
Ever since MySQL replication has existed, people have dreamed of a good solution to automatically split read from write operations, sending the writes to the MySQL master and load balancing the reads over a set of MySQL slaves. While if at first it seems easy to solve, the reality is far more complex.
First, the tool needs to make sure it parses and analyses correctly all the forms of SQL MySQL supports in order to sort writes from reads, something that is not as easy as it seems. Second, it needs to take into account if a session is in a transaction or not.
While in a transaction, the default transaction isolation level in InnoDB, Repeatable-read, and the MVCC framework insure that you’ll get a consistent view for the duration of the transaction. That means all statements executed inside a transaction must run on the master but, when the transaction commits or rollbacks, the following select statements on the session can be again load balanced to the slaves, if the session is in autocommit mode of course.
Then, what do you do with sessions that set variables? Do you restrict those sessions to the master or you replay them to the slave? If you replay the set variable commands, you need to associate the client connection to a set of MySQL backend connections, made of at least a master and a slave. What about temporary objects like with “create temporary table…”? How do you deal when a slave lags behind or what if worse, replication is broken? Those are just a few of the challenges you face when you want to build a tool to perform read/write splitting.
Over the last few years, a few products have tried to tackle the read/write split challenge. The MySQL_proxy was the first attempt I am aware of at solving this problem but it ended up with many limitations. ScaleARC does a much better job and is very usable but it stills has some limitations. The latest contender is MaxScale from MariaDB and this post is a road story of my first implementation of MaxScale for a customer.
Let me first introduce what is MaxScale exactly. MaxScale is an open source project, developed by MariaDB, that aims to be a modular proxy for MySQL. Most of the functionality in MaxScale is implemented as modules, which includes for example, modules for the MySQL protocol, client side and server side.
Other families of available modules are routers, monitors and filters. Routers are used to determine where to send a query, Read/Write splitting is accomplished by the readwritesplit router. The readwritesplit router uses an embedded MySQL server to parse the queries… quite clever and hard to beat in term of query parsing.
There are other routers available, the readconnrouter is basically a round-robin load balancer with optional weights, the schemarouter is a way to shard your data by schema and the binlog router is useful to manage a large number of slaves (have a look at Booking.com’s Jean-François Gagné’s talk at PLMCE15 to see how it can be used).
Monitors are modules that maintain information about the backend MySQL servers. There are monitors for a replicating setup, for Galera and for NDB cluster. Finally, the filters are modules that can be inserted in the software stack to manipulate the queries and the resultsets. All those modules have well defined APIs and thus, writing a custom module is rather easy, even for a non-developer like me, basic C skills are needed though. All event handling in MaxScale uses epoll and it supports multiple threads.
Over the last few months I worked with a customer having a challenging problem. On a PXC cluster, they have more than 30k queries/s and because of their write pattern and to avoid certification issues, they want to have the possibility to write to a single node and to load balance the reads. The application is not able to do the Read/Write splitting so, without a tool to do the splitting, only one node can be used for all the traffic. Of course, to make things easy, they use a lot of Java code that set tons of sessions variables. Furthermore, for ISO 27001 compliance, they want to be able to log all the queries for security analysis (and also for performance analysis, why not?). So, high query rate, Read/Write splitting and full query logging, like I said a challenging problem.
We experimented with a few solutions. One was a hardware load balancer that failed miserably – the implementation was just too simple, using only regular expressions. Another solution we tried was ScaleArc but it needed many rules to whitelist the set session variables and to repeat them to multiple servers. ScaleArc could have done the job but all the rules increases the CPU load and the cost is per CPU. The queries could have been sent to rsyslog and aggregated for analysis.
Finally, the HA implementation is rather minimalist and we had some issues with it. Then, we tried MaxScale. At the time, it was not GA and was (is still) young. Nevertheless, I wrote a query logging filter module to send all the queries to a Kafka cluster and we gave it a try. Kafka is extremely well suited to record a large flow of queries like that. In fact, at 30k qps, the 3 Kafka nodes are barely moving with cpu under 5% of one core. Although we encountered some issues, remember MaxScale is very young, it appeared to be the solution with the best potential and so we moved forward.
The folks at MariaDB behind MaxScale have been very responsive to the problems we encountered and we finally got to a very usable point and the test in the pilot environment was successful. The solution is now been deployed in the staging environment and if all goes well, it will be in production soon. The following figure is simplified view of the internals of MaxScale as configured for the customer:
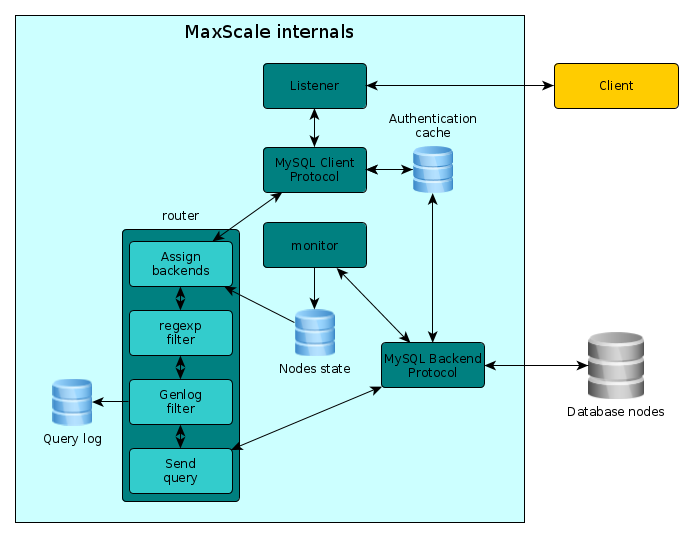
The blocks in the figure are nearly all defined in the configuration file. We define a TCP listener using the MySQL protocol (client side) which is linked with a router, either the readwritesplit router or the readconn router.
The first step when routing a query is to assign the backends. This is where the read/write splitting decision is made. Also, as part of the steps required to route a query, 2 filters are called, regexp (optional) and Genlog. The regexp filter may be used to hot patch a query and the Genlog filter is the logging filter I wrote for them. The Genlog filter will send a json string containing about what can be found in the MySQL general query log plus the execution time.
Authentication attempts are also logged but the process is not illustrated in the figure. A key point to note, the authentication information is cached by MaxScale and is refreshed upon authentication failure, the refresh process is throttled to avoid overloading the backend servers. The servers are continuously monitored, the interval is adjustable, and the server status are used when the decision to assign a backend for a query is done.
In term of HA, I wrote a simple Pacemaker resource agent for MaxScale that does a few fancy things like load balancing with IPTables (I’ll talk about that in future post). With Pacemaker, we have a full fledge HA solution with quorum and fencing on which we can rely.
Performance wise, it is very good – a single core in a virtual environment was able to read/write split and log to Kafka about 10k queries per second. Although MaxScale supports multiple threads, we are still using a single thread per process, simply because it yields a slightly higher throughput and the custom Pacemaker agent deals with the use of a clone set of MaxScale instances. Remember we started early using MaxScale and the beta versions were not dealing gracefully with threads so we built around multiple single threaded instances.
So, since a conclusion is needed, MaxScale has proven to be a very useful and flexible tool that allows to elaborate solutions to problems that were very hard to tackle before. In particular, if you need to perform read/write splitting, then, try MaxScale, it is best solution for that purpose I have found so far. Keep in touch, I’ll surely write other posts about MaxScale in the near future.
Resources
RELATED POSTS





Thanks Yves for such a rave blog !
Dipti
How does readwritesplit do against stored procedures and functions? Was this part of your evaluation?
Interesting take on it Yves. Did you look at mysql-proxy as well? I think that has everything you need, plus a lot of detail on the actual queries. You can add to it with Lua scripting as well… which doesn’t require C and recompiling.
I have a logging system, that writes to Elasticsearch, with Kibana running over it, and have peaked at 140m documents per 24 hrs… and no issues.
What kind of logging does MaxScale produce? Is it what you would expect? I am genuinely interested, as I have clients that may be interested in going that way also:
30k queries per second? What is the read/write ratio please?
Hi Jwang,
here’s for example part of the output of the “show services” of Maxscale. It is a lightly modified oltp.lua script.
Current no. of router sessions: 0
Number of queries forwarded: 3071820
Number of queries forwarded to master: 590733
Number of queries forwarded to slave: 2481087
Number of queries forwarded to all: 236294
Regards,
Yves
hi,Yves
We are using maxscale for readwritesplit recently. unfortunately, it make me some sad. the maxscale process exited abnormally sometimes. error log print below:
Fatal: MaxScale 1.2.1 received fatal signal 11. Attempting backtrace.
Commit ID: source-build System name: Linux Release string: Tencent tlinux release 2.0 (Final) Embedded library version: 5.5.46-MariaDB
Could you give me some suggestions?
thanks.
Have you solved your problem?I have the same problem
Hi Yorker,
Can you please provide detailed error log and config file at https://mariadb.atlassian.net/ in a Jira issue ? we will provide you with help.
Is you database system an M/S architect?
Thanks
also, what environment was your cluster (LAN or WAN?)
Thanks
Hi ,
As per diagram, I am little confused when the authentication cache module is going to use .
case 1: Listner ==> MySQL client protocol ==> authentication cache ==> then router ,..
Or
case 2 : Listner => MySQL Client protocol ==> router ==. MySQL Backend protocol==> Authentication cache ==>,,,,
The authentication cache is used first but an auth failure forces a resync with the backend database.