
 Percona Server’s “crash-resistant replication” feature is useful in versions 5.1 through 5.5. However, in Percona Server 5.6 it’s replaced with Oracle MySQL 5.6’s “crash safe replication” feature, which has it’s own implementation (you can read more about it here).
Percona Server’s “crash-resistant replication” feature is useful in versions 5.1 through 5.5. However, in Percona Server 5.6 it’s replaced with Oracle MySQL 5.6’s “crash safe replication” feature, which has it’s own implementation (you can read more about it here).
A MySQL slave normally stores its position in files master.info and relay-log.info which are updated by slave IO_THREAD & slave SQL_THREAD respectively. The file master.info contains connection info & replication coordinates showing how many events were fetched from the master binary log. The relay-log.info, on the other hand, represents info showing the positions where the slave applied those events. You can read more about slave status logs here
The relay-log.info file contains the position of the slave relay log, which the slave is applying. Somehow, if a crash occurs on the slave between transaction commit and update of relay-log.info, the replication can be inconsistent – indicating that the relay-log.info file may not be in sync on the disk and contains old information. As a result, when the slave starts again it will read old events from the relay log. And because of this the transaction can be applied multiple times.
If your table has a primary key or a unique key defined, it then stops replication with error 1062 “DUPLICATE KEY ERROR,” which requires manual intervention to skip a problematic event via SQL_SLAVE_SKIP_COUNTER and resume replication. If there is no primary key or unique key defined then it’s even worse because INSERT may be re-executed and you will get multiple rows with the same data – which again means you’ve got inconsistent data with the master. If you are lucky (i.e. if relay-log.info is already is in sync during crash) then there should be no problem with replication – but that’s not the case most of the time. For UPDATE/DELETE it may cause different errors or no errors on same row.
How to solve this problem?
Fortunately, Percona Server has a feature to deal with these type of situations. As I mentioned above, the “crash-resistant replication” feature first appeared in version 5.1 — i.e. innodb_recovery_update_relay_log needs to be enabled on the slave side. When innodb_recovery_update_relay_log is enabled, it only updates InnoDB/XtraDB tables and will not bother with MyISAM tables or other storage engines. Enabling innodb_recovery_update_relay_log requires a server restart. For more about the crash-resistant replication feature you can refer to documentation here.
Let’s illustrate this through two examples, one without and another using this feature to see the difference it makes.
Without Percona Crash-Resistant Replication:
I am using the mysqlslap utility and will insert data on the master and will kill the slave mysqld process during the middle of insertion. Let’s take a look at the impact on the slave. Replication is already configured between nodes. Let’s start inserting data on the master via the mysqlslap utility. I am going to use,

This setting of 100000 total queries with 100 concurrent clients will run 100000/100 = 1000 queries per client 10 times in this test. It’s running and replicating to the slave eventually, but let me kill the slave mysqld process and start mysql again to see the impact. Started mysqld again on slave node.
Now let see the slave status….
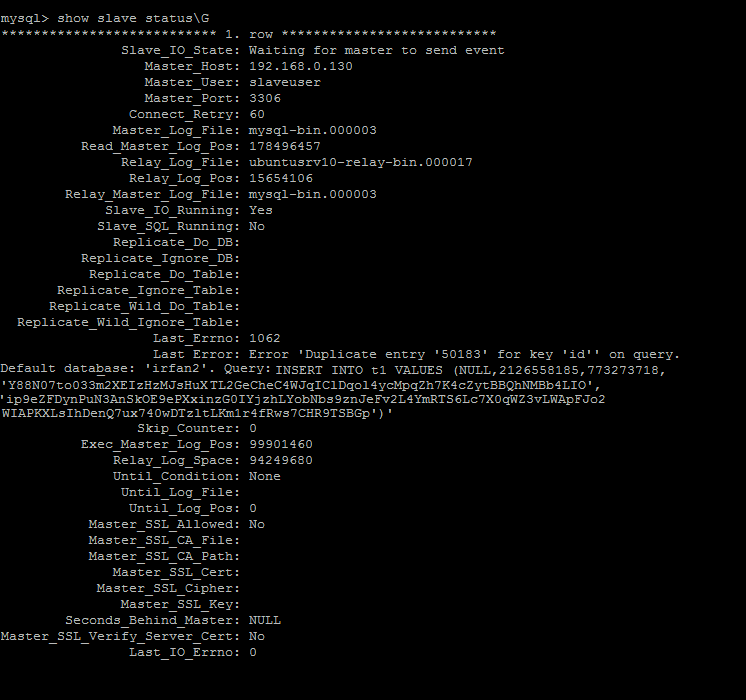
It’s broken, the Slave sql thread failed to start. Why ?
The problem would be when mysqld crashed on the slave, the transaction and update of the relay-log.info file was committed to the Slave relay log, which didn’t get updated with the latest info.
There are two causes of this problem.
1) If the slave sql_thread refuses to start because of a duplicate key error, the slave relay log will not get updated and it therefore contains old information even though the slave already played the event. You can inspect the master binary log and verify that problematic event already played to slave via SELECT query. One easy solution for this is to skip the event via SQL SLAVE SKIP COUNTER and resume replication – and to be on the safe side also use Percona Toolkit’s pt-table-checksum to check for data incompatibilities.
2) If the table doesn’t contain a primary key then the slave will run fine and will re-execute the already played event silently (as the slave process didn’t stop) and yields data inconsistencies between master and slave. Again this can be solved via pt-table-checksum tool or with manual intervention to verify whether or not the record has been duplicated.
This problem simply brings up data inconsistencies and delays in replication because of errors. This is where Percona Server’s crash-resistant replication feature comes into play, saving you from encountering this problem by enabling innodb_recovery_update_relay_log on the slave.
Let me illustrate this by example….
With Percona Server’s Crash-Resistant Replication:
First, you need to enable innodb_recovery_update_relay_log on the slave. Set it to innodb_recovery_update_relay_log=1 in my.cnf and restart mysql. This will verify whether it’s enabled or not.

This will also be written in the error log when innob_recovery_update_relay_log is enabled.
![]()
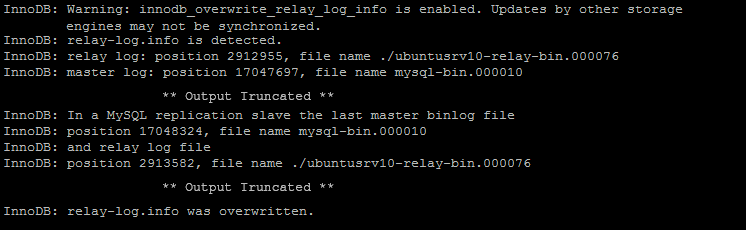
Now, let me re-run the same mysqlslap command that I executed earlier with the same concurrency. I’ll start the slave with –skip-slave-start to prevent the start of the slave on mysql startup and will then crash the slave once again to see the change in behavior. The result is that the relay log position has been overwritten to ‘17048324‘ from ‘17047697‘ so replication will resume from the correct position 17048324. This can also be verified from the mysql error log.
Let’s take a look at the slave status at this point…
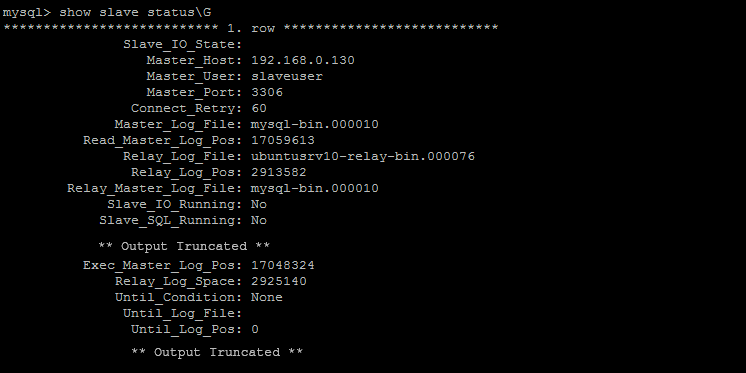
As you can see, the Exec_Master_Log_Pos has been updated to the correct position to resume replication i.e. 17048324. Further, as you can see in the error log, the binary log overwritten message is also there.
![]()
And if the slave relay-log.info already has the correct information and has been synchronized with the disk after the crash, this will also appear in the error log.
![]()
Conclusion:
Using Percona Server’s “crash-resistant replication” feature will result in avoiding replication errors. Using it will save you from hidden replication errors and thus ultimately saves you from data inconsistencies. Overall, this is a nice feature that prevents replication delays and slave-synchronization issues.
Resources
RELATED POSTS





Is it ok to use innodb_overwrite_relay_log_info in a master-master setup?
This is a nice features, but I wonder will this cause performance problem on slave? Because in theory if we are putting replication data into innodb log file transactionally (which I assume it is innodb log buffer is being used). In this case will there more flushing being done?
AFAIK, it can improve performance on the slave. With rpl_transaction_enabled from the Google/Facebook patches putting slave state into InnoDB means that fsync on commit is not needed by the slave SQL thread. Slave SQL thread state and InnoDB recover to the same point in time whether or not fsync is done. If a few commits are lost from InnoDB on the crash then they are also “lost” from the slave state and the slave SQL thread begins where it should begin.
And beware this bug: https://bugs.launchpad.net/percona-server/+bug/1092593
Run Percona 5.5.31 or greater.
Patryk,
It’s absolutely fine to use innodb_overwrite_relay_log_info in a master-master setup.
Hi.
relay-log-recovery not workig for me and mysql stop slave with error Last_Errno: 1032.
mysql> show global variables like ‘relay_log_recovery’;
+——————–+——-+
| Variable_name | Value |
+——————–+——-+
| relay_log_recovery | ON |
+——————–+——-+
1 row in set (0,00 sec)
What else can I do?