
Each day there is probably work done to improve performance of the InnoDB storage engine and remove bottlenecks and scalability issues. Hence there was another one I wanted to highlight:
This scalability issue is caused by the usage of tables without primary keys. This issue typically shows itself as contention on the InnoDB dict_sys mutex. Now the dict_sys mutex controls access to the data dictionary. This mutex is used at various places. I will only mention a few of them:
Of course this list is not exhaustive but should give you a good picture of how heavily it is used.
But the thing is when you are mainly debugging contention related to a data dictionary control structure, you start to look off at something that is directly related to data dictionary modifications. You look for execution of CREATE TABLE, DROP TABLE, TRUNCATE TABLE, etc. But what if none of that is actually causing the contention on the dict_sys mutex? Are you aware when generating “row-id” values, for tables without explicit primary keys, or without non-nullable unique keys, dict_sys mutex is acquired. So INSERTs to tables with implicit primary keys is a InnoDB system-wide contention point.
Let’s also take a look at the relevant source code.
Firstly, below is the function that does the row-id allocation which is defined in the file storage/innobase/row/row0ins.cc
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
3060 /***********************************************************//** 3061 Allocates a row id for row and inits the node->index field. */ 3062 UNIV_INLINE 3063 void 3064 row_ins_alloc_row_id_step( 3065 /*======================*/ 3066 ins_node_t* node) /*!< in: row insert node */ 3067 { 3068 row_id_t row_id; 3069 3070 ut_ad(node->state == INS_NODE_ALLOC_ROW_ID); 3071 3072 if (dict_index_is_unique(dict_table_get_first_index(node->table))) { 3073 3074 /* No row id is stored if the clustered index is unique */ 3075 3076 return; 3077 } 3078 3079 /* Fill in row id value to row */ 3080 3081 row_id = dict_sys_get_new_row_id(); 3082 3083 dict_sys_write_row_id(node->row_id_buf, row_id); 3084 } |
Secondly, below is the function that actually generates the row-id which is defined in the file storage/innobase/include/dict0boot.ic
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
26 /**********************************************************************//** 27 Returns a new row id. 28 @return the new id */ 29 UNIV_INLINE 30 row_id_t 31 dict_sys_get_new_row_id(void) 32 /*=========================*/ 33 { 34 row_id_t id; 35 36 mutex_enter(&(dict_sys->mutex)); 37 38 id = dict_sys->row_id; 39 40 if (0 == (id % DICT_HDR_ROW_ID_WRITE_MARGIN)) { 41 42 dict_hdr_flush_row_id(); 43 } 44 45 dict_sys->row_id++; 46 47 mutex_exit(&(dict_sys->mutex)); 48 49 return(id); 50 } |
Finally, I would like to share results of a few benchmarks that I conducted in order to show you how this affects performance.
First off all, let me share information about the host that was used in the benchmarks. I will also share the MySQL version and InnoDB configuration used.
The host was a “hi1.4xlarge” Amazon EC2 instance. The instance comes with 16 vCPUs and 60.5GB of memory. The instance storage consists of 2×1024 SSD-backed storage volumes, and the instance is connected to a 10 Gigabit ethernet network. So the IO performance is very decent. I created a RAID 0 array from the 2 instance storage volumes and created XFS filesystem on the resultant software RAID 0 volume. This configuration would allows us to get the best possible IO performance out of the instance.
The MySQL version used was 5.5.34 MySQL Community Server, and the InnoDB configuration looked as follows:
|
1 2 3 4 5 6 7 8 9 |
innodb-flush-method = O_DIRECT innodb-log-files-in-group = 2 innodb-log-file-size = 512M innodb-flush-log-at-trx-commit = 2 innodb-file-per-table = 1 innodb-buffer-pool-size = 42G innodb-buffer-pool-instances = 8 innodb-io-capacity = 10000 innodb_adaptive_hash_index = 1 |
I conducted two different types of benchmarks, and both of them were done by using sysbench.
First one involved benchmarking the performance of single-row INSERTs for tables with and without explicit primary keys. That’s what I would be showing first.
The tables were generated as follows for the benchmark involving tables with primary keys:
|
1 |
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test prepare |
This resulted in the following table being created:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `sbtest1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB |
While the tables without primary keys were generated as follows:
|
1 |
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-secondary --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test prepare |
This resulted in the tables being created with the following structure:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `sbtest1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', KEY `xid` (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB |
The actual benchmark for the table with primary keys was run as follows:
|
1 |
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-dist-type=uniform --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --max-time=300 --num-threads=16 --max-requests=0 --report-interval=1 run |
While the actual benchmark for the table without primary keys was run as follows:
|
1 |
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-secondary --oltp-dist-type=uniform --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --max-time=300 --num-threads=16 --max-requests=0 --report-interval=1 run |
Note that the benchmarks were run with three variations in the number of concurrent threads used by sysbench: 16, 32 and 64.
Below are how the graphs look like for each of these benchmarks.
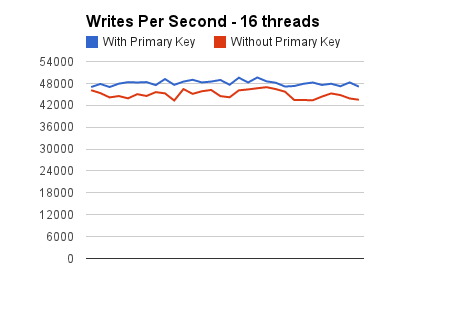
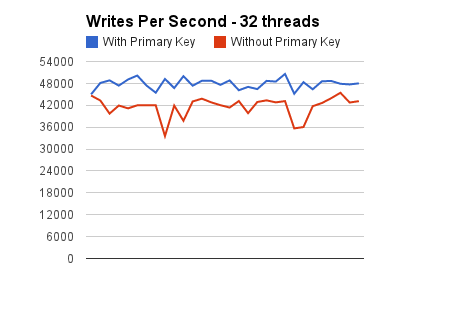
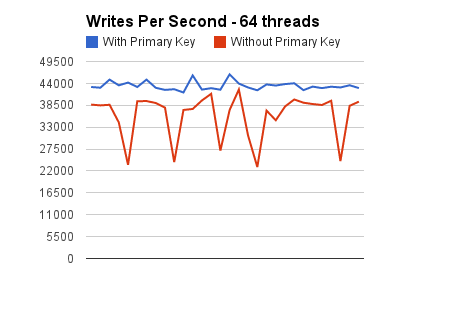
Some key things to note from the graphs are that the throughput of the INSERTs to the tables without explicit primary keys never goes above 87% of the throughput of the INSERTs to the tables with primary keys defined. Furthermore, as we increase the concurrency downward spikes start appearing. These become more apparent when we move to a concurrency of 64 threads. This is expected, because the contention is supposed to increase as we increase the concurrency of operations that contend on the dict_sys mutex.
Now let’s take a look at how this impacts the bulk load performance.
The bulk loads to the tables with primary keys were performed as follows:
|
1 |
sysbench --test=/root/sysbench/sysbench/tests/db/parallel_prepare.lua --oltp-tables-count=64 --oltp-table-size=1000000 --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --num-threads=16 run |
While the bulk loads to the tables without primary keys were performed as follows:
|
1 |
sysbench --test=/root/sysbench/sysbench/tests/db/parallel_prepare.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-secondary --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --num-threads=16 run |
Note that the benchmarks were again run with three variations in the number of concurrent threads used by sysbench: 16, 32 and 64.
Below is what the picture is portrayed by the graph.
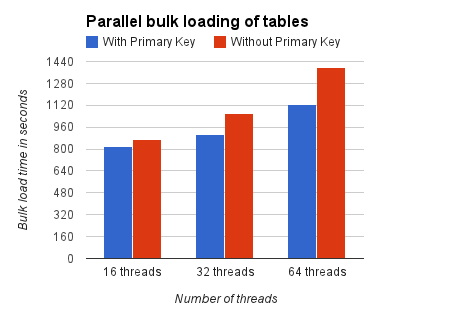
Here again, you can see how the bulk load time increases as we increase the number of concurrent threads. This against points to the increase in contention on the dict_sys mutex. With 16 threads the bulk load time for tables without primary keys is 107% more than the bulk load time for the tables with primary keys. This increases to 116% with 32 threads and finally 124% with 64 threads.
Tables without primary keys cause a wide range of contention because they rely on acquiring dict_sys mutex to generate row-id values. This mutex is used at critical places within InnoDB. Hence the affect of large amount of INSERTs to tables without primary keys is not only isolated to that table alone but can be seen very widely. There are a number of times I have seen tables without primary keys being used in many different scenarios that include simple INSERTs to these tables as well as multi-row INSERTs as a result of, for example, INSERT … SELECT into a table that is being temporarily created. The advice is always to have primary keys present in your tables. Hopefully I have been able to highlight the true impact non-presence of primary keys can have.





Unfortunately, partitioning often means having to go without a primary key because all columns in a unique index must be part of the partitioning key.
Thus, it would be great if Percona or Oracle (or Facebook, or whomever) would make the id generation per-table instead of per-instance.
Also, the bulk input test – was the input sorted? I’d be curious to see how InnoDB with the primary key compares to no primary key when InnoDB has to sort the data (assuming your load was sorted).
Justin, the rule is slightly different from what you stated. All primary/unique constraints must include the partitioning key. But not all columns in the primary/unique constraint must be part of the partitioning key.
If only MySQL could generate warnings if someone forgets a primary keys… http://bugs.mysql.com/bug.php?id=69223 (please click affects me too if it does affect you)
Without PRIMARY KEY the performance for InnoDB not only suffers, but also slave performance suffers. With PXC not having PK’s will result in bad performance or might break things (old versions).
Any suggestions on ways to add a primary key to a large existing table without a lot of down time? I normally use pt-online-schema-change for this sort of thing, but that won’t work on a table without a primary key.
Justin, regarding your question about “bulk inserts”, the bulk inserts when InnoDB has a primary key would insert the data in sorted order. The inserts were done in that case in a table with an AUTO INCREMENT column and the value for that column was not specified when doing the bulk insert.
Daniël,
What you have suggested is a good feature request. However, if you think from the standpoint of what is valid and what is not in terms of RDMS and SQL, then its perfectly fine for tables to not have primary keys. For example as Justin mentioned, you may not have PK in partitioned tables. The bug is actually in how the internal PK is generated, I would not expect InnoDB to need an instance level mutex to generate internal PK. And that is something that should be fixed.
On the other hand, not having PK can hurt InnoDB performance in certain other ways, and also impacts performance of slaves with RBR. Again that is something that needs to be handled on the part of how RBR applies row-events. There are a lot of performance improvements in MySQL/PS 5.6 in terms of RBR when it comes to tables without primary keys. Similarly you should see improvement in PXC 5.6 with respect to tables without primary keys.
Perrin,
pt-online-schema change would not he helpful when the table does not have a PK or a UK that could be used, because then pt-osc would not be able to safely capture and apply row modifications to the new table while it has not yet swapped the old table with the new table.
In such cases you would have to rely on traditional approaches such as adding the key on the slave and then promoting it to be the master. But then you may hit this bug: http://bugs.mysql.com/bug.php?id=69680
Without Primary Key (and without unique key), the hidden InnoDB primary key (6-bytes) will be global to all your InnoDB tables without primary keys… that’s were the contention in case of concurrency happens.
In your benchmarks, were you comparing the 6-byte hidden key to a 4-byte INT or to an 8-byte BIGINT? The difference in size of the data stored on disk _might_ explain the performance difference.
Hi Ovais,
FYI, I covered this a few months ago here:
http://blog.jcole.us/2013/05/02/how-does-innodb-behave-without-a-primary-key/
Thanks for doing these benchmarks, but I too would like to see a comparison of INT vs. BIGINT for the key, and perhaps even CHAR(6) BINARY, to provide better “control” data points.
Hi,
I will do a follow up blog post after testing with BIGINT PK columns.
Good surprised it’s not that bad, note that with the tested DDL, without the PK InnoDB have to maintain 3 indexes and with the PK only 2. Results with the same number of indexes would be more fair on impact of bad schema design .The mutex is not under contention, small dict without much memory copy i guess mutex have been just made for this. As Jeremy pointed out it can cause dict operations to be stalled but no longer than disk sync latency. Any idea on what DML take dict_mutex in concurency and would require fast latency. I guess InnoDB disk temporary tables ?
Hello Ovais,
Could you provide your lua scripts to try to reproduce your tests? I find this interesting as we are using a monitoring application like Zabbix without primary keys in its mysql’s history tables and we would like to test the performance.
Thanks in advance. Best regards!
‘@Harry — all of those lua scripts are part of the sysbench 0.5 package — you can build it yourself from launchpad, or download packages from our percona repos for it now.