 Recently I was talking with Tim Sharp, one of my colleagues from our Technical Account Manager team about MongoDB’s scalability. While doing some quick training with some of the Percona team, Tim brought something to my attention: he mentioned to me that several customers he has been in contact with have been telling him that “MongoDB doesn’t scale!” MongoDB’s scalability was in question? My response was, “Is that a joke?”
Recently I was talking with Tim Sharp, one of my colleagues from our Technical Account Manager team about MongoDB’s scalability. While doing some quick training with some of the Percona team, Tim brought something to my attention: he mentioned to me that several customers he has been in contact with have been telling him that “MongoDB doesn’t scale!” MongoDB’s scalability was in question? My response was, “Is that a joke?”
Coming from MySQL users, I was confounded given MongoDB’s native ability to easily scale horizontally. However, I quickly realized that they may not have been referencing its ability to shard. So I decided to take a step back and look at the history of MongoDB, not just its present form, to get to the bottom of this. Here’s my analysis:
The History
From MongoDB’s inception, it was obvious that it was a developers database – and thus a vast majority of the development resources went into functionality (not performance). Nowhere was this more apparent than with the MMAP storage engine. From what I can tell, this is the root of the belief that MongoDB doesn’t scale. And, for good reason too! From MongoDB v1.0, which was released on August 27, 2009 (according to Wikipedia) and stretching for three years (all the way until v2.2 released on August 28, 2012), there was a per-process lock. That means that you could only have one operation being performed on a single MongoDB server at a time. To put that into context, this is useful for a website that has only one user on it, but not something that is generally worthy of my least favorite buzzword, “webscale.” Obviously, they changed that with v2.2 and introduced an extremely mature database-level lock (note the sarcasm). In most users eyes, including mine, this was hardly a revelation. The lack of “useability” of a database-level lock is especially apparent in MongoDB, due the fact that it doesn’t support the ability to join data from separate collections (think tables in RDBMS), let alone databases. Don’t get me wrong, there were/are thousands of users making MMAP work for them – but, IMO, at a significant cost!
Finally, at MongoDB World in June of 2014, it looked like there was finally going to be some major vertical scalability changes. These were to come in the form of a document-level locking scheme for the MMAP storage engine and a new storage engine API. There was even a demo to show MMAPs new thread scaling and throughput capabilities. To make a long story short, that version of MMAP never made it out of the cage, but through a key acquisition, WiredTiger did. And with it, the dawn of the MongoDB document-level lock had come.
To wrap up the last two paragraphs in a simple statement: MongoDB prior version 3.0 relied much too heavily on horizontal scalability and, almost completely, ignored the need for increased single server efficiency. For a database that was developed to service the changing needs of the web/application driven businesses (i.e. highly concurrent), this was confusing, if not maddening. Furthermore, during a critical period of new user attraction, potential long term users of MongoDB were disenfranchised because they viewed the lack of vertical scalability as frustratingly inefficient; a multiplier of infrastructure complexity. Now that I look back, it’s no wonder MongoDB has a reputation for scaling problems.
The Present
As I previously mentioned, MongoDB, Inc., acquired a company called WiredTiger, and with it the WiredTiger storage engine. This finally ushered in a modern locking scheme and a greatly enhanced throughput (vertical scalability). WiredTiger also has the ability to support compression for greater space efficiency (the MMAP engine is also a storage hog). However, the storage engine API lets anyone build a storage engine, which leads to more options . . .
A Contender Enters the Ring
To start at the end, á la the movie Memento, on December 14th, 2015 Percona released the GA version of Percona Server for MongoDB, an enhanced, high-performance distribution of MongoDB. It was designed to build on the success of their purely FOSS (free and open source software) Percona Server for MySQL. Now that I’ve spoiled it, let’s take a brief look at how we got there.
Enter Tokutek
In the beginning of 2015, Percona acquired the company that I was working for: Tokutek. With it (and me) came a “futuristic” fork of MongoDB called TokuMX. TokuMX was, as far as I know, the first implementation of a document-level lock and write optimized storage engine (Fractal Tree) in MongoDB (not to mention compression and advanced features). The effect was impressive, with customers regularly reporting upwards of 10-20x the performance with compression ratios of 6:1 on low end and 32:1 for highly repetitive data – talk about enhanced scale! However, maintaining a fork with such an advanced feature set (on top of what MongoDB included) proved difficult to maintain given that a new version of MongoDB was being released approximately every six months, and code inter-dependencies for TokuMX were complex. Our customers began asking for greater parity with upstream . . .
When the storage engine API came along, it was a great revelation for our customers. If we went back to the conceptual stages of TokuMX at Tokutek, we would have preferred to hook into a storage engine API just like we did with our first product, TokuDB for MySQL (now on Percona Server for MySQL). However it was not something that MongoDB, Inc. (then 10gen) was interested in investing in. With the birth of the MongoDB v3.0 storage engine API, we can plug the Fractal Tree in and maintain greater parity with upstream, while providing high performance and high compression all with the latest and greatest MongoDB features.
Social Networking Pushes Open-Source
As you may know, Facebook has a significant investment in MongoDB for their infrastructure and a database engine that they’ve developed called RocksDB. RocksDB was developed off of LevelDB and, if memory serves me right, first implemented as an engine for MySQL. Facebook later saw the value in implementing RocksDB in MongoDB so that they could increase the efficiency of their infrastructure. This is also the first implementation of an LSM data structure in MongoDB. LSM storage engines can provide impressive performance and compression for high throughput, insert-heavy workloads.
MongoRocks (as it’s called for MongoDB), has the full weight of the Facebook development team and is vetted through what we know to be a serious workload. Also, Percona is the only company partnering with Facebook to offer commercial level support, pre-built and tested binaries/packages and consulting for MongoRocks.
The latest version of Percona Server for MongoDB (full MongoDB Community Code plus PerconaFT and MongoRocks pre-compiled in, along with Enterprise features) can be downloaded here.
The Proof is in the Pudding
Enough with the talk. Numbers don’t lie, so let me show you how much the vertical scalability has improved from MongoDB v2.2 to MongoDB v3.0. I’ll even break it out by storage engine. These numbers are meant to be relative, and meant to show the relative difference in performance between the versions (and storage engines for v 3.0). However, for the sake of transparency, they were done with iibench simulating a pure insert workload.
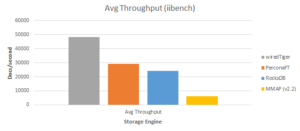
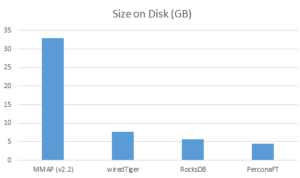
The graph below shows the huge space savings one can achieve with the new storage engines.
What Should You Conclude?
To put it bluntly, MongoDB’s performance has improved dramatically. The great thing is, the storage engine API hasn’t even matured yet. Currently, it’s one of the biggest performance limiters of the storage engines. As it matures, storage engines, and thus MongoDB, should get faster. As always, please do not take these numbers as gospel, they were created with a simple workload meant to only show the difference in vertical scalability. Your evaluation should be done with a workload that simulates your application’s behavior in order to fully understand how MongoDB will perform in your environment. For a more detailed discussion about the features and workload suitability of each storage engine, take a look at the blog series that Dave Avery and I co-wrote: MongoDB revs you up (follow the links to see all four posts).
In short: If you tried MongoDB prior to v 2.6, you should circle back and re-evaluate it (try PSMDB for more choice).
For a more detailed look at the performance of the storage engines available in Percona Server for MongoDB, take a look at Vadim Tkachenko’s blog post.
Learn more about Percona Server for MongoDB
Resources
RELATED POSTS





