
This blog was originally published in February 2017 and was updated in September 2023.
In this blog post, I provide an in-depth introduction to MySQL Replication, answering what it is, how it works, its benefits and challenges, as well as reviewing some of the MySQL replication concepts that are part of the MySQL environment (and Percona Server for MySQL specifically). I will finish by also clarifying some of the common misconceptions people have about replication and how Percona can help.
Since I’ve been working on the Solution Engineering team, I’ve noticed that – although information is plentiful – replication is often misunderstood or incompletely understood.
MySQL replication is a process in which data from a primary MySQL database is copied and sent to one or more secondary databases, known as replicas.
Replication guarantees information gets copied and purposely populated into another environment instead of only stored in one location (based on the transactions of the source environment).
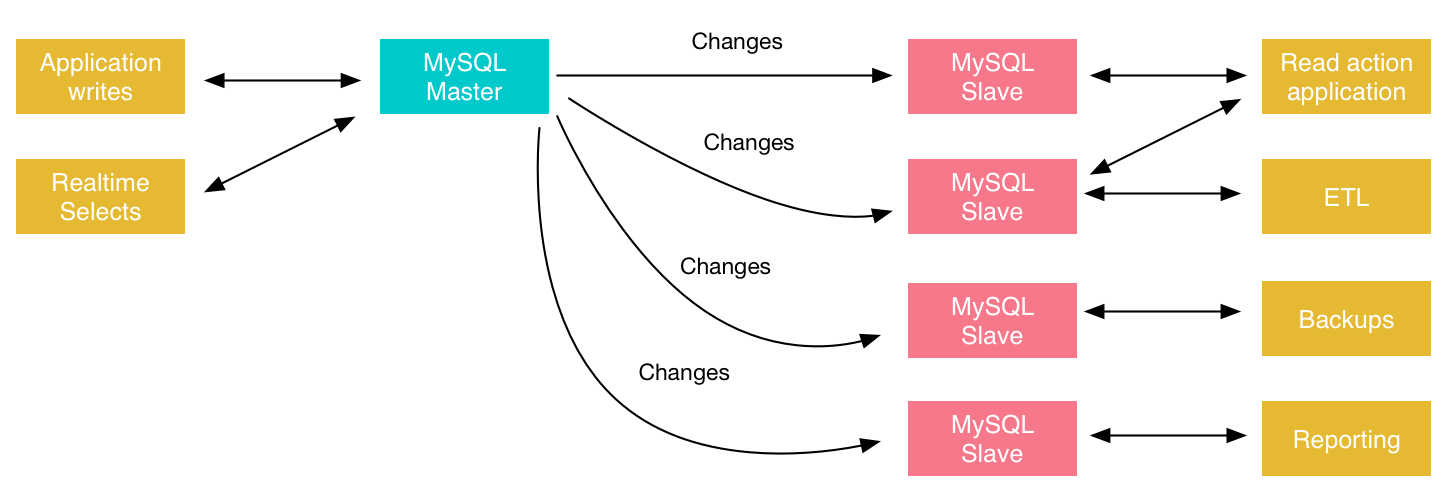
The idea is to use secondary servers on your infrastructure for either reads or other administrative solutions. The below diagram shows an example of a MySQL replication environment.
In this section, we will cover the essential aspects of implementing MySQL replication:
Prerequisites and Requirements:
Setting Up MySQL Replication – Step by Step:
MySQL replication provides high availability, load balancing, and data redundancy, enhancing system reliability. It also enables geographically distributed databases for disaster recovery. However, it’s important to consider potential downsides, including increased complexity in managing replicas, the potential for replication lag, and the need for monitoring and maintenance to ensure consistency and reliability across replicas.
There are many advantages of MySQL replication, but a few highlights include the enhancement of scalability by allowing read-intensive workloads to be distributed across multiple replicas, offloading a primary database server, and improving overall performance. Replication also provides for data availability by enabling failover to a replica in case the primary server becomes unavailable.
Lastly, in the event of a catastrophic scenario, data and databases can be quickly recovered, as replication provides for geographically dispersed duplicates of data.
Despite all the benefits, there are some potential drawbacks associated with MySQL replication one can face. One very common issue is data consistency, especially in setups with high write activity. Replicas may lag behind the primary server, impacting any applications that depend on real-time data.
Another concern is the risk of single points of failure. If the primary server experiences a failure, the entire replication process could be disrupted. Implementing the failover mechanisms discussed earlier can mitigate this risk.
Regarding security, data transmitted between the primary and replica servers may be vulnerable if encryption and access controls are not correctly configured.
You actually have several different choices:
Asynchronous replication means that the transaction is completed in the local environment completely and is not influenced by the replicas themselves.
After completion of its changes, the primary populates the binary log with the data modification or the actual statement (the difference between row-based replication or statement-based replication – more on this later). This dump thread reads the binary log and sends it to the replica IO thread. The replica places it in its own preprocessing queue (called a relay log) using its IO thread.
The replica executes each change on the replica’s database using the SQL thread.

Semi-synchronous replication means that the replica and the primary communicate with each other to guarantee the correct transfer of the transaction. The primary only populates the binlog and continues its session if one of the replicas provides confirmation that the transaction was properly placed in one of the replica’s relay logs.
Semi-synchronous replication guarantees that a transaction is correctly copied, but it does not guarantee that the commit on the replica actually takes place.
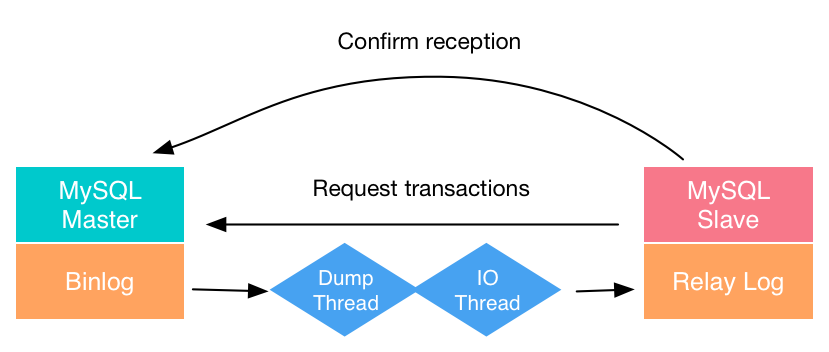
Important to note is that semi-sync replication makes sure that the primary waits to continue processing transactions in a specific session until at least one of the replicas has ACKed the reception of the transaction (or reaches a timeout). This differs from asynchronous replication, as semi-sync allows for additional data integrity.
Remember that semi-synchronous replication impacts performance because it needs to wait for the round trip of the actual ACK from the replica.
This new concept was introduced in the MySQL Community Edition 5.7 and was GA’ed in MySQL 5.7.17. It’s a rather new plugin build for virtual synchronous replication.
Whenever a transaction is executed on a node, the plugin tries to get consensus with the other nodes before returning it completed back to the client. Although the solution is a completely different concept compared to standard MySQL replication, it is based on the generation and handling of log events using the binlog.
Below is an example architecture for Group Replication.

Another solution that allows you to replicate information to other nodes is Percona XtraDB Cluster. This solution focuses on delivering consistency and also uses a certification process to guarantee that transactions avoid conflicts and are performed correctly.
In this case, we are talking about a clustered solution. Each environment is subject to the same data, and there is communication between nodes to guarantee consistency.
Percona XtraDB Cluster has multiple components:
This solution is virtually synchronous, which is comparable to Group Replication. However, it also has the capability to use multi-primary replication. Solutions like Percona XtraDB Cluster are a component to improve the availability of your database infrastructure.

Learn how to optimize your database setup for high availability with our ebook, “Percona Distribution for PostgreSQL: High Availability With Streaming Replication.” Read it here!
With statement-based replication, the SQL query itself is written to the binary log. For example, the exact same INSERT/UPDATE/DELETE statements are executed by the replica.
There are many advantages and disadvantages to this system:
Row-based replication is the default choice since MySQL 5.7.7, and it has many advantages. The row changes are logged in the binary log, and it does not require context information. This removes the impact of non-deterministic queries.
Some additional advantages are:
And, of course, some disadvantages:
Ensuring high availability in MySQL replication is important for uninterrupted database access, and several strategies can be used to achieve this goal. One approach is the implementation of failover mechanisms. Failover ensures that if the primary MySQL server becomes unavailable due to hardware failure or another issue, the system seamlessly switches to a standby replica. Setting up failover mechanisms can be accomplished using load balancers or proxy servers that continuously monitor the health of the primary server. When a problem is detected, these tools automatically redirect traffic to a standby replica.
Semi-synchronous replication is another technique that plays a vital role in ensuring data consistency in high-availability MySQL setups. This approach requires acknowledgment from at least one replica before a transaction is considered committed on the primary server, ensuring that data changes are safely replicated to at least one replica before being confirmed on the primary server. This reduces the risk of data loss in the event of a primary server failure. By prioritizing data consistency over raw performance, semi-synchronous replication provides an added layer of protection against data discrepancies, making it a valuable feature in high-availability configurations where maintaining data integrity is critical.
Discover high-availability strategies in our eBook, “Percona Distribution for MySQL: High Availability With Group Replication.” Read it now!
Standard asynchronous replication is not a synchronous cluster. Keep in mind that standard and semi-synchronous replication do not guarantee that the environments are serving the same dataset. This is different when using Percona XtraDB Cluster, where every server actually needs to process each change. If not, the impacted node is removed from the cluster. Asynchronous replication does not have this fail safe. It still accepts reads while in an inconsistent state.
Theoretically, the environments should be comparable. However, there are many parameters influencing the efficiency and consistency of the data transfer. As long as you use asynchronous replication, there is no guarantee that the transaction correctly took place. You can circumvent this by enhancing the durability of the configuration, but this comes at a performance cost. You can verify the consistency of your primary and replicas using the pt-table-checksum tool.
Replication is a great solution for having an accessible copy of the dataset (e.g., reporting issues, read queries, generating backups). This is not a backup solution, however. Having an offsite backup provides you with the certainty that you can rebuild your environment in the case of any major disasters, user error or other reasons (remember the Bobby Tables comic). Some people use delayed replicas. However, even delayed replicas are not a replacement for proper disaster recovery procedures.
Although you’ve potentially improved the availability of your environment by having a secondary instance running with the same dataset, you still might need to point the read queries towards the replicas and the write queries to the primary. You can use proxy tools, or define this functionality in your own application.
Replication has only minor performance impacts on your primary. Peter Zaitsev has an interesting post on this here, which discusses the potential impact of replicas on the primary. Keep in mind that writing to the binary log can potentially impact performance, especially if you have a lot of small transactions that are then dumped and received by multiple replicas.
There are, of course, many other parameters that might impact the performance of the actual primary and replica setup.
To ensure customer satisfaction and meet the demands of applications requiring high availability (HA) and extensive usage, database architecture and deployment must be carefully considered. This often involves achieving remarkable uptime levels, such as the coveted “five nines” (99.999%) availability.
To delve deeper into this topic and explore Percona’s recommendations for HA architecture and deployment, we invite you to download our white paper. Inside, you’ll find a technical overview of a solution designed to offer exceptional availability, particularly tailored for scenarios involving high read and write applications.
Learn More: Download our white paper, High Availability Solutions with Percona Distribution for MySQL, for free!
MySQL replication is a process where data from a primary MySQL database is duplicated and sent to one or more secondary databases called replicas.
MySQL replication works by recording changes to the data on the primary server’s binary log and then replaying those changes on replica servers to keep them in sync.
MySQL replication is used for various purposes, including improving database performance, providing data redundancy for disaster recovery, and distributing database load for scaling.
There are different types of MySQL replication, including asynchronous and synchronous replication, statement-based and row-based replication, and group replication for high availability.
In general, it’s best to replicate between the same or compatible MySQL versions to ensure compatibility and consistency. However, some limited cross-version replication may be possible with certain configurations and precautions.





We have master-slave replication in place utilizing GTID approach; the use case we have is to configure this replication such that some records that exist in some tables on the master, which meet specific criteria do not get replicated to the salve; is this possible?
Thanks