
In my previous rounds with DataWarehouse oriented engines I used single table without joins, and with small (as for DW) datasize (see https://www.percona.com/blog/2009/10/02/analyzing-air-traffic-performance-with-infobright-and-monetdb/, https://www.percona.com/blog/2009/10/26/air-traffic-queries-in-luciddb/, https://www.percona.com/blog/2009/11/02/air-traffic-queries-in-infinidb-early-alpha/). Addressing these issues, I took Star Schema Benchmark, which is TPC-H modification, and tried run queries against InfoBright, InfiniDB, LucidDB and MonetDB. I did not get results for MonetDB, will explain later why. Again primary goal for test was not to get just numbers, but understand specifics of each engine and their ability to handle amount of data and execute queries.
All details I have are available on our Wiki https://www.percona.com/docs/wiki/benchmark:ssb:start and the specification of benchmarks you can get there https://www.percona.com/docs/wiki/_media/benchmark:ssb:starschemab.pdf.
I generated data with scale factor = 1000, which gave me 610GB of data in raw format and loaded into each engine.
There difference in engines gets into play. While InfoBright and InfiniDB does not need indexes at all (you actually can’t create indexes here), they needed for LucidDB and MonetDB, and it changes load time and datasize after load significantly. The numbers
I put in results do not include indexing time, but it also should be considered.
And indexes are exactly reason why I could not get results for MonetDB, there I faced issue
I was not prepared for. MonetDB requires that index fits into memory during indexing procedure, and for 610GB the index may get to 120GB size, and I did not have that amount of memory ( the box is only 16GB of RAM). MonetDB experts recommended me to extended
swap partition to 128GB, but my partitions layout was not really prepared for, I just did not expect I need big swap partition.
Loading
So load time.
InfiniDB can really utilize all available cores/cpus in systems ( I run benchmark on 8 cores box), and it allowed to load data faster than other engines. Though LucidDB and MonetDB
are also have multi-thread loaders, only InfoBright ICE used single core.
InfiniDB: 24 010 sec
MonetDB: 42 608 sec (without indexes)
InfoBright: 51 779 sec
LucidDB: 140 736 sec (without indexes)
I should note that time to create indexes in LucidDB was also significant and exceeded loading time. Full report on indexes are available here https://www.percona.com/docs/wiki/benchmark:ssb:luciddb:start
Data size
Size after load is also interesting factor. InfoBright is traditionally good with compression,
though compression rate is less than in case with AirTraffic table. I was told this is because
lineorder table comes not in sorted order, which one would expect in real life. Actually
the same complain I heard from InfiniDB experts – if put lineorder data in sorted order, loading
time can decrease significantly.
Datasize after load:
InfoBright: 112G
LucidDB: 120GB (without indexes)
InfiniDB: 626GB
MonetDB: 650GB (without indexes)
Queries time
Now on queries time.
Full results you can find on page https://www.percona.com/docs/wiki/benchmark:ssb:start,
and graph is below. There couple comments from me.
InfoBright was fully 1 CPU bound during all queries. I think the problem
that engine can use only single cpu/core is getting significant limitation
for them. For query 3.1 I got the surprising result, after 36h of work I got
error that query can’t be resolved by InfoBright optimizer and I need
to enable MySQL optimizer.
InfiniDB is otherwise was IO-bound, and processed data fully utilizing
sequential reads and reading data with speed 120MB/s. I think it allowed
InfiniDB to get the best time in the most queries.
LucidDB on this stage is also can utilize only singe thread with results sometime better,
sometime worse than InfoBright.
Results:
| Query | InfoBright | InfiniDB | LucidDB |
|---|---|---|---|
| Q1.1 | 48 min 21.67 sec (2901.67 sec) | 24 min 26.05 sec (1466.05 sec) | 3503.792 sec |
| Q1.2 | 44 min 55.37 sec (2695.37 sec) | 24 min 25.83 sec (1465.83 sec) | 2889.903 sec |
| Q1.3 | 45 min 53.49 sec (2753.49 sec) | 24 min 27.25 sec (1467.25 sec) | 2763.464 sec |
| Q2.1 | 1 hour 54 min 27.74 sec (6867.74) | 19 min 44.35 sec (1184.35 sec) | 9694.534 sec |
| Q2.2 | 1 hour 13 min 33.15 sec (4413.15) | 19 min 49.56 sec (1189.56 sec) | 9399.965 sec |
| Q2.3 | 1 hour 8 min 23.41 sec (4103.41) | 19 min 52.27 sec (1192.25 sec) | 8875.349 sec |
| Q3.1 | NA | 19 min 11.23 sec (1151.23 sec) | 16376.93 sec |
| Q3.2 | 3 hours 30 min 17.64 sec (12617.64 sec) | 19 min 28.55 sec (1168.55 sec) | 5560.977 sec |
| Q3.3 | 2 hours 58 min 18.87 sec (10698.87 sec) | 19 min 58.29 sec (1198.29 sec) | 2517.621 sec |
| Q3.4 | 1 hour 41 min 41.29 sec (6101.29 sec) | 12 min 57.96 sec (777.96 sec) | 686.202 sec |
| Q4.1 | 8 hours 53 min 52.55 sec (32032.55 sec) | 32 min 57.49 sec (1977.49 sec ) | 19843.213 sec |
| Q4.2 | 5 hours 38 min 7.60 sec / 5 hours 36 min 35.69 sec (20195.69 sec) | 33 min 35.45 sec (2015.45 sec) | 15292.648 sec |
| Q4.3 | 12 hours 58 min 4.27 sec (46684.27 sec) | 33 min 47.32 sec (2027.32 sec) | 7241.791 sec |
Graph with results (time in sec, less time is better)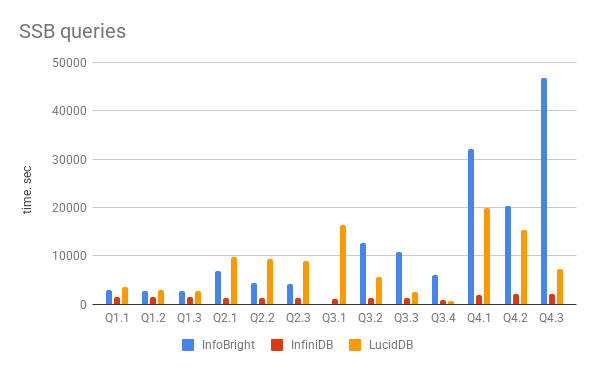
Conclusions





MyIsam planned ?
I second that, would love to see how the common open source DBs like MyIsam (PostgreSQL as well?) are performing
It’ll probably give readers a better understanding of what’s a “Good” result
Also, worth noting InfoBright is a commercial product with a borderline unusable community edition.
MySQL and PostgreSQL comparison is rather pointless, see e.g. http://monetdb.cwi.nl/SQL/Benchmark/TPCH/index.html Reason for not using MySQL in SF20 is that loading took more than 10 hours. PG also gave many erroneous results. I did a comparison a couple of years ago with a very small (2GB) dataset, results can be seen here: http://www.tholis.com/news/open-source-data-warehousing/ As can be seen here too, row based engines are no match for column based db’s. Besides, all these results are artificial and cannot be used to make general statements like ‘product A is X times faster than product B’. All depends on data characteristics & volume, available hardware and query workload.
‘@Jos van Dongen: wrt to the erroneus results of PostgreSQL It should be mentioned that those were caused by a documented restriction in PostgreSQL wrt. to parsing SQL standard style intervals. This has since been fixed/improved in 8.4 (also the MonetDB comparison used 8.2 at a time when 8.3 was available for a while – see the PostgreSQL mailinglists for discussions of that “benchmark”). However I agree that this kind of benchmark is really geared towards column storage engines and not more tradition OLTP style row based ones.
I really do not want to test MyISAM in this benchmark. It may be OK to load data in, but queries
will take hours, even days to execute on 1000 scale factor.
WRT to Eagle’s mention of Infobright, I must first state that I am an Infobright employee. In fact, I am the Director of Technical Sales Consulting.
Yes, Infobright offers both a community and commercial edition of the same code line. And it is also true that InfiniDB is a community edition of the commercial product Calpont. And there is a commercial offering of LucidDB known as DynamoDB. The same goes for MonetDB, too.
Infobright’s current differentiation between the fully-functional commercial product and that of the community edition – besides the business benefits of Support and Indemnification – is the exclusion of full DML including INSERT, UPDATE and DELETE. Instead, it is offered as a ‘LOAD and READ’ analytical tool. Production environments requiring full DML will often also require Support so the commercial edition then begins to make sense.
At least that’s what our community edition users tell us.
Thanks for keeping us in mind and continue to keep an eye on ICE as it expands its capabilities.
Best wishes,
David Lutz
To stick with David Lutzs good manners and example, I’ll also start by noting myself as an employee of DynamoBI (sponsors of LucidDB).
Vadim – thanks again for doing the benchmarks. They help everyone (customers, consultants, vendors) get an independent assessment of performance under certain workloads.
Vadim, you’ll always hear vendors complaining about how artificial/synthetic benchmarks are. They have to be a little bit, so they can be leveraged across multiple vendors globablly. For instance, we could simply say that the OTP, with lack of joins and heavy focus on counts() instead of selectivity in joins are “synthetic.” They’re not, just one use case. Likewise with SSB and TPCH.
I think OTP – simple flat structure with SIMPLE metrics. Tests aggs, w/o joins on large datasets.
I think SSB – traditional star schema. Tests aggs, smart selectivity, joins, and aggs.
I think TPCH – traditional relational BI queries. Tests multi joins (keys, tables), selectivity, variety of sql syntax, aggs, etc.
In terms of SQL complexity it goes OTP / SSB / TPCH. I don’t see any reason to not do a few flavors! What matters most is the customer experience; all analytic databases have their strengths. We believe DynamoDB/LucidDB, as a fully featured, purpose built BI database with numerous BI extensions (read consistent reporting, mondrian integrations, 100s of BI focused functions, ANSI SQL DML support incl MERGE) is a great fit for people who want speed but also need flexibility and features that support their BI implementation.
re: MyISAM/Postgres. I agree with Vadim, it would simply take too many hours to run through those systems. LucidDB has never lost a comparison with either by less than 3x faster, usually 4-10x (that I’m aware of).
Think you can get Kickfire to lend you a box to run the SSB at SF1000 on?
Did you use more than one node for InfiniDB or just one? I’d love to see if performance gets linearly better by adding a second node. The multithreading capabilities of infinidb are impressive, as it is hard to parallelize a single SQL query. AFAIK only Kickfire and InfiniDB are capable of this.
That is, those are the only MySQL based products capable of it.
For those who wonder about MyISAM performance on these benchmarks, I would point you to our benchmarks on TCP-H with MyISAM. It’s not the same benchmark, but it shows how poorly it performs.
Justin,
I’d love to run this or any other benchmarks on KickFire, but I have no access to hardware.
I used one node (server) for InfiniDB, and I am not sure if community edition will allow me
to use multi-node capability.
You forgot to mention GreenPlum, as I understand this product also allow multi-core / multi-node processing.
Thanks Vadim!
That MonetDB limitation with indices having to fit in memory while being built is a problem. Doesn’t that make MonetDB nearly useless for anyone with non-trivial data set?
Still, I’d love to see how MonetDB query execution compares to others.
Here’s some followup commentary from yours truly:
http://thinkwaitfast.blogspot.com/2010/01/spin-cycle.html
Obligatory disclaimer: I’m the founder for the LucidDB project.
Dear Vadim,
A quick correction to the conclusions.
– MonetDB does *not* limit (hash) index sizes to the available memory. It will allocate memory-mapped files upon need to store them. Indices live as long as needed and their existence are fully under control of the kernel.
– MonetDB indeed uses more swap-space then other systems do. A rule of thumb is to have a swap-space at least twice the amount of RAM (good server policy). For larger databases, the current implementation requires even more depending on the query footprint. This amounts to moving (database) temporary workspace (/tmp space?) to the swap partition.
– MonetDB enforces the integrity constraints over the SSB ! This is necessity for all systems to check after loading. In MonetDB this involves an expensive join, which unfortunately is currently a hash-based implementation. It is know that hash-based joins for out-of-memory situations cause excessive IO.
It is unclear from your report if you have instructed the other systems to explicitly check the constraints. For example, to add an ALTER statement after a brute force quick load. A basic assumption for any database implementation, also for BI, is to ensure that all constraints holds.
With the quickly growing community of people using MonetDB for larger databases, we have addressed several of the issues in the upcoming release (Feb 2010). In particular, it will be more disk space conservative, outer-memory-joins are based on sort-merge, increased intra-query parallelism, …
Looking forward to the next series of challenges.
regards, Martin Kersten
(MonetDB architect)
Martin,
Can’t you implement hash index build based on tmp disk partition ?
I fairly can’t recall any servers setup that has 64-128GB of RAM with 128-256GB of SWAP partition.
As for constraint I think InfoBright and InfiniDB do not support constraint checks in the current implementations, so there is no way to force them to check it. I understand it places them in better performance position comparing with LucidDB and MonetDB, but I’d propose to have it as option for MonetDB which you can turn off.
Thank you for comment,
Vadim
Martin, ‘increased intra-query parallelism’ ? Is there any now? My understanding was that MonetDB currently doesn’t offer parallelism.
Dear Baron,
MonetDB already for over two years uses a dataflow optimizer, which uses all the cores available to speedup processing. This optimizers is enabled by default.
In the upcoming release, the scope of this optimizer has been expanded.
Dear Vadim,
There are several ways to deal with indices and we expand its scope continuously.
Likewise, we explore all paths to deal with memory-mapped files and virtual memory (swap space).
Stride-by-stride our already great performance improves (see your previous benchmark),
only partly hindered by the OS implementation quirks and our understanding of them.
All our machines (both PC and Servers) are luxuriously equipped with swap-space
and the factor two is what our Linux system administrators consider the minimum.
Not only for MonetDB, but to support all kind of applications, e.g. Matlab.
In my opionion, ignoring constraint checking in a (BI) database system should lead
to a big negative functional mark. You may not assume that the files provided through
a copy-into command together form a consistent database.
A side-effect of constraint checking in MonetDB is the automatic construction of join-indices,
which would speed up large numbers of join queries. Other systems then would require the DBA
to step in and create the proper indices, or they will encounter serious performance problems.
regards, Martin
Vadim/All
Regarding Greenplum, I would love to see their performance in the above and other tests. I’ve tried to install their single node edition twice on two virgin machines with all the right prereq’s and keep getting errors. My requests for assistance on their forums haven’t produced any help, so it’s been rather frustrating. If anyone does get GP working, please post the results.
Regards,
Robin
Robin,
I actually was able to install GreenPlum on box similar that I used in SSB test and I set 8 running nodes ( 1 node/cpu).
It was not fully simple, but I have not had serious problems either. GreenPlum QuickStart guide is not very helpful though.
I will try to install GreenPlum on another box for new benchmark and I will document my steps.
Vadim – great; looking forward to any test results and docs you produce. Thanks!
–Robin
Eagle – was wondering why you would consider our Infobright community edition as you put it “borderline unusable community edition” as we have many professionals using Infobright Community Edition in production environment including one very large online media company. These community users are very satisfied with the product, so much so that they chose to stick with the use of the free community edition of Infobright.
I am also employed by Infobright for full disclosure.
Hi Bob,
The idion “One man’s trash is another man’s treasure.” comes to mind. ICE has A LOT of bugs. Every time I’ve tried to use it I’ve encountered oddities. I’m sure with a lot of work and testing, you could get ICE going in production, but I would be very wary unless you have a very regimented testing system where you test every query extensively before it hits production. This greatly limits the database for adhoc querying.
It is difficult to use a product which can’t ALWAYS execute a SQL statement. A relational database is supposed to be able to answer every well-formed relational query handed to it. Until ICE can execute a vast amount of SQL reliably, I won’t consider it read for anything but pet project use.
What is stupefying is that the only difference between queries 3.{1,2,3,4} are the predicates.
Justin,
I’m not sure what you mean by A LOT of bugs because thats a very broad and general statement. It’s like saying “Windows has bugs”. There is no such thing as a bug free reasonable sized software product that I’m aware of. Have you ever googled any of the databases in the market for bugs?
As a professional software company we track bugs in our products very closely and tackle as many as possible with our resources in each release. I’m not sure what release you are speaking about and I’m always weary of someone that claims “Lot of bugs”. The credibility isn’t there for me. Sorry.
We also rely on a strong feedback loop from our customers and you will see that as we interact with the community users on the forums where we deliver great levels of help to the community. Good luck in your efforts, I wish you all the best.
Bob
By the way, have enjoyed the reading the observations on this thread. Benchmarking has always been one of those topics that generate much discussion as there are so many ways to attempt to test performance characteristics of a database using a wide variety of approaches. I’m a fan of real world customer benchmarks as its not a one size fits all scenario. Having worked at a number of database companies in my career, its always great to hear the debates around this topic.
First of all, thank you Vadim for your efforts here.
The SSB data set does have some arbitrary components not yet cleaned up from it’s TPC-H legacy, including the randomized data generation. But it also appears to offer some nice instrumentation based on the query grouping. There is a Query Complexity Dimension with the number of tables in the join going up as you progress from Q1 series to Q4 series. In addition there is an Aggregation/Join Cardinality Dimension, within each query series the predicates eliminate more rows as they progress from Q*.1 to Q*.3 or (.4).
So, you could chart the queries like this, grouping by Complexity and Aggregation/Join Cardinality, where the values are rough estimates of rows being aggregated (from 480 million rows down to 1200) .
Extra-Large Large Medium Small Needle
Q1 series-2 tables 120,320,856 4,010,695 1,002,674
Q2 series-4 tables 48,000,000 9,600,000 1,200,000
Q3 series-4 tables 216,000,000 8,640,000 86,400 1,200
Q4 series-5 tables 480,000,000 144,000,000 2,880,000
To understand the Aggregation/Join Cardinality Dimension, you can look at a given series and evaluate what happens as the selectivity changes. For the Q1 series, the costs for additional rows can be discerned from the differences in time to deal with 1 million vs. 120 million rows.
To understand the Query Complexity Dimension, you could find queries with similar rows being joined and aggregated and compare those. For example Q1.2, Q2.2, Q3.2, and Q4.3 all aggregate between about 2.5 and 10 million rows.
For InfiniDB, the results are apparently flat across the Aggregation/Join Cardinality Dimension, with about a 4% variation within a series, (except Q3.4 which touches far fewer blocks). This is actually a function of InfiniDB being I/O bound for this data set on this server, with idle cpu much of the time. When run here at Calpont with the same queries/data/cores but faster disk we get 474.41, 456.97, 449.57 seconds for Q1.1, Q1.2, Q1.3 indicating something like 25 seconds incremental time associated with joining/aggregating 120 million rows.
For InfiniDB, the Query Complexity shows a general upward trend for Q1.2, Q2.2, Q3.2, Q4.3 of 1465.83, 1189.56, 1168.55, 2027.32, with Q1.2 being a clear outlier. Some other difference in that query appears to be influencing the timing.
Overall, the conclusion should be that InfiniDB is clearly capable of dealing with these sort of cardinalities and query complexity in a very stable and predicable manner. (Yes, I am an InfiniDB employee)
I would also encourage everyone to take a look at the potential uplift with more I/O and some basic query tuning: (for example query 1.2 in 7.91 seconds instead of 1465 seconds).
http://infinidb.org/infinidb-blog/mysql-parallel-query-processing-of-ssb-queries-via-infinidb-.html
Let us help you put your data to work.
Hi Bob. I know a lot about database bugs. I have a number of open MySQL bug reports, and I even contributed a fix to a serious replication bug in MySQL too. I worked very closely with the QA department at Kickfire while employed there, identifying defects, testing functionality, performance and assisting with customer POCs.
As part of Proven Scaling, I was involved with the testing effort at SolidDB.
I tend to assume that most database products have fairly good QA departments that are good at finding and reporting bugs. This implies that there should be a lot of bugs filed on a database product and a large number fixed in any given release. Infobright does a good job of reporting to changes in the release notes, including bug numbers. I applaud this, but I’m sure you understand that this is somewhat of a dual edged sword.
I see a lot of very serious bugs fixed in each release change list. Given that every database release includes many bug fixes, I tend to look at the number of bugs fixed that have the “highest severity” of the bugs listed as fixed in the change list. Then I try to determine how many of the bugs would have seriously hurt my production environment had I hit them? I also try to determine how likely it would be that I would have hit a bug. Once a release has very few serious issues, and the serious issues which were encountered would not likely affect my environment, then I’d consider starting to test that database product for eventual release into my production environment.
To be clear, I would not go out and buy Infobright, Kickfire, InfiniDB, Oracle or any other database product unless I was at least reasonably sure that it was relatively free of severe bugs which would affect my environment. I’d want to test that database as extensively as possible with my application before I rolled it to production. I don’t think I’m an unusual DBA in this respect.
Robin,
I installed GreenPlum on another testing host,
it worked more or less fine for me.
My steps are there
https://www.percona.com/docs/wiki/benchmark:wikistat:greenplum#installation_procedure
Vadim – thanks, I will follow your instructions and give it another try soon. Much appreciated!
–Robin
Otis,
Please see comment #14 from Martin Kersten, MonetDB architect.
You may also be interested in the numbers we obtained from a commercial row store, which we had set up by a DBA who makes his living tuning the product. This data is likewise 3 years old, but involved the same hardware above (with the addition of a SAN to support the shared disk architecture).
Q1.1(ms) 23107.5
Q1.2(ms) 22870
Q1.3(ms) 22867.5
Q2.1(ms) 22937.5
Q2.2(ms) 20832.5
Q2.3(ms) 19282.5
Q3.1(ms) 78330
Q3.2(ms) 4805
Q3.3(ms) 4742.5
Q3.4(ms) 2115
Q4.1(ms) 34187.5
Q4.2(ms) 9057.5
Q4.3(ms) 657.5
Load time was 10 hours. Space was 479G.
Given 889G and 4-5 hours to build 3 indexed MVs to optimize the queries, the query times were:
Q1.1(ms) 4710
Q1.2(ms) 4180
Q1.3(ms) 2110
Q2.1(ms) 25280
Q2.2(ms) 21150
Q2.3(ms) 2230
Q3.1(ms) 19150
Q3.2(ms) 2700
Q3.3(ms) 1720
Q3.4(ms) 430
Q4.1(ms) 11770
Q4.2(ms) 9280
Q4.3(ms) 670
Vladim,
First of all, thank you for this very interesting benchmark.
I am currently looking for a DBMS solution for my company.
I have some questions about your benchmak:
– I’ve read that all column oriented databases have a good compression rate (around 1:10). Then why the datasize of InfiniDB and MonetDB is pretty close of the original datasize?
– Is a product more secure than the others?
– Which product do you prefer?
If you have some advices or tips in order to help me in my researsh/choice, I would be really grateful.
Thank you,
Matthieu
Matthieu,
1) InfiniDB and MonetDB do not use compression, that why size is equal to origal dataset
2) Sorry, what do you mean by secure ?
3) There is no preference for me.
That’s why I run these benchmarks to understand pro- anc cons- of each product, also
to understand what workload is suitable for what product.
I like that InfiniDB and MontetDB can use all CPU core to execute query,
but as you see they do not have compression. LucidDB id slower, but it has most flexible ETL features.
So it is up to you to decide what you need in each case.
By the way, I wonder if anyone has realized that SF-1000 data generated by SSB dbgen is broken. The keys in lineorder table are not unique (see immediately repeating keys around line 32)
There seem to be two bugs in dbgen (at least the version I have):
– it doesn’t work with SF >= 1000
– the warning that it doesn’t work only pops up for SF > 1000 (hence, there’s no warning for SF-1000)
Not sure how it influences the results, but it also means no DBMS that is checking constraints should load this dataset.
Interestingly, it does seem to be fine on SF-999.
Vadim,
I’m trying to make some benchmarks on different products.
I’ve started with infobright but I don’t know where I can see the size of the database (in order to check the compression).
I have watched in /usr/local/infobright/data, because there are folders corresponding to the tables I’ve made.
But the size of these folders doesn’t increase when I insert a lot of datas!
Where do you check the datasize on each product?
Thank you for your help,
Matthieu
Matthieu,
I just use “du -sh *” on datadir, that’s all.
Vadim/all,
We have some metrics from running a SF-10,000 to share for those interested. Notes on the paramters tweaked from the defaults are included as well. The dbgen issue with keys being re-used referenced by Marcin Z does show up at this scale.
The basic scenario; load a SF-10,000 and a SF-1,000 (60 billion and 6 billion facts respectively) into one InfiniDB instance on a 6 sever (8 cores, 16GB) stack attached to 4 FC attached LSI trays. Then run the queries in a stream against each and compare the relative time against each other.
Overall, the results were as expected; the overall processing behavior didn’t change as we scaled the fact table. Anyway, further details are available at: http://www.infinidb.org/myblog-admin/mysql-parallel-query-processing-of-60-billion-rows-via-infinidb.html .
Thanks – Jim Tommaney
Vadim/all,
I was taking a look at SSB and then i was thinking if is possible to denormalize all tables from the SSB?
So database size will increase a lot but potencially the performance will grow up. Is that right? Is It possible?
Thanks and sorry for my poor englise
Pedro
Pedro,
Speaking for LucidDB it’s unlikely you’d see a large increase if you denormalized to a flat table. Since we store column by column you’d see some change in size but it wouldn’t be substantial.
Nicholas/all
I saw that LucidDB and InfoBright have a high compression rate. So if we make the SSB denormalization then probabilly the queries perfomance will grow up. Is that right?
Does anyone already made this kind of stuff?
Thanks
In many products, it is possible to change the physical schema without changing the logical schema. This can improve the performance of queries with dimension table predicates, especially when data comes from disk, because the matching rows are easy to identify and are collocated. Full denormalization doesn’t help as much; the joins to retrieve dimension values are fast because the dimension tables are relatively small.
SSB does not prohibit using materialized views with query re-write to achieve performance, but you have to account for this in the loading time according to the rules.
So for example, on Oracle you could build materialized views to answer the queries, and allow Oracle to rewrite the SSB queries transparently to use your views, but this wouldn’t gain you much since each SSB query is executed only once.
A database engine might build a materialized view (or a specialized index) automatically behind the scenes on foreign key constraint definitions in order to improve the performance of the join. I believe that LucidDB builds such a structure on FK constraints, as does ScaleDB, Kickfire, and other database engines. Other engines focus on distributed hash-joins instead of materialization. Ideally, such an engine will have a high-performance way of building such a structure.
As I recall, the SSB benchmark was designed with a specialized type of DB2 materialized cube in mind, but I’d have to read the paper again to verify that.
Pedro,
Also, the SSB schema is based on the TPC-H schema, which is denormalized.
Hi Vadim,
I am a student and I must compare the databases “infoBright”, “MonetDB” and “InfiniDB” as part of a project. My question is, how can I make this comparison.
Thanks
Thanks for the real-world case study. It is very insightful! I am wondering where MongoDB fits into this picture?
‘@Michael Rikmas Fuery
MongoDB is even less like a column store than a row store is because there are no joins and all data must be stored in one place (without said joins).
Column Store = Each column is a file that can be scanned (oversimplification). Joins can be used to put data together.
Row Store = Each column is part of a file containing all columns (again, oversimplification). Joins can be used to put data together.
MongoDB = There is only one table period, and all columns and joins must be in one file unless you do a fake-join in your application.
For most purposes, column stores behave like row stores. Joins work, etc. Some of the performance characteristics will be different, though. Clearly if you’re using/selecting most columns, they won’t help much. They might even hurt! Which columns you filter by or select in a column store will make a big difference.
What you get out of MongoDB is map-reduce, and a natural ability to use a non-declarative (i.e. SQL) language that can be trivially paralellized without any planner magic. In other words, even if the physical layout sucks, you can throw hardware at it and expect that to help.
Since it’s been over 2 years since the benchmarks at the top of the thread have been produced, are the plans to conduct them again based on newer/current versions of these products?
I suspect the landscape has changed significantly to possibly allow other products to be considers.
hello why i spent so much more time when load data into infiniDB and lucidDB than into infobright?
dat ‘bechmark’ tho