
An idea for a benchmark based on the “arrival request” rate that I wrote about in a post headlined “Introducing new type of benchmark” back in 2012 was implemented in Sysbench. However, Sysbench provides only a simple workload, so to be able to compare InnoDB with TokuDB, and later MongoDB with Percona TokuMX, I wanted to use more complicated scenarios. (Both TokuDB and TokuMX are part of Percona’s product line, in the case you missed Tokutek now part of the Percona family.)
Thanks to Facebook – they provide LinkBench, a benchmark that emulates the social graph database workload. I made modifications to LinkBench, which are available here: https://github.com/vadimtk/linkbenchX. The summary of modifications is
requestrate and send the event for execution to one of available Requester thread.
requesters) connections to database, which are idle by default, and just waiting for an incoming event to execute.
Also, I provide a Java package, ready to execute, so you do not need to compile from source code. It is available on the release page at https://github.com/vadimtk/linkbenchX/releases
So the main focus of the benchmark is the response time and its stability over time.
For an example, let’s see how TokuDB performs under different request rates (this was a quick run to demonstrate the benchmark abilities, not to provide numbers for TokuDB).
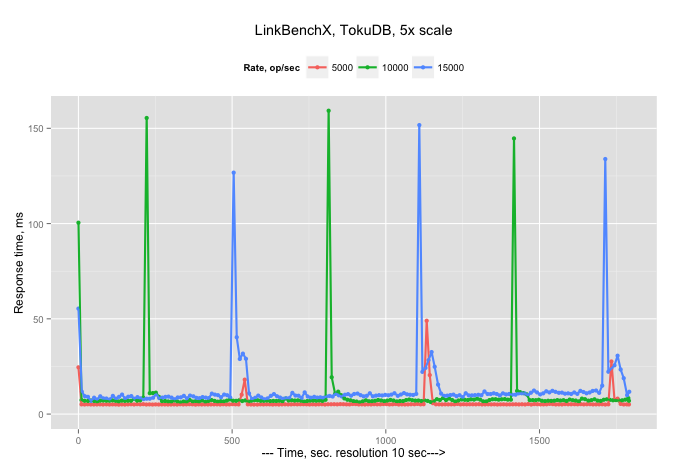
First graph is the 99% response time (in milliseconds), measured each 10 sec, for arrival rate 5000, 10000 and 15000 operations/sec:
or, to smooth spikes, the same graph, but with Log 10 scale for axe Y:
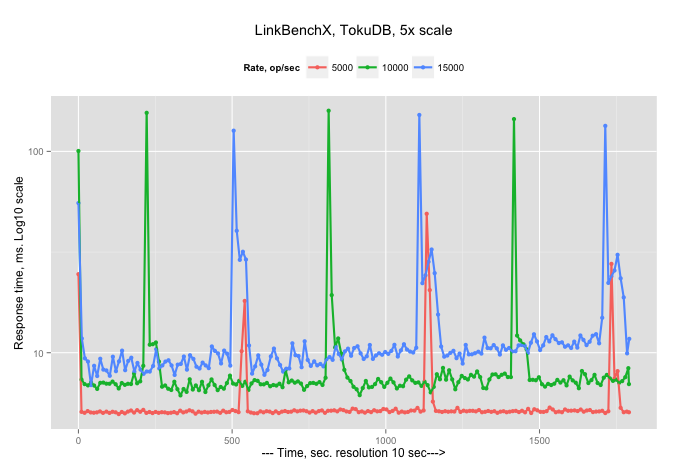
So there are two observations: the response time increases with an increase in the arrival rate (as it supposed to be), and there are periodical spikes in the response time.
And now we can graph Concurrency (how many Threads are busy working on requests)…
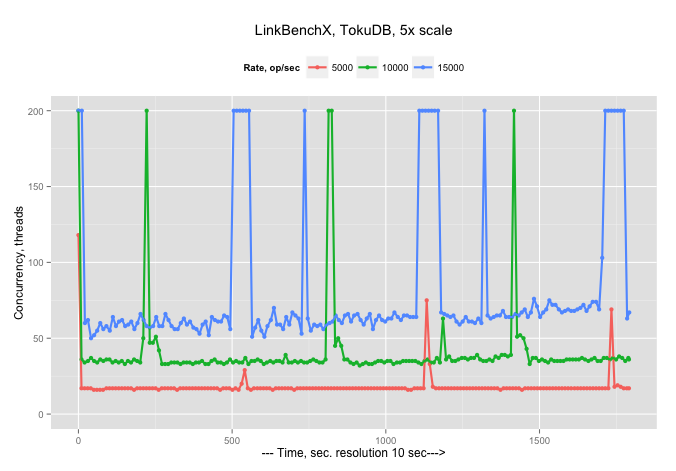
…with an explainable observation that more threads are needed to handle bigger arrival rates, and also during spikes all available 200 threads (it is configurable) become busy.
I am looking to adopt LinkBenchX to run an identical workload against MongoDB.
The current schema is simple
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
CREATE TABLE `linktable` ( `id1` bigint(20) unsigned NOT NULL DEFAULT '0', `id2` bigint(20) unsigned NOT NULL DEFAULT '0', `link_type` bigint(20) unsigned NOT NULL DEFAULT '0', `visibility` tinyint(3) NOT NULL DEFAULT '0', `data` varchar(255) NOT NULL DEFAULT '', `time` bigint(20) unsigned NOT NULL DEFAULT '0', `version` int(11) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (link_type, `id1`,`id2`), KEY `id1_type` (`id1`,`link_type`,`visibility`,`time`,`id2`,`version`,`data`) ) ENGINE=TokuDB DEFAULT CHARSET=latin1; CREATE TABLE `counttable` ( `id` bigint(20) unsigned NOT NULL DEFAULT '0', `link_type` bigint(20) unsigned NOT NULL DEFAULT '0', `count` int(10) unsigned NOT NULL DEFAULT '0', `time` bigint(20) unsigned NOT NULL DEFAULT '0', `version` bigint(20) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`id`,`link_type`) ) ENGINE=TokuDB DEFAULT CHARSET=latin1; CREATE TABLE `nodetable` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `type` int(10) unsigned NOT NULL, `version` bigint(20) unsigned NOT NULL, `time` int(10) unsigned NOT NULL, `data` mediumtext NOT NULL, PRIMARY KEY(`id`) ) ENGINE=TokuDB DEFAULT CHARSET=latin1; |
I am open for suggestions as to what is the proper design of documents for MongoDB – please leave your recommendations in the comments.





Thanks for fixing the coordinated omission problem in LinkBench.
http://psy-lob-saw.blogspot.com/2015/03/fixing-ycsb-coordinated-omission.html
I am interested in results for runs over several hours where the database is much larger than RAM, even better if this uses flash/SSD storage.
You might want to take a look at the reference implementation for social graph called Socialite written in Java using MongoDB: https://github.com/10gen-labs/socialite it has configurable schema options and builtin benchmarking to show which schema option works best in which scenario.
You would likely see very different performance in highly scaled out system than on a single node system for this domain.
I am still hoping that someone publishes MongoDB port of linkbench
Mark,
We are working on MongoDB implementation, it will be available.
And yes, I am going to run long-hours benchmarks, the results will be available.
Thanks. Socialite might be interesting but it would help to get a writeup in one place that explains the data model and basic queries/transactions. Looking at code I see follower counts requires a “count” query which is going to be slow for popular users.
MongoDB for LinkBench can be hard because there aren’t atomic multi-document writes, well, they do exist in TokuMX but nothing else. For linkbench we want to update the count and link tables atomically. With something like an app server we can do locking in the app server to prevent some races and put the app server between clients and mongod, but there isn’t an easy way to make sure that the change to link and count tables is committed together (and recovers together after a crash).
I have read a few clever but very complex solutions for MongoDB to do this via multi-step protocols to compensate for the lack of multi-doc transactions. I’d rather not write that code.
It is indeed a challenge to implement LinkBench logic for MongoDB without multi-document atomicity.
We are looking if we can use this technique to achieve that
http://docs.mongodb.org/v2.2/tutorial/perform-two-phase-commits/
Hi Vadim
While the two phase commit pattern describe in our manual can sometimes be useful, I suspect benchmarking it will be a wasted effort. Nobody would implement performance critical parts of their app with that pattern.
The rule of thumb for designing LinkBench for MongoDB is a reminder: single document operations are atomic. This immediately brings to mind several alternatives for schema design:
1. Maintain a list of my friends as an array in a single document. If it is possible to have thousands of friends, then it will also be a good idea to maintain the count of the items in the array as a separate field in the same document.
In this design consistency of the model is broken at the point that if you and I are friends, then your friend list is not updated atomically together with my friend list. So there could be a short point in time where I’m your friend but you’e not mine, or vice versa. For a real world application this would probably not be an issue (humans don’t have microsecond level perception, nor is the network latency on that level either). But of course for comparing benchmark results agains e.g. MySQL, this is not ideal as the tests would no longer be equivalent. Otoh, you would have to make similar tradeoff desicions if porting LinkBench to most other NoSQL systems as well.
Otoh the count of number of friends a user has is always atomic and correct (from each user point of view). Reading either the count or the list of users will be fast, as it reads just a single document.
2. Maintain a helper collection containing just the pairwise links between users. Much like an M-N relationship is designed in an RDBMS.
In this design the link between 2 users is atomic, as it is a single bi-directional link inserted as one new document. Finding all friends or counting them is now slower, but the result is consistent in all senarios.
3. Directed graph: Keep a list of my friends in an array in a single document, HOWEVER each link is only added once. Say if I added you as a friend, then you are added to my list but I’m not added to yours. To read the list of all my friends (a bi-directional graph) you would have to add together 1) list of my friends, and 2) all users where I appear as friend.
This is quite an unnatural design, but I wanted to list it to point out that it is quite possible to implement with MongoDB. You can for example create an index which makes the second query fast.
In terms of being atomic this approach is equivalent to #2 and I’m afraid performance would be similar as well, in which case we gain nothing from the unintuitive design. (Actually, it’s possible indexing an array of friends would make writes more expensive than the design in #2, I’m not sure.)
4. 2 phase commit. Now that I read it, I’m curious about the possibility to do something like #1, with some added logic in the spirit of 2 phase commit to make it more atomic (or also fault tolerant, which is not a concern for a benchmark but would be for a real world application that engages in de-normalization). I will leave as an exercise to the reader how to actually implement 2-phase logic with minimal overhead in both performance and code complexity.
Of the above, #1 and #2 would be my favorites, in that order.
Assume
1) database must be sharded
2) some nodes have more than a million friends/edges/links
3) workload is probably more complex than you realize — read the LinkBench source to see the read-modify-write done to add a link/friend/edge
We can’t assume cross-shard transactions but we strongly prefer transactions for changes on a single shard. Editorial — “transactions don’t scale” claims for not having multi-doc transactions is only true for cross-shard changes. Transactions work great per-shard at web scale.
Solution 1 doesn’t scale. We can’t put 1M friends into one document.
Solution 2 needs per-shard transactions or the data will be a mess — from partial transactions and inconsistent reads. Even with solution 2 I still prefer a materialized count to reduce load especially for outliers with large numbers of friends.
Solution 3 and 4 – I’d rather not.
Porting this to TokuMX is easy. Porting to pure-Mongo is probably best done with #2 and an implementation that has more data races and data corruption from partial transactions, and likely requires something like an “app server” to enforce locking and compensate for the lack of multi-doc transactions.
> Solution 1 doesn’t scale. We can’t put 1M friends into one document.
Correct. I was assuming on the order of thousands. You could still break this into only a few documents, with tens of thousands of friends each.
>Solution 2 needs per-shard transactions or the data will be a mess — from partial transactions and inconsistent reads.
Where is there a partial transaction? The insert is just db.links.insert( { link : [ “user1”, “user2”] } ), so it is always atomic.
Yes, you could argue that to get a consistent read of the list of friends across all shards, you would need a cluster-wide transaction. But I’d argue that this is not the kind of application where that is really necessary. Ie whatever is returned by find( { link : “user1” } ) is a correct result set. I don’t see sharding making things word than our single node isolation level semantics are anyway.
> Even with solution 2 I still prefer a materialized count to reduce load especially for outliers with large numbers of friends.
If the materialized count doesn’t need to be atomically updated, that is of course possible in a number of ways. Otoh if you’re trying to maintain an atomic view of a dataset that doesn’t fit into a 16 MB BSON document, then I think I’m out of ideas. You’d have to implement 2 phase commit or MVCC I guess.
> 3) workload is probably more complex than you realize — read the LinkBench source to see the read-modify-write done to add a link/friend/edge
Yes, quite clearly. I just wanted to offer some off-the-top-of-my head suggestions to Vadim, before he goes and implements 2 phase commit.
Users strongly prefer correct counts, especially power users who work hard to increase their counts. User experience for liking something is also better when you see the count change. Business logic in real applications isn’t trivial and benefits form single-shard transactions. See addLinkImpl to understand the complexity of adding a friend. Then read addLinksNoCount. Code is:
https://github.com/facebook/linkbench/blob/master/src/main/java/com/facebook/LinkBench/LinkStoreMysql.java#L307
This is made more complex by materializing the count. But if you don’t materialize the count then database might fall over from computing counts for things with many friends.
This is also more complex because the friendship might already be there, just marked as not visible. So instead of adding it the transaction just changes the visibility.
It was possible at some point to run this transaction using “no stored” procedures, or sending all SQL in one batch. See:
http://highscalability.com/blog/2010/11/9/facebook-uses-non-stored-procedures-to-update-social-graphs.html
Ok, if the SQL implementation depends on SELECT FOR UPDATE then I guess the 2 phase commit pattern is a reasonably close equivalent and wouldn’t necessarily even have much worse performance. 2 phase commit also isn’t restricted to single shard, so there are actually some benefits to it in terms of added flexibility, since you’re not going to used stored procedures anyway.
Seriously doubt it. Not sure whether you are joking. 2-phase commit done in userland means 2 transactions, 1 for the PREPARE phase and 1 for the COMMIT phase. Hot spots will be much hotter, code will be a lot more complex. Please, share code for this.
I’m not trying to say it’s great, just that complexity is equivalent. The prepare-commit roundtrips only happen at commit time. The more complex the actual transaction is, the less relative overhead from the commit phase itself.
Not buying it. Show the code. It will be slow. It will be much more complex. Not a fan of the “you don’t need single-shard transactions, but if you do here do 2-phase commit from userland”.
I think Google did this via http://research.google.com/pubs/pub36726.html and that was a reasonable compromise so they could make use of BigTable and they were batch and response time variance wasn’t’ a big deal. I can’t imagine anyone trying to do this for latency sensitive OLTP or where they have to redo it for every workload.
Are there happy Mongo customers doing userland 2-phase commit?
> Are there happy Mongo customers doing userland 2-phase commit?
Yes, but probably not in the way you’re asking this question or that we are discussing now wrt LinkBench. I think we are probably in agreement here on the high level, even if we seem to be going back and forth wrt discussions of specific designs.
In my opinion nobody in their right mind would start building a pre-dominantly transactional system and then select a non-transactional NoSQL database to build it upon. Nor would a MongoDB employee recommend such an application for MongoDB. The situation where these patterns makes sense is where most of the application is a great fit for MongoDB, and then there is some isolated part which is transactional, and you can solve that easily with one or another of “transaction surrogates” patterns. 2-phase commit has the benefit of being the most general purpose ones, but I personally prefer some more elegant alternatives if possible. A simple example might be building an eCommerce site: some parts of such a site, like the CMS functionality and especially the product catalog are a great fit for a document database, and rather inconvenient to build on RDBMS. Otoh then the purchase and order management part might be transactional in nature, but simple enough that you could choose to still build those parts in MongoDB rather than splitting the site into 2 separate databases.
Performance usually doesn’t even enter into the discussion, so honestly I don’t have any real world experience for the above comments, was just speculating. I don’t believe there are apps where the majority of the workload would be using application level 2-phase commit pattern. Why would you bother writing that code, when some other databases provide transactions for free?
That’s kind of where I was trying to go in my first comments too. Briefly reading about LinkBench it seems the core workload is very transactional and assumes strict consistency. I don’t think such a benchmark would be representative of real world MongoDB workloads. It’s much more realistic to assume that if someone actually had implemented a social network on top of MongoDB (and that has been done, obviously) some of the consistency requirements would have been relaxed in ways that result in a (for MongoDB) more natural and also more efficient schema design.
Unfortunately, if you were to adapt LinkBench in such ways, it would be a more relevant benchmark as a MongoDB workload, but at the same time of course results of such a benchmark would not be comparable with original, more strict, LinkBench.
We probably could have implemented single-shard transactions in MongoDB by now with all of this time & energy devoted to this thread.
First MongoDB data model problem, _id is the PK column. Two tables (link, count) have composite PK which isn’t supported by MongoDB. The workarounds are:
* have unique index on them and artificial PK. The cost for this is an extra index and extra column in the table, wastes space and IO
* concatenate the columns and put that value in the _id column. The cost of this is code to concatenate on update/insert and de-concatenate them on query. This also makes it harder to have a query that includes a predicate on one of the fields in the concatenated PK.
https://gist.github.com/mdcallag/5aa546a81f8170ad7bdb