: [info] rotate to (rocky-bin.000018, 640881773) 2017-06-25 19:16:05 ERROR parsing time "" as "2006-01-02T15:04:05.999999999Z07:00": cannot parse "" as "2006" # Migrating `sbtest`.`sbtest1`; Ghost table is `sbtest`.`_sbtest1_gho` # Migrating rocky:3306; inspecting rocky:3306; executing on rocky # Migration started at Sun Jun 25 19:16:05 -0400 2017 # chunk-size: 1000; max-lag-millis: 1500ms; max-load: ; critical-load: ; nice-ratio: 0.000000 # throttle-additional-flag-file: /tmp/gh-ost.throttle # Serving on unix socket: /tmp/gh-ost.sbtest.sbtest1.sock Copy: 0/9872432 0.0%; Applied: 0; Backlog: 0/100; Time: 0s(total), 0s(copy); streamer: rocky-bin.000018:641578191; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 0; Backlog: 100/100; Time: 1s(total), 1s(copy); streamer: rocky-bin.000018:641626699; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 640; Backlog: 100/100; Time: 2s(total), 2s(copy); streamer: rocky-bin.000018:641896215; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 1310; Backlog: 100/100; Time: 3s(total), 3s(copy); streamer: rocky-bin.000018:642178659; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 1920; Backlog: 100/100; Time: 4s(total), 4s(copy); streamer: rocky-bin.000018:642436043; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 2600; Backlog: 100/100; Time: 5s(total), 5s(copy); streamer: rocky-bin.000018:642722777; State: ... Copy: 0/9872432 0.0%; Applied: 120240; Backlog: 100/100; Time: 3m0s(total), 3m0s(copy); streamer: rocky-bin.000018:694142377; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 140330; Backlog: 100/100; Time: 3m30s(total), 3m30s(copy); streamer: rocky-bin.000018:702948219; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 160450; Backlog: 100/100; Time: 4m0s(total), 4m0s(copy); streamer: rocky-bin.000018:711775662; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 180600; Backlog: 100/100; Time: 4m30s(total), 4m30s(copy); streamer: rocky-bin.000018:720626338; State: migrating; ETA: N/A Copy: 0/9872432 0.0%; Applied: 200770; Backlog: 100/100; Time: 5m0s(total), 5m0s(copy); streamer: rocky-bin.000018:729509960; State: migrating; ETA: N/A |
For this test I started the alter table, waited 60 seconds and then ran sysbench at full speed for five minutes. Then I measured how much the performance was impacted by running the tool:
|
1 |
sysbench --threads=40 --rate=0 --report-interval=1 --percentile=99 --events=0 --time=300 --db-ps-mode=auto --mysql-user=sbtest --mysql-password=sbtest /usr/share/sysbench/oltp_read_write.lua --table_size=10000000 run |
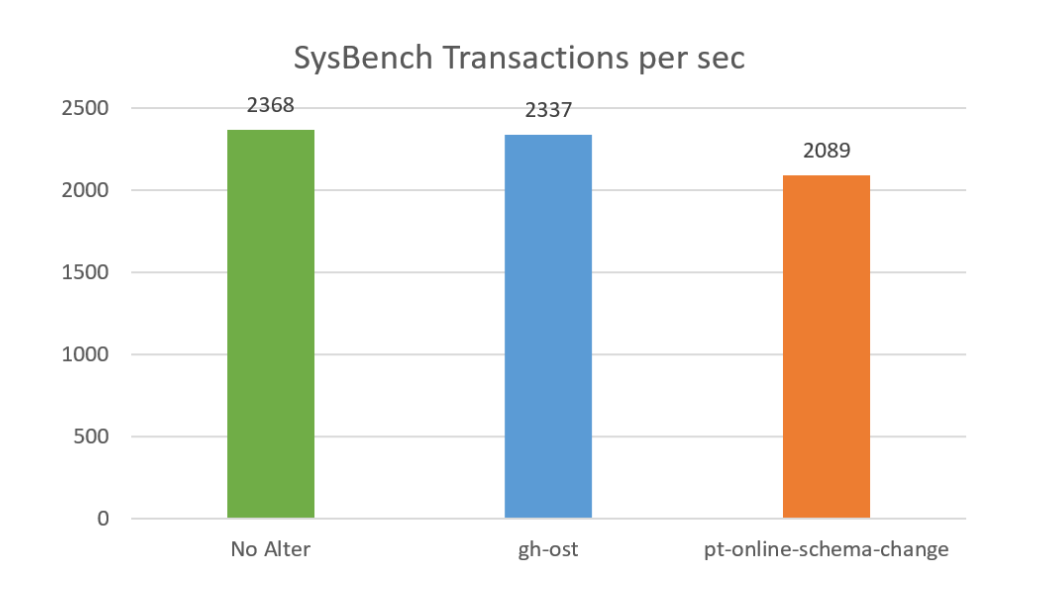
As we can see, gh-ost has negligible overhead in this case. pt-online-schema-change on the other hand, had peformance reduced by 12%. It is worth noting though that pt-online-schema-change still makes progress in this case (though slowly), while gh-ost would never complete.
If anything, I was surprised at how little impact the pt-online-schema-change run had on sysbench performance.
It’s important to note that in this case we only measured the overhead for the “copy” stage of the online schema change. Another thing you should worry about is the impact to performance during “table rotation” (which I have not measured).
While gh-ost introduces a number of design advantages, and gives better results in some situation, I wouldn’t call it always superior the tried and true pt-online-schema-change. At least in some cases, pt-online-schema-change offers better performance than gh-ost and completes a schema change when gh-ost is unable to keep up. Consider trying out both tools and see what works best in your situation.





Thank you for reviewing gh-ost. As requested, I’ll share a different experience.
Disclosure: I am the maintainer of gh-ost
Disclosure: Peter shared his results with me earlier on and we had a private discussion on his results, as well as a chance to improve them.
Disclosure: I am the author of oak-online-alter-table, the original migration tool; pt-online-schema-change uses the same algorithm oak-online-alter-table used, plus useful perks.
TL;DR in all our production experience we’ve seen an opposite effect from the SysBench experiment above.
Our perception of gh-ost (and how it differs from pt-online-schema-change) is quite different, and based on production pain points we’ve identified both at our current position at GitHub as well as at our past experiences.
In the proposed benchmark gh-ost is unable to complete the migration; this is indeed unfortunate and I was surprised by it. Nonetheless our production experience shows the other side of the coin: pt-online-schema-change is unable to complete a migration at GitHub where gh-ost runs quietly under the radar.
Storytime:
We began discussing our pains with online migration back in the beginning of 2016. We were running migrations routinely, daily. Some migrations were fast and some were slow. Some were “dangerous”: they would cause increased locks, high server load; we would see spikes of
threads_runningor of mutex contentions, and GitHub’s service would be visibly slower. These “dangerous” migrations we would run over nights or over weekends to mitigate the impact. Even so we would still see load. Occasionally a migration would go rouge and cause such lockup that we would need to kill it. We would use chatops for removing the triggers of a rouge migrations. It was clear that the triggers were causing the load.Back then, at the beginning of 2016, we were planning for GitHub’s growth and for products we were expecting to deliver. We were under the understanding that we would not be able to grow with current migration scheme (and turned out we were right, please read on). At that time our then colleague and now our esteemed, wonderful, benevolent manager came up with the idea of binlog based migrations, and shortly after that we proposed a new migration solution, gh-ost.
The main objective for the new solution: run safe migrations. Other objectives: visibility & control. We declared up front that speed was _not_ an objective.
I’d like to elaborate a bit on that, since others were surprised by this non-objective. Typically you wish to optimize for speed. Faster is better. However some things are OK to run for longer times. Looking at the flow for migrations, engineers were spending a few days designing and writing their new code, testing locally for a couple days, then requesting the change in production, and then potentially only making the new functionality visible incrementally via feature flags. In this flow, if a migration runs for
10hours or if it runs for12hours is insignificant.We developed gh-ost over the course of March-July 2016; however during that time we were painfully bitten by our prediction: we couldn’t run migrations anymore. We had multiple, recurring (reproducing!) occasions where pt-online-schema-change would grind our servers to a near-halt, or to a halt, or to a complete lockdown. GitHub suffered outages and otherwise was delivering poor service directly due to pt-online-schema-change migrations.
We now had not only “dangerous” migrations but also “impossible” migrations. Development slowed down: we would stall “dangerous” migrations; if two developers were to be requesting migration on same table we would stall the first so that we could run both changes in a single migration rather than two. Some development was rejected up front. “Can’t be done right now, go home and drink some hot tea”.
We were on three trajectories to solve our situation:
1. Solve the lockdowns. Understand the bug; look for updates; tamper with configurations. A full time member of our team was working on this.
2. Work around live migrations. We would run migrations individually on the replicas in the course of weeks, completing by failing over the master.
3. Pursue gh-ost development.
To elaborate a bit more on (1): we had one assumption that we figured out the bug (looking at bug reports in both MySQL and Percona bug tracking) and spent a while upgrading to hopefully solve the problem. It was a great detective work, and we learned many things along the way, but unfortunately it didn’t help.
We did not report this; this would manifest (and reproduce) in production only, but as you can imagine we were under quite the load when such outages happened to be able to produce a quality test-case with logs and everything. We generally strongly prefer to open bugs.
It should also be noted that we’ve seen similar scenarios before. At our past experiences, we had “impossible” migrations or “dangerous” migrations, too. We all come from or have worked with places of very high traffic. This incidents were well known.
Even so, gh-ost was already underway and we expected it to come out in a short period of time.
Eventually we put gh-ost to production in the duration of July, and as of its first production migration we never looked back.
If some migrations take longer than before, we don’t know and don’t care too much. We kick a migration and go to sleep (to make a point, this is _literally_ our preferred way of stating a migration). During the first months, whenever GitHub would experience load, all engineers would naturally ask right away “is there a migration running?” — and gh-ost was proven time and again to be a non-issue.
Our gh-ost migrations are not generating a visible load on our master. I do mean this literally. There is no “before migration” and “during migration” change of graph. We throttle gh-ost on subsecond replication resolution (we change the threshold from time to time, ranging 300ms – 1000ms) and it keeps low profile.
A couple tables are extremely large and migrations on those tables make take even a couple weeks; those are extreme case and of course are painful in the sense that, well, someone is waiting for a couple weeks. We are regardless looking to mitigate the size of those tables for many other understandable reasons. Otherwise we expect migrations to run in the course of minutes to hours.
When a migration runs, it makes itself visible to our engineers in chat; any engineer may choose to (but none choose to at this time) throttle it manually; or kill it. We don’t do it because we are finally convinced there’s no need to. But having that option is just what’s giving us that piece of mind.
This isn’t just our experience. I know of others who have experienced the same: from high load (pt-online-schema-change) to invisible load (gh-ost).
I must of course clarify: anyone should use the tool that works best for them.
gh-ost is not a silver bullet. It has (documented) limitations. The greatest limitation to gh-ost is the fact that it owns the data. pt-online-schema-change happily delegates the actual transfer of data to MySQL. gh-ost reads and copies the data itself. This means we need to invest time in supporting new features (
json, virtual columns).If gh-ost doesn’t work for you, and pt-online-schema-change does, I’m happy for you.
There are also dangers. gh-ost touches your data hence you trust gh-ost to not corrupt your data. It is a non-trivial piece of software and no software is without its own bugs. We address data integrity bugs seriously. Fortunately, gh-ost comes with a built-in testing method where you can, if you choose to, validate any migration in production, without really changing production data.
The results Peter shared with me surprised me, because I’ve never seen them in production. I agree with them, of course. Likewise, I clarify that I’m sure some production systems experience similar load to the one described in the post.
Looking at how to improve gh-ost to be able to cope with this benchmark, I do not expect to be writing binlog events in parallel in the near future. The binlog events gh-ost is interested in are all of _the same table_. Hence they will conflict (or _potentially_ conflict) by definition. Solving that on the application side would be non-trivial. Together with Peter we tried to apply writes in larger batches, but that didn’t help. I’ll continue to think what would make for a better write throughput.
By the way, we don’t in any way describe gh-ost as “pt-online-schema-change on steroids”. We describe it as “safe, trusted migrations”.
Thank you again!
Peter, another thing brought into my attention by my colleagues is that you were running gh-ost locally on the migrated box, and weren’t utilizing replication.
Notwithstanding binlog write capacity, which I expect to not be affected, we run gh-ost using a master-replica setup, and where gh-ost executed on a third box. It reads binlogs from the replica, then applies them on the master. This further reduces load from the master and it’s worth experimenting with in your benchmark.
Shlomi,
Yes. I tried it in the most simple setup with one server. Perhaps using Master-Slave variant would yield different results, though I still believe the issue of applying binary log in the single thread will not allow to handle workloads which require MySQL 5.7 parallel replication to proceed. As I understand you’re not running 5.7 parallel replication, meaning by definition you’re not pushing very heavy write loads through replication.
Speaking about overhead I think my results confirm what you’re seeing. pt-online-schema-change introduces larger overhead even in this set up. I can imagine scenarios where the triggers would produce a lot higher overhead than I observed.
Now my intent with this blog post is to state this is one of observed behaviors. Hopefully we will see more people doing more benchmarks to help us to understand the difference in the performance and overhead between gh-ost and pt-online-schema-change better
Can report that a binlog solution will always be safer on heavy write workload, it is very well know that chunk row locking can never finish with non equal distribution of the workload using online trigger base tools, just update a single row 2000 time per second and you block the online operation for ever , just insert into gap locks like UUID or whatever else .
Shlomi always open the doors to fixe productions issues, can do to you again.
‘@shlomi :
“Together with Peter we tried to apply writes in larger batches, but that didn’t help. I’ll continue to think what would make for a better write throughput.”
Did you try using bulk replace ?
As suggested here : https://github.com/github/gh-ost/issues/454, the binary log application is not optimized for network round trips and for throughput.
It does not use multiple executes in prepared statements and it does not use bulk insert / replace. It is also very sensitive to the location of the gh-ost process so it would not work well if the master and slave are on different data centers.