
 In this blog post, we’ll discuss how using Prometheus can help with monitoring MongoDB response time. I am currently comparing the performance of different storage engines on Percona Server for MongoDB, using a slightly customized version of Tim Callaghan’s sysbench-mongodb. Since I’m interested in measuring response time for database operations, I created a very simple exporter of response time data for Prometheus.
In this blog post, we’ll discuss how using Prometheus can help with monitoring MongoDB response time. I am currently comparing the performance of different storage engines on Percona Server for MongoDB, using a slightly customized version of Tim Callaghan’s sysbench-mongodb. Since I’m interested in measuring response time for database operations, I created a very simple exporter of response time data for Prometheus.
My first approach to measuring MongoDB response time was inspired by Ignacio Nin’s work on tcprstat, some years ago – and by the way the VividCortex query agent works (which is not surprising, since, to the best of my knowledge, Baron inspired tcprstat in the first place).
With this in mind, I created mongo-response-time, which performs the only function of printing to stdout the response time of every mongodb query seen on the wire, along with a timestamp up to the second. My thanks go to the programmers of Facebook’s Go projects, as their code helped me hit the ground running.
As a first approach this was useful enough for my needs, and here is an example of a basic graph created from data generated by it: 
I had to use a log scale as otherwise the graph was just a thick bar near the bottom, and a few outliers above. This is already useful, but it does not scale well. As an example, a sysbench-mongodb run of about an hour produced a csv file with a little over eight million data points. Larger rounds (like 24 hours) are just too difficult to handle with R (in one case, even though I had enough memory in my box to hold more than three copies of the file, read.csv aborted after running out of memory – if this happens to you, I suggest the use of RMySQL instead, which seems more memory-efficient than read.csv for ingesting large amounts of data).
For a second approach, I decided to live with less fidelity and settled for some quantiles and a max. For this, I created a simple Prometheus exporter that exposes 0.5, 0.9 and 0.99 quantiles, and also the max response time for every five second period.
With it, I was able to visualize the MongoDB response time data in Grafana in a way that is affordable and good enough for my needs, as can be seen in the following graphs: 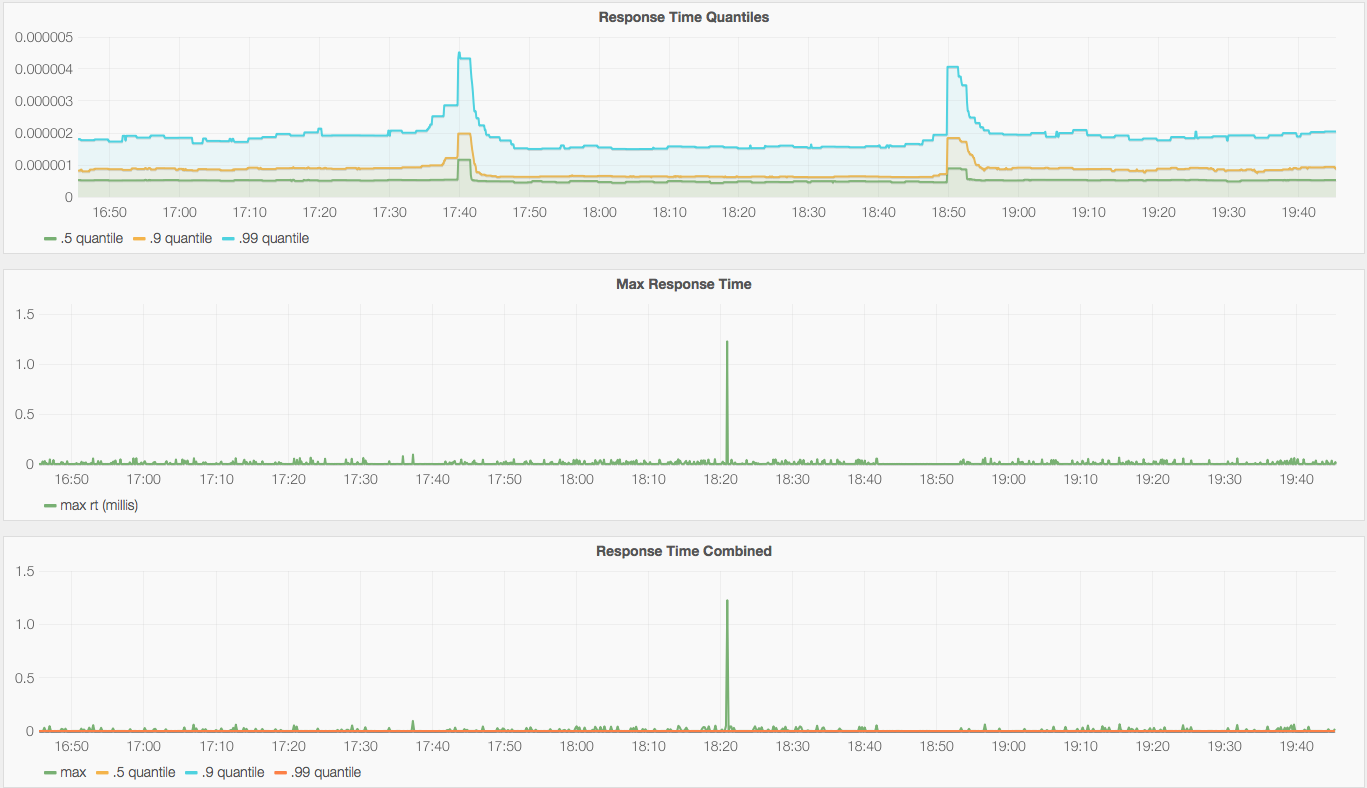
The quantiles are calculated on the client side, using the Summary type from Prometheus’ Go client. The exporter also provides the same quantiles, but through a Histogram, which has the advantage of being more lightweight on clients. I decided to use the Summary as a source for this graph as the impact on the machine seems negligible for now, and I do find its data a bit more reliable (if I compare to calculating quantiles per periods analyzing the full data set in R). You can see how the max (a Gauge, glad you asked!) is useful to have, as it lets you find out about outliers that even the .99 quantile misses (which is expected, by the way).
If you want to try this out, you can find darwin and linux binaries here, and if you hit any problems, please reply here or email me directly at fernando (dot) ipar at Percona’s domain.
Happy monitoring!
Resources
RELATED POSTS





Could you include comparison with original TokuMX – 1.5 or 2.0 for comparison. Very interested in whatever overhead the storage engine API is creating. TokuMX was optimized in other ways than just the storage engine – so before we can consider a switch we really need to understand how they compare.
‘@Kresten: I am keeping the benchmark I’m currently worked on focused on Storage Engine comparison using the API. I agree that comparing TokuMX to see the overhead of the API is very interesting, but the experiment needs to be properly designed so that the results are meaningful. It is on my list now though 🙂
Hey guis I’m trying to use this to monitor response time for my MongoDB instance. The problem is I don’t know how to use this exporter, I’m using Ubuntu for OS. I tried with command make, but there are some Go Lang errors which I’m not familiar with and I’m not sure how to solve this.
Can you tell me step by step how to run this exporter? Since I’m new to Ubuntu and I know nothing about Go Lang.