
I believe InnoDB storage engine architecture is great for a lot of online workloads, however, there are no silver bullets in technology and all design choices have their trade offs. In this blog post I’m going to talk about one important InnoDB limitation that you should consider.
InnoDB is a multiversion concurrency control (MVCC) storage engine which means many versions of the single row can exist at the same time. In fact there can be a huge amount of such row versions. Depending on the isolation mode you have chosen, InnoDB might have to keep all row versions going back to the earliest active read view, but at the very least it will have to keep all versions going back to the start of SELECT query which is currently running.
In most cases this is not a big deal – if you have many short transactions happening you will have only a few row versions to deal with. If you just use the system for reporting queries but do not modify data aggressively at the same time you also will not have many row versions. However, if you mix heavy updates with slow reporting queries going at the same time you can get into a lot of trouble.
Consider for example an application with a hot row (something like actively updated counter) which has 1000 updates per second together with some heavy batch job that takes 1000 to run. In such case we will have 1M of row versions to deal with.
Let’s now talk about how those old-row versions are stored in InnoDB – they are stored in the undo space as an essentially linked list where each row version points to the previous row version together with transaction visibility information that helps to decide which version will be visible by this query. Such design favors short new queries that will typically need to see one of the newer rows, so they do not have to go too far in this linked list. This might not be the case with reporting queries that might need to read rather old row version which correspond to the time when the query was started or logical backups that use consistent reads (think mysqldump or mydumper) which often would need to access such very old row versions.
So going through the linked list of versions is expensive, but how expensive it can get? In this case a lot depends upon whenever UNDO space fits in memory, and so the list will be traversed efficiently – or it does not, in which case you might be looking at the massive disk IO. Keep in mind undo space is not clustered by PRIMARY key, as normal data in InnoDB tables, so if you’re updating multiple rows at the same time (typical case) you will be looking at the row-version chain stored in many pages, often as little as one row version per page, requiring either massive IO or a large amount of UNDO space pages to present in the InnoDB Buffer pool.
Where it can get even worse is Index Scan. This is because Indexes are structured in InnoDB to include all row versions corresponding to the key value, current and past. This means for example the index for KEY=5 will contain pointers to all rows that either have value 5 now or had value 5 some time in the past and have not been purged yet. Now where it can really bite is the following – InnoDB needs to know which of the values stored for the key are visible by the current transaction – and that might mean going through all long-version chains for each of the keys.
This is all theory, so lets see how we can simulate such workloads and see how bad things really can get in practice.
I have created 1Bil rows “sysbench” table which takes some 270GB space and I will use a small buffer pool – 6GB. I will run sysbench with 64 threads pareto distribution (hot rows) while running a full table scan query concurrently: select avg(k) from sbtest1 Here is exact sysbench run done after prepare.
|
1 |
sysbench --num-threads=64 --report-interval=10 --max-time=0 --max-requests=0 --rand-type=pareto --oltp-table-size=1000000000 --mysql-user root --mysql-password=password --test /usr/share/doc/sysbench/tests/db/oltp.lua run |
Here is the explain for the “reporting” query that you would think to be a rather efficient index scan query. With just 4 bytes 1 Billion of values would be just 4G (really more because of InnoDB overhead) – not a big deal for modern systems:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> explain select avg(k) from sbtest1 G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: sbtest1 type: index possible_keys: NULL key: k_1 key_len: 4 ref: NULL rows: 953860873 Extra: Using index 1 row in set (0.00 sec) |
…
2 days have passed and the “reporting” query is still running… furthermore the foreground workload started to look absolutely bizarre:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
[207850s] threads: 64, tps: 0.20, reads: 7.40, writes: 0.80, response time: 222481.28ms (95%), errors: 0.70, reconnects: 0.00 [207860s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [207870s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [207880s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [207890s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [207900s] threads: 64, tps: 2.70, reads: 47.60, writes: 11.60, response time: 268815.49ms (95%), errors: 0.00, reconnects: 0.00 [207910s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [207920s] threads: 64, tps: 2.30, reads: 31.60, writes: 9.50, response time: 294954.28ms (95%), errors: 0.00, reconnects: 0.00 [207930s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [207940s] threads: 64, tps: 2.90, reads: 42.00, writes: 12.20, response time: 309332.04ms (95%), errors: 0.00, reconnects: 0.00 [207950s] threads: 64, tps: 0.20, reads: 4.60, writes: 1.00, response time: 318922.41ms (95%), errors: 0.40, reconnects: 0.00 [207960s] threads: 64, tps: 0.20, reads: 1.90, writes: 0.50, response time: 335170.09ms (95%), errors: 0.00, reconnects: 0.00 [207970s] threads: 64, tps: 0.60, reads: 13.20, writes: 2.60, response time: 292842.88ms (95%), errors: 0.60, reconnects: 0.00 [207980s] threads: 64, tps: 2.60, reads: 37.60, writes: 10.20, response time: 351613.43ms (95%), errors: 0.00, reconnects: 0.00 [207990s] threads: 64, tps: 5.60, reads: 78.70, writes: 22.10, response time: 186407.21ms (95%), errors: 0.00, reconnects: 0.00 [208000s] threads: 64, tps: 8.10, reads: 120.20, writes: 32.60, response time: 99179.05ms (95%), errors: 0.00, reconnects: 0.00 [208010s] threads: 64, tps: 19.50, reads: 280.50, writes: 78.90, response time: 27559.69ms (95%), errors: 0.00, reconnects: 0.00 [208020s] threads: 64, tps: 50.70, reads: 691.28, writes: 200.70, response time: 5214.43ms (95%), errors: 0.00, reconnects: 0.00 [208030s] threads: 64, tps: 77.40, reads: 1099.72, writes: 311.31, response time: 2600.66ms (95%), errors: 0.00, reconnects: 0.00 [208040s] threads: 64, tps: 328.20, reads: 4595.40, writes: 1313.40, response time: 911.36ms (95%), errors: 0.00, reconnects: 0.00 [208050s] threads: 64, tps: 538.20, reads: 7531.90, writes: 2152.10, response time: 484.46ms (95%), errors: 0.00, reconnects: 0.00 [208060s] threads: 64, tps: 350.70, reads: 4913.45, writes: 1404.09, response time: 619.42ms (95%), errors: 0.00, reconnects: 0.00 [208070s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208080s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208090s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208100s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208110s] threads: 64, tps: 1.60, reads: 24.20, writes: 6.80, response time: 42385.40ms (95%), errors: 0.10, reconnects: 0.00 [208120s] threads: 64, tps: 0.80, reads: 28.20, writes: 3.40, response time: 51381.54ms (95%), errors: 2.80, reconnects: 0.00 [208130s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208140s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208150s] threads: 64, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00 [208160s] threads: 64, tps: 0.60, reads: 14.20, writes: 2.40, response time: 93248.04ms (95%), errors: 0.80, reconnects: 0.00 |
As you can see we have long stretches of times when there are no queries completed at all… going to some spikes of higher performance. This is how it looks on the graph:
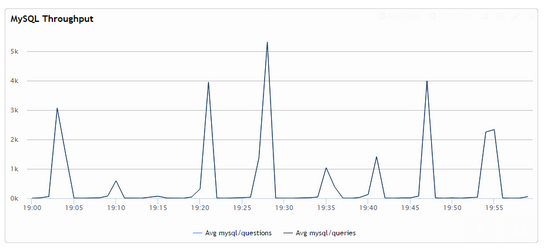
Corresponding CPU usage:
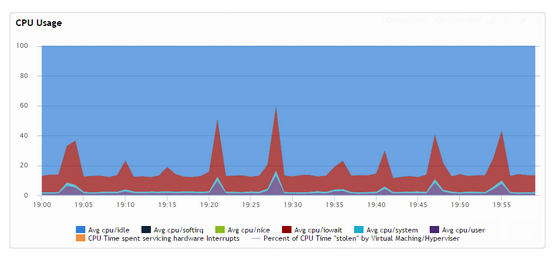
This shows what we are not only observing something we would expect with InnoDB design but also there seems to be some serve starvation happening in this case which we can confirm:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.0/storage/innobase/row/row0ins.cc line 2357 --Thread 139790809552640 has waited at btr0cur.cc line 3852 for 194.00 seconds the semaphore: S-lock on RW-latch at 0x7f24d9c01bc0 '&block->lock' a writer (thread id 139790814770944) has reserved it in mode wait exclusive number of readers 1, waiters flag 1, lock_word: ffffffffffffffff Last time read locked in file row0sel.cc line 4125 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.0/storage/innobase/row/row0ins.cc line 2357 --Thread 139790804735744 has waited at row0sel.cc line 3506 for 194.00 seconds the semaphore: S-lock on RW-latch at 0x7f24d9c01bc0 '&block->lock' a writer (thread id 139790814770944) has reserved it in mode wait exclusive number of readers 1, waiters flag 1, lock_word: ffffffffffffffff Last time read locked in file row0sel.cc line 4125 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.0/storage/innobase/row/row0ins.cc line 2357 --Thread 139790810756864 has waited at row0sel.cc line 4125 for 194.00 seconds the semaphore: S-lock on RW-latch at 0x7f24d9c01bc0 '&block->lock' a writer (thread id 139790814770944) has reserved it in mode wait exclusive number of readers 1, waiters flag 1, lock_word: ffffffffffffffff Last time read locked in file row0sel.cc line 4125 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.0/storage/innobase/row/row0ins.cc line 2357 --Thread 139790811158272 has waited at btr0cur.cc line 3852 for 194.00 seconds the semaphore: S-lock on RW-latch at 0x7f24d9c01bc0 '&block->lock' a writer (thread id 139790814770944) has reserved it in mode wait exclusive |
Waiting for the given buffer pool block to become available for more than 3 minutes is a big issue – this lock should never be held by more than a few microseconds.
SHOW PROCESSLIST confirms even most basic selects by primary key can get stalled for long time
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
| 5499 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5500 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5501 | root | localhost | sbtest | Query | 185 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5502 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5503 | root | localhost | sbtest | Query | 14 | statistics | SELECT DISTINCT c FROM sbtest1 WHERE id BETWEEN 1 AND 1+99 ORDER BY c | 0 | 0 | | 5504 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5505 | root | localhost | sbtest | Query | 14 | updating | UPDATE sbtest1 SET k=k+1 WHERE id=1 | 0 | 0 | | 5506 | root | localhost | sbtest | Query | 236 | updating | DELETE FROM sbtest1 WHERE id=1 | 0 | 0 | | 5507 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5508 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id BETWEEN 1 AND 1+99 | 0 | 0 | | 5509 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=1 | 0 | 0 | | 5510 | root | localhost | sbtest | Query | 14 | updating | UPDATE sbtest1 SET c='80873149502-45132831358-41942500598-17481512835-07042367094-39557981480-593123 | 0 | 0 | | 5511 | root | localhost | sbtest | Query | 236 | updating | UPDATE sbtest1 SET k=k+1 WHERE id=18 | 0 | 1 | | 5512 | root | localhost | sbtest | Query | 14 | statistics | SELECT c FROM sbtest1 WHERE id=7 | 0 | 0 | | 6009 | root | localhost | sbtest | Query | 195527 | Sending data | select avg(k) from sbtest1 | 0 | 0 | |
How do I know it is UNDO space related issue in this case? Because it ends up taking majority of buffer pool
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> select page_type,count(*) from INNODB_BUFFER_PAGE group by page_type; +-------------------+----------+ | page_type | count(*) | +-------------------+----------+ | EXTENT_DESCRIPTOR | 1 | | FILE_SPACE_HEADER | 1 | | IBUF_BITMAP | 559 | | IBUF_INDEX | 855 | | INDEX | 2186 | | INODE | 1 | | SYSTEM | 128 | | UNDO_LOG | 382969 | | UNKNOWN | 6508 | +-------------------+----------+ 9 rows in set (1.04 sec) |
And it does so in a very crazy way – when there is almost no work being done UNDO_LOG contents of the buffer pool is growing very rapidly while when we’re getting some work done the INDEX type pages take a lot more space. To me this seems like as the index scan is going it touches some hot rows and some not-so-hot ones, containing less row versions and so does not put much pressure on “undo space.”
Take Away: Now you might argue that this given workload and situation is rather artificial and rather narrow. It well might be. My main point here is what if you’re looking at just part of your workload, such as your main short application queries, and not taking reporting or backups into account “because their performance is not important.” In this case you might be in for a big surprise. Those background activities might be taking much more than you would expect, and in addition, they might have much more of a severe impact to your main application workload, like in this case above.
P.S: I’ve done more experiments to validate how bad the problem really is and I can repeat it rather easily even without putting system into overdrive. Even if I run sysbench injecting just 25% of the transactions the system is possibly capable of handling at peak I have “select avg(k) from sbtest1” query on 1 billion row table to never complete as it looks like the new entries are injected into the index at this point faster than Innodb can examine which of them are visible.
Resources
RELATED POSTS





It is not at all artificial workload. I was seeing exactly this back in my days at Nokia for one app. Large database, heavy on updates and of course reads, and a few background processes wanted to do count(*) on some large tables. These count(*) queries took 7-10 hours to run.
Chaning isolation level helped us get over most of the pain, and I think ultimately we also started avoiding the count(*) queries altogether. (The app has since been completely rewritten to a more denomarlized schema…)
I hadn’t considered the effect of undo records on the situation. We were at a similar level though, with hundreds of updates per second.
Thanks for a thorough explanation once again!
We were experiencing this problem in lower scale in a very active forums, while trying to calculate stats in the background.
Peter, similar experience. We came over that issue but the internal reason for the issue is not clear till now. Thank you, appreciate for your time explaining. Frankly speaking familiarity with this kind of situation is very rare
That’s in particular why XtraBackup is better than mysqldump –single-transaction
Henrik,
As I have been doing more tests here indeed there are number of rather common scenarios where I can see this behavior triggered to various extents. Counter tables or tables with flags, ie when you set flag=1 when it is processed and cleared to 0 can easily create those problems.
Vladimir – yes good point of this really being the possible issue with backups. Indeed database which is heavily changed might be quite impacted by mysqldump backup.
We ran into a similar issue with heavy updates on a given table and since the table was a session table we decided to r the data to convert it into a ‘memory’ table.
I understand each case would be different, however what would be the best approach? Avoiding mix heavy updates with slow reporting queries if possible or changing the isolation level?
a ‘memory’ table.
Sorry a lot of typos.
The correct version …
We ran into a similar issue with heavy updates on a given table and since the table was a session table we decided to convert it into a ‘memory’ table.
I understand each case would be different, however what would be the best approach? Avoiding mix heavy updates with slow reporting queries if possible or changing the isolation level?
great post Peter. very interesting. yet another reason to leverage percona’s ability to show buffer breakdown.
Have you been talking to Domas? http://bugs.mysql.com/bug.php?id=74919
This idea seems to be in the air this holiday season. 🙂
What about changing the transaction isolation from REPEATABLE READ to READ COMMITTED?
If I remember correctly, in my case we changed everything to READ UNCOMMITTED and that helped a lot.
If I understand the problem correctly – especially now with Peter’s excellent explanation – then setting only the long running query to READ UNCOMMITTED would suffice.
Daniel, Henrik,
Unfortunately it does not really work. READ COMMITTED works if you have long transaction containing multiple statements. For example it is very good for Java where you might up having application keeping transaction open for long time. It does not work however when you have single long query, like in case of reporting.
To Henrik’s point – READ UNCOMMITTED could work in theory – by definition purge could proceed purging old records even as query is running giving it dirty reads. It could but it does not. Even if you have query running in READ UNCOMMITTED isolation mode the purge process will be blocked until the query is done.
One thing worth noting is TokuDB handles such workload surprisingly well. I have looked into having heavy updates and keeping multi-versions going for many days with very limited impact to performance of both foreground update workload and the reporting one
Peter: In the project I was working with, switching everything to READ UNCOMITTED did have a significant positive impact. But I will have to be the first one to admit I didn’t fully understand why, I was just happy that the problem was solved. At the time I also suspected the InnoDB gap locking, another area I don’t feel confident I fully understand.
Henrik,
I believe you. I simply state it does not quite help with purging progress. Did you go from REPEATABLE-READ or from READ-COMMITTED ?
I think we tried both REPEATABLE READ and READ COMMITTED, but only READ UNCOMMITTED solved the problem. (Then the workload was of course heavily disk bound anyway.)
Thanks Henrik,
Here is a theory. We really have 2 issues in play here. One is version accumulation other is previous version lookup through undo space which can be very expensive. Read-Uncommitted does not allow purge to progress but read-uncommitted transaction perhaps should see the most current version of the row instead of going deep into undo space to get the one which corresponds to start of transaction or statement. This can cause quite a difference.
Another related issue that comes from a lot of undo information is the amount of undo space that gets used on disk on the server. This information is stored in the ibdata file which will make it grow. Like many others I use innodb_file_per_table so the ibdata1 file in theory should be very small but I have a few servers where this file has grown to 300GB due to the undo information growing so much. Later even if the undo information is no longer used the ibdata1 file can not be shrunk or modified in size. When I clone one server to make a new one this thus requires me to copy this additional useless space onto a new server. mysqldump + load is just too slow for this type of server, so I’m stuck with this wasted disk space.
MySQL 5.7 promises a separate undo table space which allows for these files to be cleared but there is no migration path from the current setup to the new one. It would be nice if work would be done on that as while the database is down (during a clone or or regular maintenance) there is an opportunity if this undo space is mainly “empty” now to rewrite this ibdata1 file or rearrange the table spaces to take advantage of this new feature. Such a migration facility would save me a few hundred GB here and there on different servers and that would be really useful.
well, as mentioned in https://www.facebook.com/MySQLatFacebook/posts/10152610642241696 – this is a problem that should be looked at, I filed a bug at http://bugs.mysql.com/bug.php?id=74919 – let us all put pressure on it
Excellent post. Without more details, this statement from your text above can be scary:
“This is because Indexes are structured in InnoDB to include all row versions corresponding to the key value, current and past.”
Fortunately an old post from InnoDB has more details – https://blogs.oracle.com/mysqlinnodb/entry/mysql_5_5_innodb_change
Mark,
Yes. This is a good detail. I wish there would be some good detailed documentation about how MVCC plays with indexes. What happens when I do K=K+1 for given primary key value, which requires this row to be found by both key values depending on transaction visibility.
I think this is the most relevant paragraph from the old blog post you mention:
“When a secondary index record has been marked for deletion or when the page has been updated by a newer transaction, InnoDB will look up the clustered index record. In the clustered index, it suffices to check the DB_TRX_ID and only retrieve the correct version from the undo log when the record was modified after the reading transaction started.”
which explains how Covering index scan only works for pages which are not being actively modified
This is an old post but for some reason I was thinking about this last week.
I now remember what we did in the project I mentioned in this thread. My answer above is wrong.
Changing from REPEATABLE READ to READ COMMITTED did help with the performance drag created by the long running queries.
However, when running in READ COMMITTED mode we then did a pt-query-digest and there was one frequent query that was using up more than 50% of the execution time. (I don’t remember if this was a SELECT or UPDATE.) This seemed abnormal so we changed to READ UNCOMMITTED and got a more balanced situation in pt-query-digest and overall some additional boost in performance. (…which is of course not surprising.)
Still, I think for the problem discussed in this blog post, it actually did help to move from REPEATABLE READ to READ UNCOMMITTED.