
There are cases where we need to implement MySQL partitioning, or at least test if it is an option to solve an issue. However, how are we able to test it when the table on our production environment has hundreds of millions of rows, several composite indexes and/or the size on disk is hundreds of gigabytes?
Testing environments usually don’t have all the data that production has and if they have, probably you are not testing all the use-cases at a database level. Therefore, is it possible to test MySQL Partitioning on production impacting as less as possible?
When we execute pt-online-schema-change, it creates a table, triggers, and then copies the data. As we are going to test partitioning we are going to need both tables – with and without partitioning – and we are going to use triggers to keep both tables consistent. A good thing about changing a table to use partitioning is that, usually, you won’t need to change the structure of the row, which means that you are able to use practically the same statement to insert, update or delete on both tables.
Let’s suppose that we have this sysbench table:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `sbtest` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB; |
If we want to partition it, we execute:
|
1 |
ALTER TABLE percona.sbtest PARTITION BY HASH(id) partitions 4; |
We will execute pt-online-schema-change like this:
|
1 2 3 |
pt-online-schema-change h=localhost,D=percona,t=sbtest --recursion-method none --execute --alter "PARTITION BY HASH(id) partitions 4" |
But as we are going to test partitioning, we want to:
That is why we are going to execute pt-online-schema-change like this:
|
1 2 3 4 |
pt-online-schema-change h=localhost,D=percona,t=sbtest --recursion-method none --execute --no-swap-tables --no-drop-old-table --no-drop-new-table --no-drop-triggers --alter "PARTITION BY HASH(id) partitions 4" |
At the end we are going to have 2 tables, sbtest, which is not partitioned and _sbtest_new which is partitioned:
![]()
The next step that pt-osc was going to do was to swap the tables, but we used –no-swap-tables, so we are going to do it manually. But first, we are going to add the triggers to _sbtest_new, so that it can load the data to sbtest, which will be renamed to _sbtest_old. However, we need to create the trigger now, which are going to be very similar to the ones that already exists, but with the table name _sbtest_old, and that will end up in an error as _sbtest_old doesn’t exist yet. That is why we create the triggers handling the error:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
delimiter // CREATE DEFINER=`root`@`%` TRIGGER `pt_osc_percona__sbtest_new_ins` AFTER INSERT ON `percona`.`_sbtest_new` FOR EACH ROW begin DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' BEGIN END; REPLACE INTO `percona`.`_sbtest_old` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`); end; // CREATE DEFINER=`root`@`%` TRIGGER `pt_osc_percona__sbtest_new_upd` AFTER UPDATE ON `percona`.`_sbtest_new` FOR EACH ROW begin DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' BEGIN END; REPLACE INTO `percona`.`_sbtest_old` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`); end; // CREATE DEFINER=`root`@`%` TRIGGER `pt_osc_percona__sbtest_new_del` AFTER DELETE ON `percona`.`_sbtest_new` FOR EACH ROW begin DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' BEGIN END; DELETE IGNORE FROM `percona`.`_sbtest_old` WHERE `percona`.`_sbtest_old`.`id` <=> OLD.`id`; end; // delimiter ; |
The schema is now:
![]()
We are going to create a table _sbtest_diff which will be the table that is going to be renamed to _sbtest_new. It doesn’t need to have indexes or be partitioned, so that it is simple:
|
1 2 3 4 5 6 7 |
CREATE TABLE `_sbtest_diff` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`) ) ENGINE=InnoDB; |
At this point we are able to swap the tables, the command to execute will be:
|
1 |
RENAME TABLE sbtest TO _sbtest_old, _sbtest_new TO sbtest, _sbtest_diff TO _sbtest_new; |
The rename table will do this:
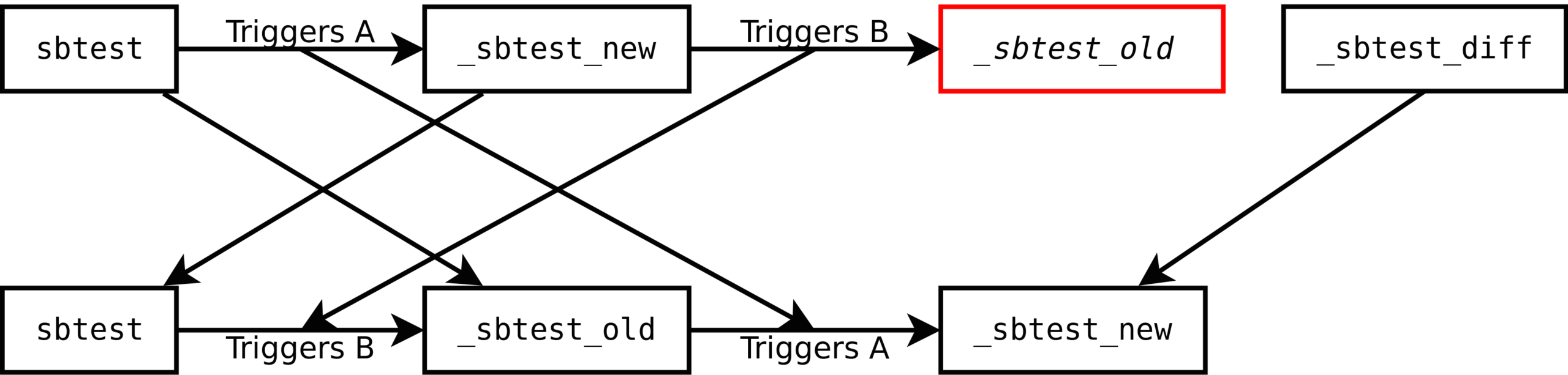
Now you can test performance on the table. If we want to return to the previous stage, we just execute:
|
1 |
RENAME TABLE _sbtest_new TO _sbtest_diff, sbtest TO _sbtest_new, _sbtest_old TO sbtest; |
With this two “RENAME TABLE” commands, we are able to back and forth to partition and non-partition table. Once you are satisfied with your testing, the remaining task is to clean up the triggers and the tables. At the end, there are 2 possible outcomes:
|
1 2 3 4 5 |
DROP TRIGGER `pt_osc_percona__sbtest_new_ins`; DROP TRIGGER `pt_osc_percona__sbtest_new_upd`; DROP TRIGGER `pt_osc_percona__sbtest_new_del`; DROP TABLE _sbtest_new; DROP TABLE _sbtest_old; |
|
1 2 3 4 5 |
DROP TRIGGER `pt_osc_percona_sbtest_ins`; DROP TRIGGER `pt_osc_percona_sbtest_upd`; DROP TRIGGER `pt_osc_percona_sbtest_del`; DROP TABLE _sbtest_new; DROP TABLE _sbtest_old; |
Conclusion:
With this procedure, you will have both tables – with and without partitioning – synchronized and you will be able to swap between them until you decide to keep one of them.





very helpful!
How does ‘delete’ trigger work if we were to truncate one of the partitions e.g.
alter table _sbtest_new truncate partition p0;
Sounds like a good plan for doing ‘side-by-side’ performance testing. Please write up your findings together with the schema and the SELECTs that show that things got faster (or slower).
I would be especially interested to see a use case where BY HASH is useful for performance. (I have not found one yet.)
Nice article.
One correction in blog:
AFTER “We decided to keep the original table, which implies execute:”
There will be no _sbtest_old table to drop, change it to _sbtest1_diff.
Thanks!