
 I’m pleased to announce the latest Percona Server for MongoDB feature: Percona Memory Engine for MongoDB.
I’m pleased to announce the latest Percona Server for MongoDB feature: Percona Memory Engine for MongoDB.
Everybody understands that memory is much faster than disk – even the fastest solid state storage can’t compete with it. As such the choice for the most demanding workloads, where performance and predictable latency are paramount, is in-memory computing.
MongoDB is no exception. MongoDB can benefit from a storage engine option that stores data in memory. In fact, MongoDB introduced it in the 3.2 release with their In-Memory Storage Engine. Unfortunately, their engine is only available in their closed source MongoDB Enterprise Edition. Users of their open source MongoDB Community Edition were out of luck. Until now.
At Percona we strive to provide the best open source MongoDB variant software with Percona Server for MongoDB. To meet this goal, we spent the last few months working on an open source implementation of an in-memory storage engine: introducing Percona Memory Engine for MongoDB!
Percona Memory Engine for MongoDB provides the same performance gains as the current implementation of MongoDB’s in-memory engine. Both are based on WiredTiger, but optimize it for cases where data fits in memory and does not need to be persistent.
To make migrating from MongoDB Enterprise Edition to Percona Server for MongoDB as simple as possible, we made our command line and configuration options as compatible as possible with the MongoDB In-Memory Storage Engine.
Look for more blog posts showing the performance advantages of Percona Memory Engine for MongoDB compared to conventional disk-based engines, as well as some use cases and best practices for using Percona Memory Engine in your MongoDB deployments. Below is a quick list of advantages that in-memory processing provides:
From a developer standpoint, Percona Memory Engine addresses several practical use cases:
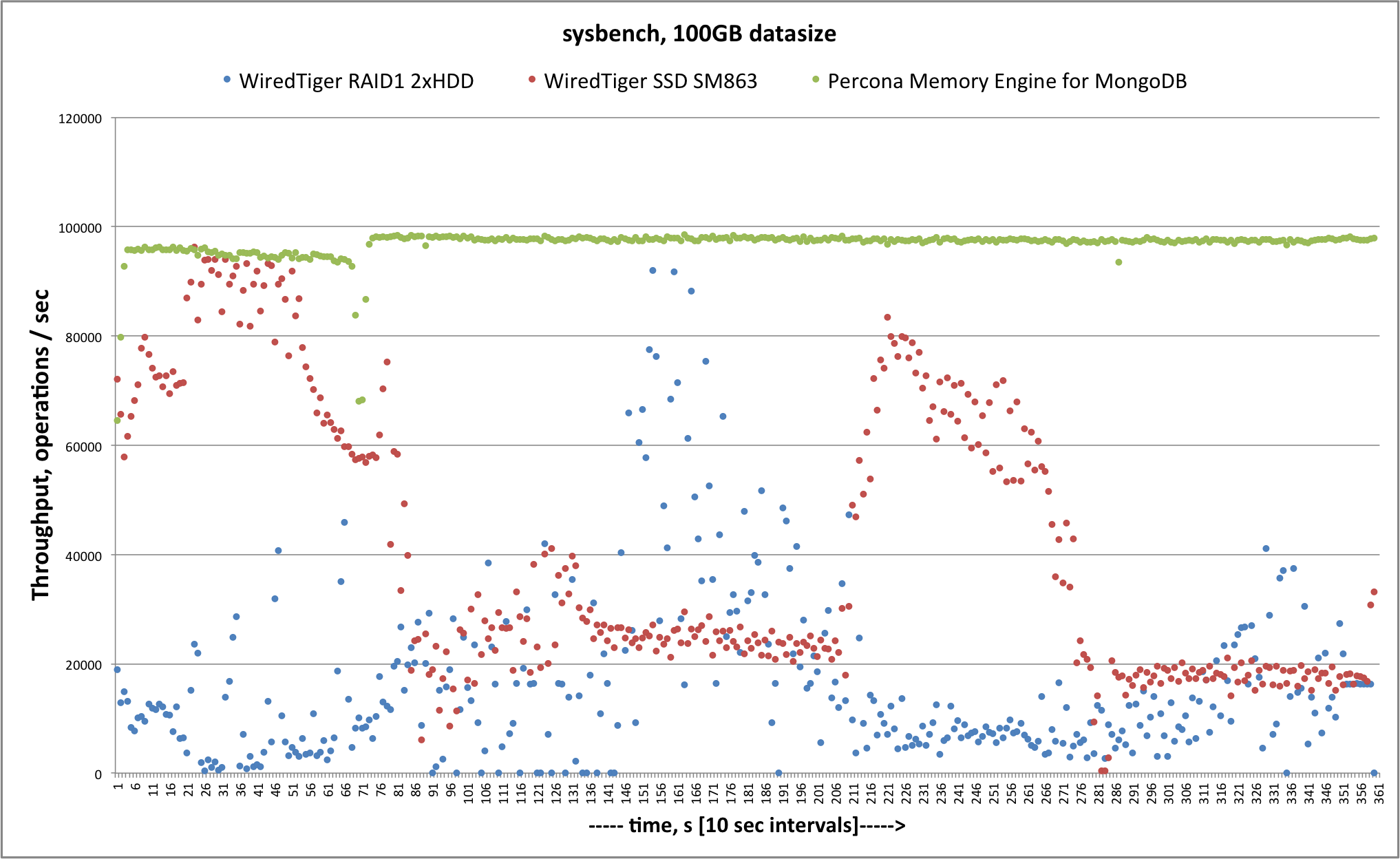
I’m including a simple benchmark result for very intensive write workloads that compares Percona Memory Engine and WiredTiger. As you can see, you can get dramatically better performance with Percona Memory Engine!
Download Percona Memory Engine for MongoDB here.
Resources
RELATED POSTS





I prefer a less synthetic workload (linkbench) comparing regular WT vs in-memory WT for a database that fits in memory in both cases. In theory, the new in-memory option shouldn’t make reads faster for that setup, but a few stalls in dirty page writeback in WT can also impact stalls. Reporting p99 latencies will make the benefit obvious.
Mark,
We will do more benchmarks (as well as Performance improvements). The main benefit I see is for write intensive workloads which either overtake the IO capacity for flushing or have high latency due to checkpoint activity. Thought good point on how flushing impacts things. Good way to see something like this is to inject some medium write activity and to measure read latencies separately.
Is it possible to have a replSet where the Secondary is using the in-memory storage engine and the Primary is using wiredTiger, plus an arbiter? Doing so, reads (such as time consuming aggregations) could be run much faster on the Secondary. If one node crashes, data ist still on the other node and could be restored within a short time.
Hi Kay,
Yes! You can absolutely do this how ever you need to make sure and do some tweaks to the replSet configuration
1) You will want to make sure the WT node is given priority unless your using w:majority
2) You would want to consider adding tags to the nodes ( See replSet tagging on read vs write concern https://docs.mongodb.com/manual/tutorial/configure-replica-set-tag-sets/#differences-between-read-preferences-and-write-concerns)
Personally I would suggest a 3rd data node where you could have 2 WiredTiger nodes and hide the memory node unless a query is specifically trying to use it’s tag. Doing less than this really makes you only have 1 real full data node which is very risky and negates all the HA work that has been done in Mongo.
If you want to talk more feel free to send a notification to @dbmurphy_data or @Percona on twitter and I can talk to you about the pros/cons of each approach. I understand its a complicated task and I am talking in very general terms not knowing your exact situation.
Thanks David for the helpful information! I’ll definitevely give it a try after my holidays in the next weeks. We have different clusters and replSets, all with different usage patterns. I’m quite sure that the in-memory storage engine might be a game changer. I’ll keep you up to date.
Is there a plan to provide the In memory storage engine as a storage engine that can be used with MongoDB community edition or will it be restricted to use only with ‘Percona server for MongoDB’?
Hi,
Percona Memory for MongoDB will only be available with Percona Server for MongoDB. As we offer drop-in compatibility with community edition there is no reason to try to maintain the separate plugin.
Thanks!