
 The other day a customer asked me to do capacity planning for their web server farm. I was looking at the CPU graph for one of the web servers that had Hyper-threading switched ON and thought to myself: “This must be quite a misleading graph – it shows 30% CPU usage. It can’t really be that this server can handle 3 times more work?”
The other day a customer asked me to do capacity planning for their web server farm. I was looking at the CPU graph for one of the web servers that had Hyper-threading switched ON and thought to myself: “This must be quite a misleading graph – it shows 30% CPU usage. It can’t really be that this server can handle 3 times more work?”
Or can it?
I decided to do what we usually do in such case – I decided to test it and find out the truth. Turns out – there’s more to it than meets the eye.
Before we get to my benchmark results, let’s talk a little bit about hyper-threading. According to Intel, Intel® Hyper-Threading Technology (Intel® HT Technology) uses processor resources more efficiently, enabling multiple threads to run on each core. As a performance feature, Intel HT Technology also increases processor throughput, improving overall performance on threaded software.
Sounds almost like magic, but in reality (and correct me if I’m wrong), what HT does essentially is – by presenting one CPU core as two CPUs (threads rather), it allows you to offload task scheduling from kernel to CPU.
So for example, if you just had one physical CPU core and two tasks with the same priority running in parallel, the kernel would have to constantly switch the context so that both tasks get a fair amount of CPU time. If, however, you have the CPU presented to you as two CPUs, the kernel can give each task a CPU and take a vacation.
On the hardware level, it will still be one CPU doing the same amount of work, but there may be some optimization to how that work is going to be executed.
Here’s the problem that was driving me nuts: if HT does NOT actually give you twice more power and yet the system represents statistics for each CPU thread separately, then at 50% CPU utilization (as per mpstat on Linux), the CPU should be maxed out.
So if I tried to model the scalability of that webserver – a 12-core system with HT enabled (represented as 24 CPUs on a system), assuming perfect linear scalability, here’s how it should look:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Throughput (requests per second) | 9 | ,+++++++++++++++ | + | + 6 | + | + | + 3 | + | + | + 0 '-----+----+----+----+---- 1 6 12 18 24 |
In the example above, a single CPU thread could process the request in 1.2s, which is why you see it max out at 9-10 requests/sec (12/1.2).
From the user perspective, this limitation would hit VERY unexpectedly, as one would expect 50% utilization to be… well, exactly that – 50% utilization.
In fact, the CPU utilization graph would look even more frustrating. For example, if I were increasing the number of parallel requests linearly from 1 to 24, here’s how that relationship should look:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CPU utilization: 100% | ++++++++++++++ | . | . | . | . 50% | . | + | + | + | + 0% '----+----+----+----+---- 0 6 12 18 24 |
Hence CPU utilization would skyrocket right at 12 cores from 50% to 100% because in fact, the system CPU would be 100% utilized at this point.
Naturally, I decided to run a benchmark and see if my assumptions are correct. The benchmark was pretty basic – I wrote a CPU-intensive php script, that took 1.2s to execute on the CPU I was testing this and bashed it over http (apache) with ab at increasing concurrency. Here’s the result:
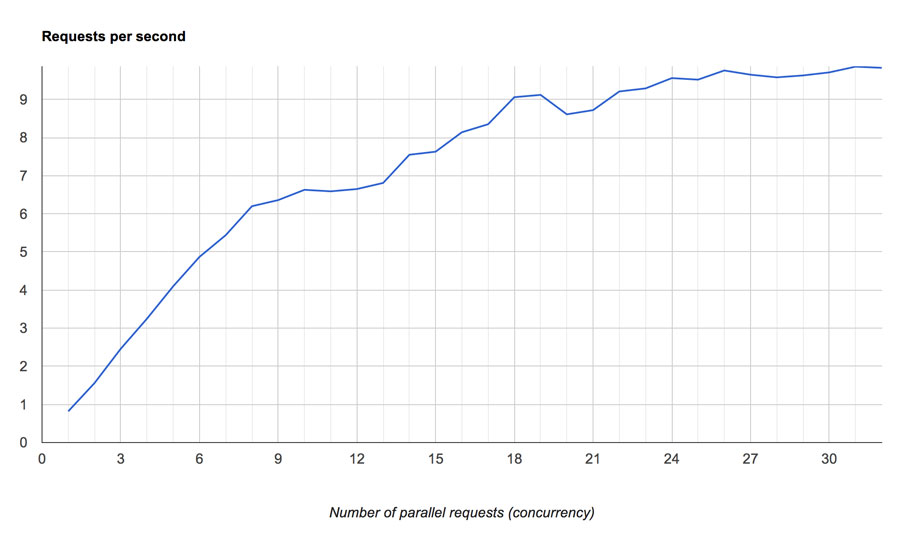 Raw data can be found here.
Raw data can be found here.
If this does not blow your mind, please go over the facts again and then back at the graph.
Still not sure why do I find this interesting? Let me explain. If you look carefully, initially – at a concurrency of 1 through 8 – it scales perfectly. So if you only had data for threads 1-8 (and you knew processes don’t incur coherency delays due to shared data structures), you’d probably predict that it will scale linearly until it reaches ~10 requests/sec at 12 cores, at which point adding more parallel requests would not have any benefits as the CPU would be saturated.
What happens in reality, though, is that past 8 parallel threads (hence, past 33% virtual CPU utilization), execution time starts to increase and maximum performance is only achieved at 24-32 concurrent requests. It looks like at the 33% mark there’s some kind of “throttling” happening.
In other words, to avoid a sharp performance hit past 50% CPU utilization, at 33% virtual thread utilization (i.e. 66% actual CPU utilization), the system gives the illusion of a performance limit – execution slows down so that the system only reaches the saturation point at 24 threads (visually, at 100% CPU utilization).
Naturally then the question is – does it still make sense to run hyper-threading on a multi-core system? I see at least two drawbacks:
1. You don’t see the real picture of how utilized your system really is – if the CPU graph shows 30% utilization, your system may well be 60% utilized already.
2. Past 60% physical utilization, the execution speed of your requests will be throttled intentionally in order to provide higher system throughput.
So if you are optimizing for higher throughput – that may be fine. But if you are optimizing for response time, then you may consider running with HT turned off.
Did I miss something?





It may also be interesting to test it out with and without the SMT aware scheduler (SCHED_SMT kernel option). Also of note is that the new Power8 CPUs offer even more Threads per CPU.
I always understood that HT, more than offloading the kernel of scheduling, lies to the Kernel, presenting more CPUs than it really has. The effect that is that it tricks the kernel into scheduling more than one process at the same time. The HT is able to use of different zones of the CPU in parallel (since CPUs have different zones that are not necessarily needed entirely for executing one instruction). That increments the chance that one thread wants to utilize a part of the CPU that the other thread isn’t needing, being able to parallelize some operations, but if by chance, the two CPUs need the same part of the CPU, one has to wait.
I think that this would explain why until more or less 50% capacity (100% of “one cpu”) you have linear scaling, and after that, you have non-linearity because of the “chance” of the load being able to execute in parallel or not. Could you retry the test without hyperthreading? I think the result would render that at 4 to 6 requests per second you would max out, instead of 9.
you missed that the cpu is overclocking itself depending on the number of cores active (and other stuff). And you do not understand how a cpu disassembles an instruction and disparches it to uta execution units. Thats where hyperthreading kicks in and is able zo utilize the available ressouces better. Depending on the workload, hyperthreading achieves about 10-15% performance increase, where the cpu would have waited.
Pplu, Uli – I really appreciate your feedback guys. This is exactly the kind of feedback I’m looking for with this post that will then help me understand the problem better and maybe even redo some of the benchmarks incorporating your input.
By the way, this is not meant to be a rant against HT as I haven’t been benchmarking performance with and without it. (although I am glad it sparkled some hot reactions). My point is, when looking at the graphs plotting CPU utilisation, one should always have in mind whether the CPU has HT enabled or not.
Thanks,
Aurimas
I think you might be missing a big chunk of the picture if you are not measuring response time (any of average, media, 90 percentile, all of the above).
The hint is: what you are seeing is that the average number of served request per seconds increases just-a-bit, while the incoming requests-per-second are increasing linearly.
And the answer is… going above 8 concurrent requests, your response times are most likely increasing exponentially.
Which would make for very unhappy customers, and poor websites.
Gggeek – that’s actually exactly what my biggest concern was. Unfortunately I don’t have this data now as I have done the benchmark itself quite a while ago, but now I feel obliged to do some benchmarking with and without HT just to see how different is the behaviour in these cases, considering the feedback from other fellows. So I will make sure to include the response time graphs as well.
Aurimas,
CPU architectures these days are very complicated so I think it is very hard to do assumptions along the way of – I’m showing 40% CPU usage how much more capacity do I have. As guys mention response time distribution which starts to suffer on high utilization is one thing but there is also another – if you measure CPU time which execution of your PHP script took it is likely to change with concurrency for many reasons some of them in addition to Hypperthreading are
– Turboboost. When you have only 1 or 2 cores operating it is quite likely to run higher than nominal clock speed which means performance gain from all cores loaded is less even in best case scenario
– Cache. Cache misses can grow with doing a lot of parallel execution which can drastically impact things
– Synchronization – This is very broad but depending on the code there can be a lot of synchronization needs between Cores even if you are not using explicit mutexes in the code which limit scalability.
– Memory Bus, PCI-E etc. This can be the bottleneck causing stalls and limiting scanability.
Now if you’re using advanced profiling tools you should be able to see those various events and understand why CPUs are stalling and it is great for doing work on low level code optimization.
From the ops side though I think it just best to assume we do not know very well how system will scale and be very cautious with guesses. If we’re to place exact bets it is much better to do some benchmarks to tell OK this system can handle 2.5x more load than it is currently handles while still keeping good response time.
Thats true. But regarding HT: it is usually not bad for web-based load (lamp stack) or virtualisation.
The key for additional performance is the os process scheduler. It must not use the virtual cores, until there are too many running processes. and as peter mentioned, at high load the cache management is important. Take a look at the network stack and how they realised that at 10gbit network traffic, even interrupts (that are bound to cores) do matter!
The deal with HyperThreading and SMT is that it make sure there are enough independet instructions in ready to be executed out-of-order.
Modern CPUs are able to execute lot of thing in parallel – not only by simultameous threads but they are also able to execute multiple instruction from single thread in parallel (so called instruction level paralellism or ILP). It’s made possible by out-of-order (OOO) execution mode when CPU is fetching, and decoding multiple instruction every cycle. Those instructions are then put to reorder buffer, which is basically queue of operations waiting to be exucuted. Out-of-order engine then schedule those instructions to be run on particular ports (latest intels have 8 of those) and tries to pick as many instructions to be run at the same time. If instructions are independent, they can be execute in parallel which is good when those instructions are loads that can stall CPU for up to few hundreds of cycles till data arives from memory. If one instruction depend on result of another, it has to wait in queue. Modern CPUs go to extreme lengths to make sure there are at all times some instructions ready in queue, they are prefetching data, predicting branches, speculating.
But there are limits how much ILP is there in single threaded code. Modern x86 are able to fetch, decode and execute up to 4 instructions every single cycle. But in most cases there are not so much ILP available in general code. So HyperThreading come to play. It adds one extra frontend to your CPU (bit that fetches and decodes instructions) that supply extra instruction stream into out-of-order machinery that is hopefully able to find and dispatch more independent instruction to run on available harware.
Main problem with HT is that two threads are competing for same amount of cache. And if you have code that run at 4IPC (like typical math heavy code) HT do nothing.
Suprisingly your results could be caused by cache effects. As you run more threads in parallel, every one of them have smaller portion of cache and that might cause slowdowns. Run code through perf and you will see.
As others have done I’d encourage you to look at the cache stats. Back when HT first came out people started doing significant benchmarking and real-world experimenting with it and found decidedly mixed results. In some cases it resulted in a nice performance boost, in others it could be crippling, actually proving to be slower than not having it on at all.
One of the ‘problems’ with HT is that the virtual core (for want of a better word) shares the exact same cache as the primary core. If those cores are working on completely different tasks that can result in the cache being stomped all over and repeatedly purged which can be highly inefficient.
turbostat from the cpupowerutils package can be run as root to report processor frequency, idle power-state statistics. Running:
seq 1 24 | xargs -t -I {} turbostat ./sysbench –test=cpu –num-threads={} run | grep ‘total time:’
will show the turbostat reports for the sysbench CPU test for 1..24 threads, below I have the reports for 1,6,12 and 24 threads.
Notice how the GHz (average clock rate while the CPU was in c0 state) for the busy CPUs changes, and the %time shifts from c6% ( idle state ) to %c0
If this blog is aimed at MySQL, then let’s throw some more variables in…
* (as already pointed out) The Cache shared by the HT heads may be a slowdown. Hence, turning off HT _may_ lead to individual threads running faster. Conclusion: If you don’t need more than 12 simultaneously running queries, turn off HT.
* MySQL does not use more than one thread per connection, so the “12” vs “24” maps to “can MySQL handle 24 simultaneous connections actively doing CPU work”. In older versions, the answer was “no”, it would max out at 4-8 threads. This was because of Mutexes that were designed back in the single-core days. Percona did a lot to uncork the mess, and Oracle has picked up the ball. Version 5.7 can demonstrably run 64 threads with little conflict. Conclusion: Check your version to see if 24 will be too many for MySQL to handle.
* More importantly, does your application need more than a few connections? I have consulted on thousands of performance problems; most of them boil down to a single SELECT that is poorly written and/or an INDEX that is missing. HT might let the app run lots of these sloppy queries at once, but the “real” solution is to fix the SELECT and/or schema. Conclusion: See if your app really needs, and can use, more than 12.
As Karel Čížek pointed out, CPUs are a lot more complicated than simply being a single entity. In reality there are dozens of parallel processing units handling the execution of code. HT in the beginning was fairly primitive. Depending on the app, the benchmarking I was involved with saw anywhere between 30% and 70% more CPU processing power (100% would be “perfect” HT efficiency). My rule of thumb back then was 50% speed boost for general use web app servers. But that was 2006 era CPUs.
The current generation (core i3/i5/i7, pretty much anything Nehelem and later) are much better. I’ve seen HT efficiency up to 90%, with typical performance around 70-80%.
One of original issues surrounding HT performance was the limitations and splitting of L2 caches. With CPUs like the old Nocona, which had a single core with a 1MB L2 cache. Turning on HT meant splitting that L2 in half. For applications that worked better with that 1MB L2, performance with HT suffered greatly, causing much FUD.
Current generation cores have a 256kb L2 per core, but there is now a huge L3 cache that is shared between cores. This eliminates many of the problems for cache sensitive applciations.
Hi,
What do the columns “time per request” and “total time” mean?
Asking because looking at the numbers they don’t seem to add up.
thanks,
Alex
Aurimas, we would be delighted to see a threaded and non-hyperthreaded tests with mysql benchmarks. This would be the right place so share these results.
Felix
The L2 cache is one particular example of a resource shared among HTs on a physical CPU core.
Others may include the Local Descriptor Table, Register state, Stack pointer, Stack Return Buffer and few others.
If I remember correctly, Intel HT could not run two different contexts on the same physical CPU core at the same time also because of security reasons. This effectively limits hyperthreads to only real O/S threads from the same process context which share the same LDT, stack etc. HT aware O/S scheduler will never schedule two different processes running in different contexts to HTs on the same CPU core.
Applications like Apache HTTP server or Oracle DBMS would never gain any additional performance with HT enabled.
MySQL is a different story though. To measure the CPU/memory throughput of a MySQL server on a HT-enabled system it would be benefical to lock the MySQL process to a particular CPU core/HT set on a particular NUMA node (preventing cross memory channel usage among physical CPU cores). Then eliminate any I/O disk or network bound operations from the test scenario to make the CPU/memory bound operations be 95-99% of a workload.
Otherwise you will not get your statistical model right and can not interpret the results properly.
You may check those my favourite readings here:
https://www.nas.nasa.gov/assets/pdf/papers/saini_s_impact_hyper_threading_2011.pdf
http://www.ibm.com/developerworks/library/l-htl/
IBM developer library has few more documents on the topic I just can not recall at the moment.
Regards,
Roman.
There are several reasons why you should NOT be surprised at these results; and some of your expectations are skewed by a misunderstanding of several concepts.
First, CPU utilization. A system with 50% CPU utilization (for example) simply means that based on sampling over the last interval of time, the OS has identified that only half of all available CPUs (either real or HT) are being used — nothing more, nothing less. In other words, the OS can double the number of threads to saturate the run queues. Weather or not that actually doubles throughput is another matter completely.
This distinction matters because it means CPU utilization does not reveal how many (or which) execution units or pipelines in a CPU are actually being used. Thus, if you see 100% CPU usage in a all-physical system does not mean there is no room for processing left — it just means the OS simply cannot schedule another thread on the system. Thus, it also means when you see 50% CPU on a HT-enabled system, it does not mean all CPU’s are “physically maxed out” — it simply means the OS can still schedule 2x more threads.
Next, your the assumption about how HT works is also flawed — it does NOT “offload task scheduling from kernel to CPU”. HT is Intel’s method to schedule two threads into a superscalar processor (this technology has actually been around for decades prior). It’s underlying assumption is that within a single thread’s superscalar execution; there are still many execution units not being utilized; so if we can schedule a second thread in that does use those units; we can increase efficiency and throughput.
Keeping all of this in mind, the conclusions that “30% utilization, your system may well be 60% utilized” and
“Past 60% physical utilization, execution speed of your requests will be throttled” are simply not true. The benefits of HT vary greatly depending on workloads; but it can provide very real benefits. To simply reduce it to say “HT on for throughput; HT off for response time” is not substantiated.
In your specific case, your diminishing gains are likely due to cache interactions with the increased threads (made possible by HT)
Here is an old article that goes a bit into how hyper threading works.
http://arstechnica.com/features/2002/10/hyperthreading/1/
As several people have said, this is WAY more complicated that your base premise. That all being said, having done significant benchmarking on our own OLTP type SQL workload, Hyper-threading does give us about 15% better performance on a 16 physical core server. It all comes down to keeping the instruction pipeline full, but not at the expense of having to go to a slower memory memory, i.e. L2 to L3 or L3 to main memory for the instruction to process.
Real world instruction streams (usually the product of a compiler from some higher level language) aren’t going to perfect utilize all the available resources of the CPU. You get pesky things like branches, instructions that depend on the result of others.
By having multiple threads in a core, when it can’t issue an instruction from one instruction stream, maybe you can issue one from another thread.
The big challenge is adequately using the resources inside the CPU with all these imperfect instruction streams (otherwise known as The Real World).
Interesting article. I’m just going to test it on our infrastracture. It’s always better to operate on physically available cores.
I always thought it was simply Hardware Thread switching. https://en.wikipedia.org/wiki/File:Table_of_x86_Registers_svg.svg. Saving registers using the software Kernal takes a notable amount of time. By allowing the hardware to do so, NOPs can result in Hardware Thread switching much faster. Although I think this is too simplistic looking at the other comments. Inducing the OS/Kernal to send through more instructions for more pipelining is a summary of what I have read above. I am sure that Hardware Register Saving is still part of the solution however.
Love this discussion! Too bad I’m 4 yrs late 🙂 Regardless I just wanted to add some insight. Hyper-threading simply interleaves two threads on a single core in a very fine grained manner to fill CPU pipeline bubbles, potentially increasing instructions per cycle for a given physical core. The challenge with MySQL and other RDMBs is that the working set of machine code instructions for a single transaction cannot fit into the CPU instruction cache. Instruction chance misses therefor often dominate an OLTP workload’s CPU cycles. Now imagine what effect this fine grained interleaving of two threads will do to the already poor instruction locality? At any given time it’s unlikely each thread is running the same part of their transaction/query, so each thread is simply polluting the other’s instruction cache.